
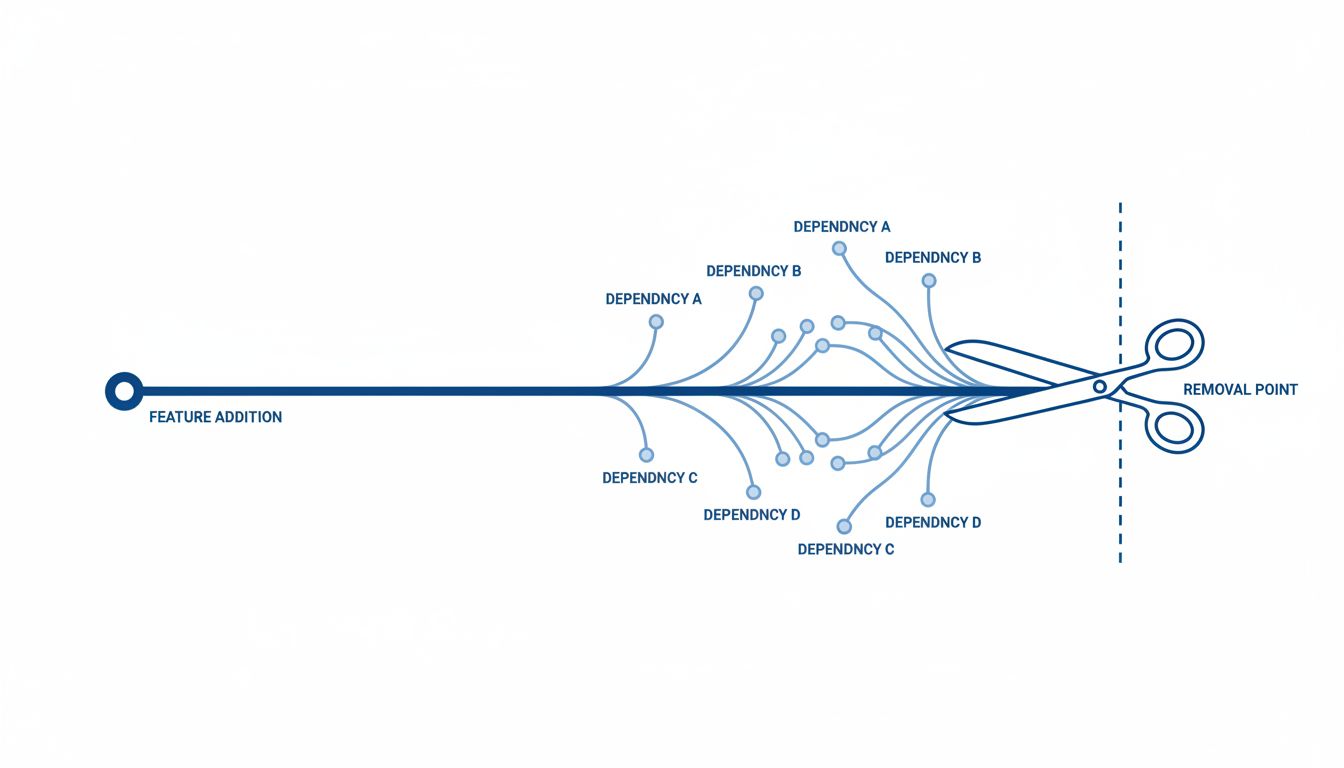
The simple version
Building a feature creates one kind of work. Deleting one creates three: finding everyone who depends on it, managing their anger, and untangling the code that grew around it over years.
Why this surprises people
Software feels reversible. You write code, you can delete it. Products ship features, products can pull them. The mental model most people carry is that creation and deletion are roughly symmetric operations, just running in opposite directions.
They are not. A team of five engineers can ship a feature in two weeks. Removing that same feature, if it has been live for two or more years, can require a year of deprecation notices, a dedicated migration path for affected users, changes to internal systems that silently started depending on it, and a support backlog that will outlast the feature itself.
The asymmetry is not about effort or complexity in isolation. It is about the difference between a controlled act and an uncontrolled one. You control when you build something. Once it is live, you do not control who starts using it.
The dependency problem
Every feature, the moment it ships, begins accumulating dependencies. Some of these are visible: other features in your own product that reference it, help documentation that explains it, marketing copy that advertises it. These are manageable.
The invisible ones are the problem. A company’s API is the clearest example. When you expose a feature through an API, developers at other companies write code against it. They build businesses on top of it. They do not tell you. They do not ask permission. By the time you decide the feature was a mistake, hundreds of integrations may exist that you cannot see from the inside.
This is why deleting a column from a live database can require hours of careful orchestration even when it looks trivial. The column might be gone from your schema, but queries touching it still live in application code, in third-party integrations, in jobs running on schedules no one has looked at in two years. The visible deletion is fast. The invisible cleanup is what takes time.
Google has dealt with this repeatedly at scale. The company’s policy on API deprecation involves formal multi-year timelines, public notice requirements, and migration tooling, precisely because the cost of a surprise removal is paid almost entirely by developers outside Google’s control. When Google shut down its original Maps API in 2018, sites that had embedded maps for a decade simply broke. The feature had been free infrastructure for long enough that removing it felt, to many users, like taking something that was rightfully theirs.
The psychological problem
This is where it gets counterintuitive. Deletion is harder than creation partly because of how humans respond to loss, and this matters for product decisions, not just user psychology.
Behavioral economists have measured the asymmetry: losses tend to feel roughly twice as significant as equivalent gains. A user who loses a feature they used monthly will generate more friction, more support tickets, and more vocal complaints than a new user who gains a feature they had not known to want. Product teams feel this pressure acutely. The loudest voices in any deprecation decision are almost always the people opposing it.
This dynamic pushes teams toward a particular form of cowardice. Instead of removing a feature, they stop investing in it. They leave it in place, untouched, marked internally as “legacy” but never actually gone. Over time the codebase fills up with these half-alive features. They slow down every engineer who has to navigate around them. They generate occasional support requests from users who somehow still find them. They create security surface area that no one is maintaining.
The feature graveyard is not a metaphor. It is a real cost that compounds. Every feature you do not delete makes the next deletion harder, because the codebase it sits in grows more tangled and the organizational habit of removing things grows weaker.
The organizational problem
Creating a feature has a clear owner. Someone championed it, someone built it, someone shipped it. Deleting a feature often has no clear owner, or worse, it has a reluctant one: whoever is currently responsible for the code it lives in.
The incentive structure does not help. Engineers are typically rewarded for shipping things. Removing a feature visibly benefits future engineers who have less code to maintain, but those benefits are diffuse and delayed. The costs of deletion, in user complaints and migration work and cross-team coordination, land immediately on the person doing it.
This is why deletion tends to require explicit top-down prioritization rather than organic emergence. Companies that do it well, like Basecamp, which has written publicly about deliberately limiting their feature set, treat removal as a product discipline equal in standing to addition. They assign it the same review processes, the same measurement criteria, the same expectations of follow-through. Most companies do not do this. Most companies treat addition as strategy and deletion as damage control.
What good removal actually looks like
The teams that handle deletion well tend to share a few practices.
They measure feature usage continuously and draw a line: anything below a usage threshold after a defined period is a candidate for removal, not for investment. This removes the emotional component from the initial decision.
They announce removal early and often. Not as a courtesy but as a forcing function: announcements generate the list of dependent users that internal data cannot produce. If your deprecation notice generates ten angry emails from enterprise customers who built workflows around a feature, you have just learned something you could not have known otherwise, and you have learned it early enough to do something about it.
They scope the migration cost before the decision is final. The question is not just “should we remove this” but “what does it cost to remove this safely,” and that cost has to be weighed against the ongoing cost of keeping it.
The fundamental insight is that a feature is not just the code that implements it. It is the code, plus the user behavior that formed around it, plus the downstream systems that incorporated it, plus the organizational knowledge about what it was supposed to do. Deleting the code is the easy part. The hard part was always everything else.
Building is additive and mostly local. Deletion is subtractive and almost always global. That asymmetry does not go away with better tooling or better processes. It is structural. The teams that manage it best are the ones who accept it as a permanent condition of making software and design their practices accordingly.





