Your test suite is lying to you. Not through any fault of its own, and not because you wrote bad tests. It is lying because the class of bugs that kills concurrent systems is fundamentally untestable by conventional means. Race conditions, deadlocks, and memory ordering violations do not live in your logic. They live in the gaps between your logic, in the microseconds where two threads reach for the same resource and the outcome depends on a scheduler decision made by the operating system, influenced by CPU load, interrupt timing, and factors no test harness controls.
This is not a niche concern for systems programmers writing kernel code. Every web service handling concurrent requests, every mobile app with a background sync thread, every database driver managing a connection pool is threading this needle constantly. The industry has largely decided to ignore the problem. That is a mistake.
The Test Is a Single Timeline. Your Program Is Many.
When you write a unit test, you are describing one execution path. Input goes in, output comes out, you assert the result. Deterministic, reproducible, useful. But a concurrent program is not one path. It is a combinatorial explosion of possible interleavings, and most testing infrastructure only ever walks one of them.
Consider two threads incrementing a shared counter without synchronization. In a test environment, they likely finish in the same order every single run, because the test machine is unloaded, the threads are short-lived, and the scheduler is consistent. Ship that to production on a busy server and you will eventually lose increments. The bug was always there. The test simply never found the interleaving that exposed it.
This is the core problem. Testing proves the absence of bugs in the paths you checked. Concurrency multiplies the paths faster than you can check them. The bug that disappears when you add logging is often exactly this phenomenon: the logging call adds enough latency to change the scheduling outcome, and suddenly the race condition stops manifesting.
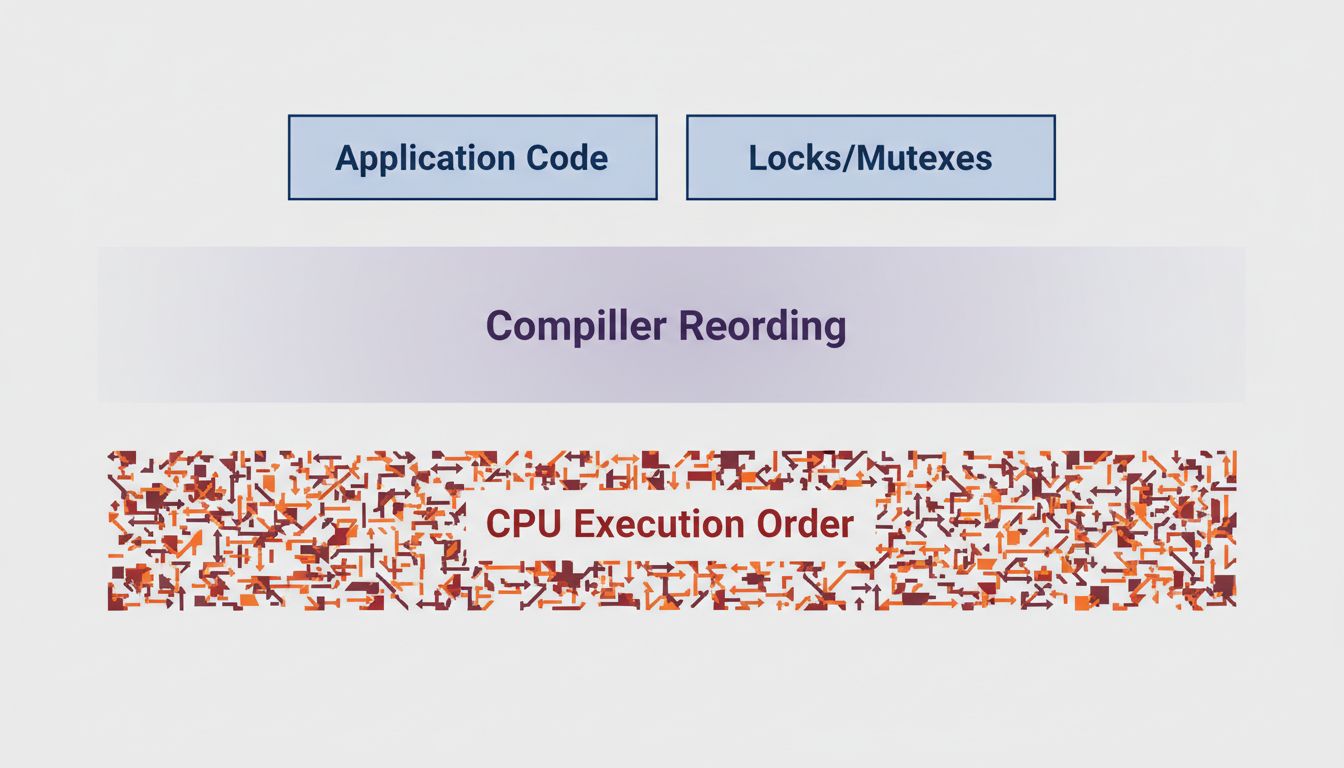
Locks Are a Promise You Can Break Without Knowing It
The standard answer to concurrency problems is synchronization: mutexes, semaphores, monitors. Wrap the shared state, serialize access, done. This works, but it introduces its own failure modes that are just as invisible to tests.
Deadlock requires two threads, two locks, and the wrong acquisition order. Each thread holds one lock and waits for the other. The program hangs. In a test, the two threads rarely happen to acquire locks in the deadlocking order under controlled conditions. In production, under load, with slightly different timing, they do. The Therac-25 radiation therapy machine, responsible for several patient deaths in the 1980s, involved race conditions in concurrent software that years of prior use had never surfaced. The system worked correctly in most interleavings. The fatal ones required specific timing that normal operation rarely produced.
Livelocks are subtler: threads are not blocked but are continuously yielding to each other, doing work that goes nowhere. Priority inversion, where a high-priority thread is starved because a low-priority thread holds a lock it needs, has famously halted spacecraft. The Mars Pathfinder mission in 1997 experienced repeated system resets in flight due to a priority inversion bug in its VxWorks scheduler. It had passed all pre-launch testing.
Memory Ordering Is the Layer Below Your Abstractions
Even if you get locking right, modern CPUs and compilers operate below the level where most developers think. Out-of-order execution and compiler reordering mean that the sequence of memory operations your program appears to perform is not necessarily the sequence that executes. On x86 this is largely managed for you. On ARM, which now runs a significant fraction of the world’s servers (including Amazon’s Graviton fleet), the memory model is weaker and more explicit synchronization is required.
Java’s volatile keyword, C++’s std::atomic, and Rust’s ordering parameters on atomic operations exist because the hardware does not guarantee what programmers assume. Incorrect usage is silent. The code compiles, the tests pass, and in production on a multi-core ARM machine under load, a thread reads a stale value because the write from another core has not propagated. No crash, no exception, just wrong behavior that appears sporadically and vanishes under inspection.
The Counterargument
The reasonable objection here is that tooling has improved substantially. ThreadSanitizer, Helgrind, and similar dynamic analysis tools can detect data races at runtime. Formal verification tools like TLA+ and Alloy let you model concurrent systems and check invariants across all possible interleavings. Rust’s ownership model prevents entire categories of data races at compile time.
All of this is true. These tools matter and more teams should use them. But ThreadSanitizer only finds races in the code paths it actually exercises during a run, which returns you to the coverage problem. TLA+ requires modeling your system separately from implementing it, and the model can diverge from the code. Rust prevents data races but not deadlocks, livelocks, or logical races at higher abstraction levels. The tools reduce the problem. They do not eliminate it.
The deeper issue is not tooling availability but industry norms. Most teams do not run dynamic analysis tools in CI. Most developers have not used TLA+. Most code reviews do not scrutinize concurrency assumptions. The tools exist; the culture of using them does not.
The Uncomfortable Conclusion
Concurrent programming is qualitatively harder than sequential programming, and the software industry has not fully reckoned with this. We have built confidence in our test suites and our code review practices that is well-founded for sequential logic and almost irrelevant for concurrent behavior. The bugs that will take down your service at 2 a.m. are not in your business logic. They are in the space between your threads, in the timings your tests never produced, in the memory orderings your mental model assumes away.
The right response is not despair. It is honesty: concurrent code requires different validation methods, not more of the same. That means reaching for static analysis, running ThreadSanitizer against realistic workloads, learning enough formal methods to reason about your critical sections, and, where possible, designing systems that minimize shared mutable state rather than managing it. The problem will not be tested away. It has to be reasoned away.