
The Bug You Can’t Reproduce Is the Most Important One
You’ve seen this before. Something breaks in production. You pull the logs, you set up a local environment, you add some print statements, and the bug refuses to appear. The code works fine. Tests pass. CI is green. And yet, a real user hit a real failure.
The instinct is to treat this as bad luck, or a fluke of timing, or an infrastructure quirk. Sometimes it is. But when production-only bugs appear with any regularity, they’re not bad luck. They’re feedback. Your test suite has a systematic blind spot, and the bug just found it.
Understanding what kind of blind spot requires looking at the structure of how tests are typically written, and what they implicitly assume about the world.
What Tests Actually Model
A unit test is a model of your code’s behavior. Like all models, it simplifies. It removes dependencies, controls inputs, and eliminates time. You mock the database. You freeze the clock. You pass in clean, predictable data. The test is deterministic because you made it deterministic, and that’s usually the right tradeoff for fast, reliable feedback during development.
The problem is that production is none of those things. Production has a real database with years of accumulated data in shapes you didn’t anticipate. Production has real timing, with requests arriving simultaneously from thousands of clients. Production has real users, who do things in sequences you didn’t think to test. The gap between your model and reality is where production bugs live.
This isn’t a novel observation. Michael Feathers wrote about the difference between seams (places you can change behavior for testing) and actual system behavior in Working Effectively with Legacy Code back in 2004. The insight holds: every seam you introduce to make code testable is also a place where the test’s model diverges from the real system.
The question isn’t whether your tests model reality imperfectly. They always will. The question is whether you understand how they diverge.
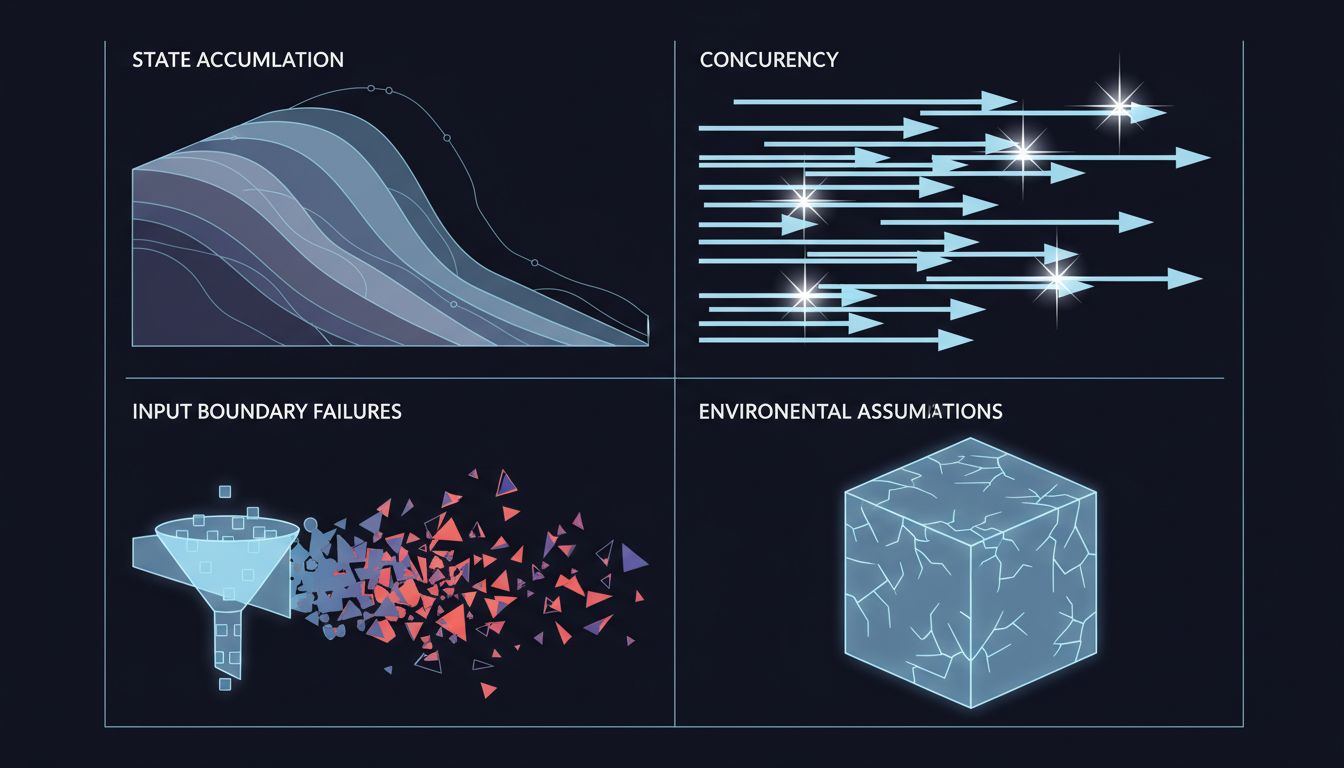
The Four Gaps That Production Exploits
Most production-only bugs fall into recognizable categories, and each one points to a specific testing failure.
State accumulation. Your tests typically start with a clean slate. Production doesn’t. A bug triggered by a user who has 47 items in their cart, has changed their shipping address three times, and has a partially-applied coupon code from a promotion that ended two years ago isn’t something you’re likely to reproduce from a fixture that creates a fresh user with two items. The fix here isn’t to create exhaustive fixtures. It’s to write tests that deliberately exercise boundary states and, more importantly, to run integration tests against a copy of anonymized production data on a regular schedule.
Concurrency and timing. You write tests that call functions sequentially. Production runs code concurrently. Race conditions, deadlocks, and TOCTOU (time-of-check-to-time-of-use) bugs are nearly invisible in sequential unit tests. The classic example is a double-submit problem: a user clicks a button twice, two requests hit your server simultaneously, both pass the “has this order been placed?” check before either commits, and you charge them twice. Testing this requires deliberately exercising concurrent execution paths, which most test suites simply don’t do.
Input boundary failures. Test inputs are written by the same person who wrote the code. They tend to be valid, reasonable, and well-formed. Production inputs come from users, from other systems, from network truncations, from encoding mismatches, and occasionally from people who are actively trying to break things. Fuzzing, property-based testing (tools like Hypothesis in Python or fast-check in JavaScript), and boundary-value analysis all help here, but they require intentional investment.
Environmental assumptions. Your code assumes things about the environment it runs in: that certain environment variables exist, that disk is writable, that the database responds within a reasonable time, that a third-party API returns a response in the documented format. These assumptions are invisible when everything works. They become visible failures when a deployment configuration is slightly off, or an upstream API starts returning a new field you didn’t expect, or connection pool exhaustion causes your database queries to start timing out. Contract testing and chaos engineering exist specifically to surface these failures before production does.
Coverage Metrics Are Measuring the Wrong Thing
Code coverage is the metric teams reach for when they want to quantify test quality. It’s not useless, but it measures something much narrower than people tend to assume: it tells you which lines of code were executed during your test run. It says nothing about whether those executions reflected realistic conditions.
You can have 90% line coverage on a function that handles HTTP responses and still have zero tests for the case where the response body is valid JSON but missing an expected field, or where the status code is 200 but the body signals an error (a pattern that, notoriously, many payment and third-party APIs use). The line got covered. The behavior didn’t.
Mutation testing is a better signal. Tools like Stryker (JavaScript/TypeScript) or mutmut (Python) automatically introduce small changes to your code, flipping a > to >=, removing a return value, swapping a boolean, and then check whether your tests catch the change. A high mutation score means your tests are actually sensitive to the logic they’re covering. A low one means you’re executing code without asserting much about it.
The teams with the fewest production-only bugs don’t just have high coverage. They have tests that would fail if the code changed in subtle, wrong ways.
Production as a Test Environment
The counterintuitive move is to treat production itself as a source of test cases, not just a place where bugs happen.
Observability tools, when used well, tell you exactly what inputs your system received and what paths they took through your code. Every production incident is a concrete example of a real input that caused unexpected behavior. The right response isn’t just to fix the immediate bug. It’s to add a regression test that captures that exact scenario and then audit whether the test suite’s model of that path was wrong in ways that might affect other paths too.
Netflix’s Chaos Engineering practice is a well-documented example of this philosophy taken further: deliberately injecting failures into production to verify that the system handles them, because you’ve accepted that your test environment will never fully model the failure modes of real infrastructure. For most teams, the relevant lesson isn’t to start breaking their own production systems, but to acknowledge that production behavior is information, and to build feedback loops that translate it back into test coverage.
Feature flags with gradual rollouts serve a similar purpose at the code level. If you’re unsure whether new logic handles real production inputs correctly, rolling it out to 1% of traffic and watching closely is a form of staged testing. The bugs that vanish when you look at them closely are often the same ones that only appear under real load and real data distributions.
The Architecture Question You’re Avoiding
Sometimes the reason a bug only appears in production is that the code is genuinely hard to test. A function that does five things, reaches into global state, calls external services, and has behavior that depends on timing is hard to test thoroughly because it’s doing too much. The difficulty of writing a good test is often a signal about code structure, not just about test strategy.
This is where the test-first argument has real substance, not as a religious practice, but as a design feedback mechanism. If you write the test before the code, you discover immediately when the code’s design makes realistic testing difficult. That’s a signal to redesign, not to write a complicated mock.
The production bugs that are hardest to diagnose are almost always in code that was also hard to test. The causal arrow runs both ways: hard-to-test code tends to have untested corner cases, and those corner cases are where bugs accumulate.
What This Means
Production-only bugs cluster around the same gaps: accumulated state, concurrent execution, realistic input variety, and environmental assumptions. Your test suite probably doesn’t cover these well, and code coverage metrics won’t tell you that it doesn’t.
The practical path forward isn’t to write more tests, but to write tests that model the right things. Mutation testing to check whether your assertions have teeth. Property-based testing to cover input space you didn’t think of manually. Concurrency tests for code paths that production will hit simultaneously. Regular integration tests against realistic (anonymized) data. Explicit regression tests for every production bug, built immediately after the incident.
And when a bug only appears in production, resist the urge to just fix it and move on. Read it as a diagnostic. It’s telling you something specific about where your model of the system diverges from the system itself. That’s the most useful information your tests can give you, and it’s coming from outside the test suite.





