

The Setup
In 2019, a mid-sized fintech company running a payment processing service had what looked like a healthy engineering culture. Code coverage hovered above 80 percent. CI ran on every commit. Engineers were proud of the test suite. Bugs in staging were caught and fixed before deploys.
Then a class of bug started appearing in production that nobody could reproduce locally. Transactions would silently fail under specific currency conversion scenarios, but only when processing volume was high. The failures weren’t dramatic. No exceptions thrown, no alerts triggered. A payment would be submitted, the system would respond with a success code, and then nothing would actually settle. The bug lived in the gap between what the system said it did and what it actually did.
This happened four times over eighteen months. Each time, the team fixed the specific case. Each time, a new variant emerged.
What Was Actually Happening
The root cause, when they finally dug far enough, wasn’t subtle. Their tests mocked the third-party currency conversion API at the HTTP client level. This is standard practice, and it made the tests fast and deterministic. But the mock always returned responses instantaneously, with perfectly formatted data, under zero load.
Production didn’t do any of those things.
The real API sometimes returned responses in a slightly different field order. It occasionally sent numeric values as strings instead of floats, technically within spec but not what the team had ever seen in development. Under high concurrency, responses sometimes arrived slightly out of order when the system made parallel requests to optimize throughput. The mock tested none of this. It tested the happy path against a fiction the team had invented.
The 80 percent code coverage number was real. It told them that 80 percent of their code was executed during tests. It said nothing about whether those tests were testing the right conditions. Coverage measures how much of your code tests touch, not how much of reality your tests model.
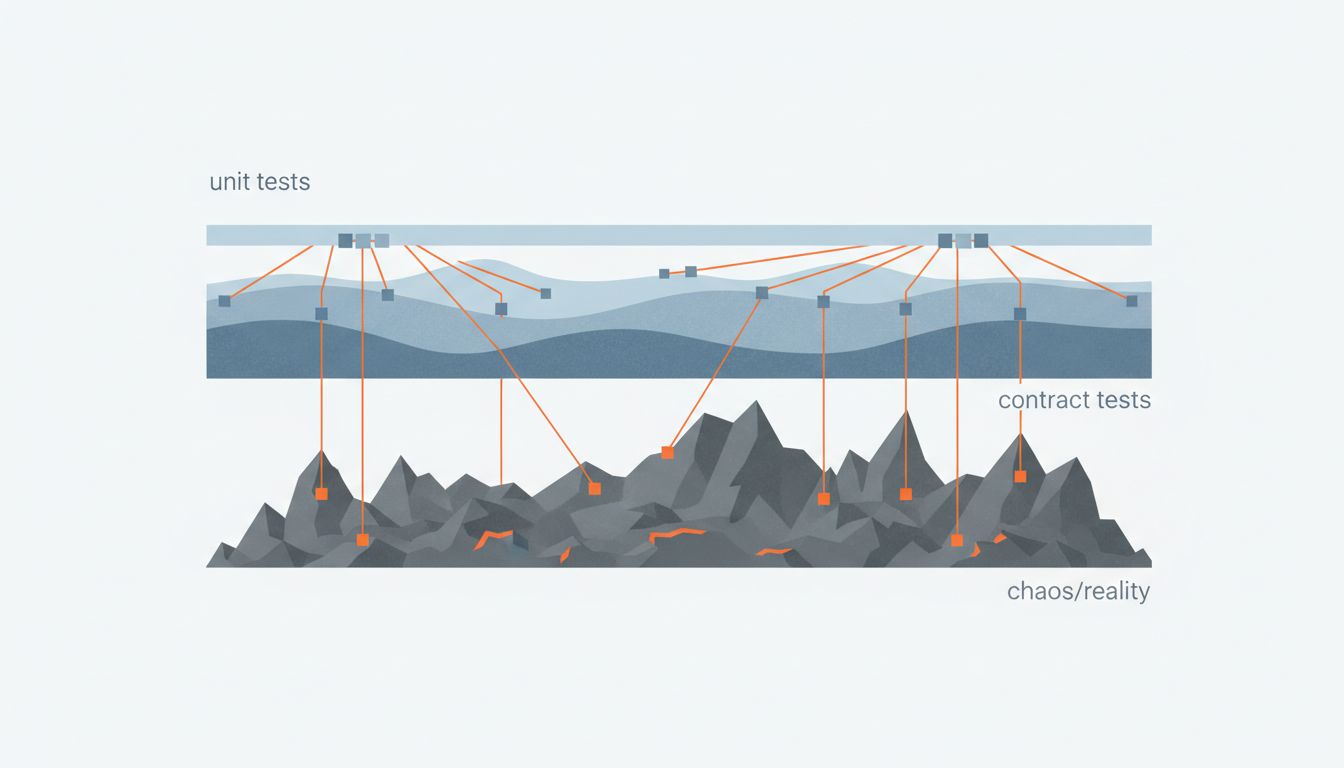
This is a distinction the industry has been slow to internalize. A test that calls your payment function with a clean mock and verifies it returns true is not a bad test. It’s just a test that tells you your function runs, not that it behaves correctly under the conditions it will actually face.
Why This Pattern Is So Common
The reason teams end up here isn’t laziness. It’s a reasonable-seeming set of tradeoffs made incrementally over time.
You mock external services because you need tests to be fast and reliable. Fair. You test the happy path first because you need to ship. Also fair. You add tests when bugs are reported, so your test suite gradually accumulates cases for bugs you’ve already seen. Reasonable.
The problem is that this process produces a test suite shaped by your past experience, not by the actual surface area of what can go wrong. Every production bug that surprises you is evidence that the space of possible failures is larger than your test suite assumes. The mock-the-world approach doesn’t just simplify testing, it actively narrows the problem space you’re reasoning about.
The fintech team’s tests were optimized for speed and developer convenience, both of which are real values. But they had effectively made a bet that the third-party API would always behave exactly as it did during the one afternoon they wrote the mock. That bet was quietly wrong for years before the failure rate got high enough to notice.
This is also why your staging environment is often lying to you. Staging and local mocks share the same flaw: they’re controlled environments that make the external world look friendlier than it is.
What They Did About It
The fix the team landed on wasn’t to abandon mocks. That would have made the test suite slow and fragile in different ways. Instead, they made a distinction between two categories of tests that had previously been blurred together.
Unit tests kept their mocks, but the team got explicit about what those tests were asserting: that their own logic was correct, given well-behaved inputs. These tests answer the question “does my code do what I think it does?”
They then added a second layer: contract tests against recorded real API responses. They captured actual responses from the third-party API, including the edge cases they’d only discovered in production (strings where floats were expected, reordered fields, delayed parallel responses). These became part of the test suite. When a production incident revealed a new API behavior, they recorded it and added it to the contract library before fixing the bug. The test suite started accumulating real-world shapes instead of imagined ones.
They also added a chaos layer in staging: a lightweight proxy that randomly delayed responses, occasionally flipped field types, and injected out-of-order returns. This didn’t catch everything, but it pushed several latent bugs into visibility before they reached production.
Within two quarters, the class of silent settlement failures stopped appearing. Not because the API got more reliable, but because the team stopped assuming it was.
What This Tells Us About Test Design
The instinct when a production bug appears is to write a regression test for that exact bug. That’s the right instinct, but it addresses the symptom. The bug itself is telling you something structural: your tests are modeling a world that doesn’t exist.
Every production-only bug is a failure of imagination at test-writing time. The code didn’t fail. Reality did something the test author didn’t anticipate. That’s worth sitting with, because it means the fix isn’t just a new test case. It’s a question about how you build the model of reality that your tests represent.
Some practical questions worth asking after any production incident:
- What assumptions does our mock make about the external system that we’ve never verified against real behavior?
- Are there edge cases the third-party API documents but that we’ve never tested against?
- Does our test suite include any recorded samples of actual production responses, or only handcrafted ones?
- If this external system started behaving differently in a way that’s still technically within spec, would any test catch it?
The coverage number tells you something, but what it doesn’t tell you is often more important. A test suite that achieves 80 percent coverage against a clean fiction of the world can leave you confidently wrong.
The bugs that only appear in production are the gaps between your model and reality. They’re not just software problems to fix. They’re information about where your assumptions broke down, and they’ll keep coming until you update the assumptions.
The fintech team’s test suite was a map. It was a good map. It just didn’t include the territory.





