
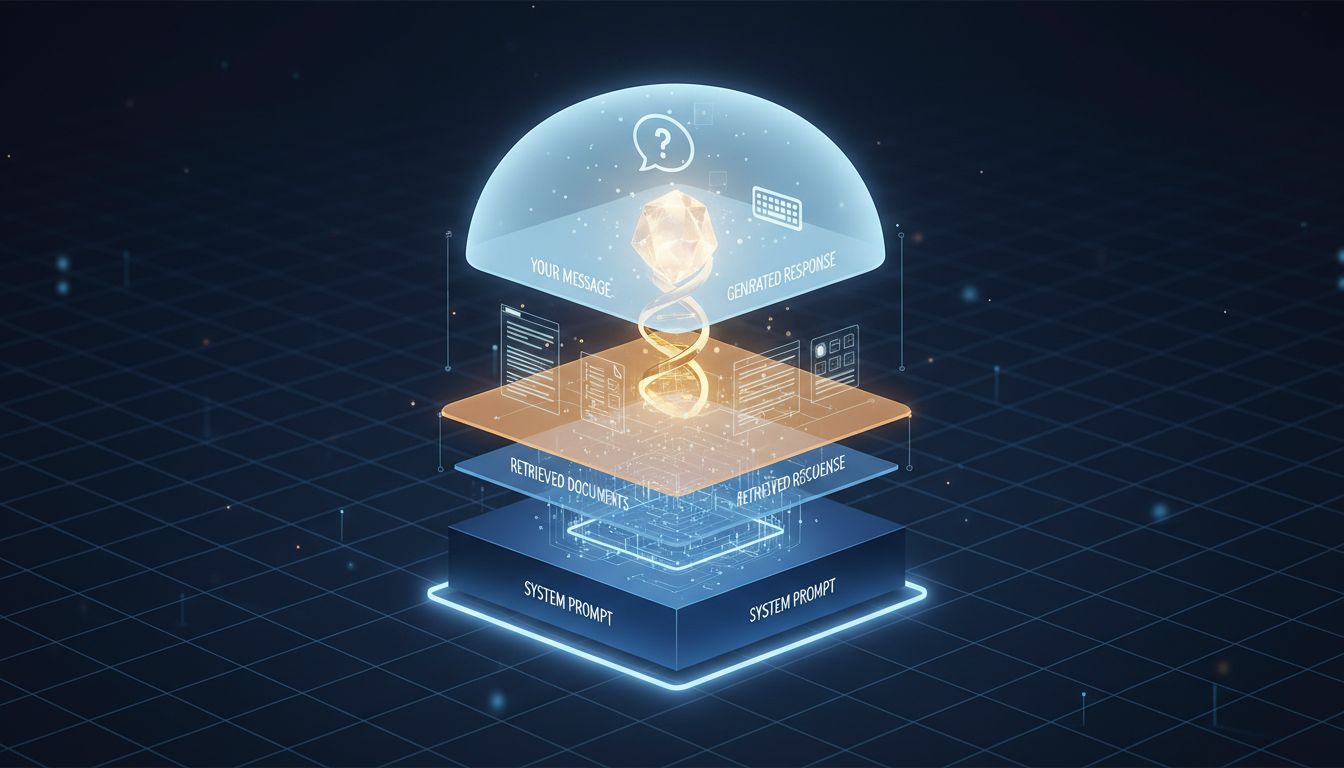
The simple version
When you type a message to an AI assistant, the model doesn’t receive just your words. It receives your words plus a pile of other text you never wrote and usually can’t see.
What’s actually in the context window
Every major AI product wraps your input inside a larger structure before passing it to the model. This structure typically has three parts: a system prompt (written by the company or developer running the product), any conversation history from earlier in the session, and finally your actual message.
The system prompt alone can be substantial. For a customer service bot, it might include the company’s return policy, a list of topics the bot is forbidden to discuss, instructions for tone and formatting, and examples of ideal responses. OpenAI, Anthropic, and others all provide system prompt fields specifically for this purpose, and products built on their APIs use them heavily.
This matters because the model treats all of this text as equally real input. It has no special awareness that your message is “the real one” and the system prompt is just scaffolding. Everything in the context window is just tokens.

Where the transformation gets more complex
Beyond system prompts, many applications apply additional transformations to your raw input before it reaches the model.
Retrieval-augmented generation (RAG) is the most common example. When you ask a question to a product that has it enabled, your query gets used to search a database, and the retrieved documents get silently prepended to your message. If you ask a company’s AI assistant “what’s your refund policy,” the model might receive something closer to: a system prompt, three paragraphs pulled from the company’s policy database, and then your actual question. The answer you get is shaped by which documents got retrieved, not just by what you asked.
Similarly, many systems apply “prompt injection” guardrails that rewrite your input before sending it. Your message might be scanned for certain patterns, wrapped in additional framing, or have keywords substituted. Some enterprise tools explicitly log, modify, and annotate inputs for compliance reasons before passing them downstream.
The model is also sensitive to formatting in ways that aren’t obvious. The same semantic content structured as a bulleted list versus a paragraph can produce meaningfully different outputs, because formatting affects how the model predicts what text should follow. Researchers studying this have found that structurally identical prompts with different whitespace or punctuation can shift results in measurable ways. This isn’t a bug, it’s a consequence of how these models learn: from text where formatting carries signal.
The tokenization layer
Before any of this text reaches the model’s attention mechanism, it passes through a tokenizer. This process splits text into chunks (tokens) that often don’t align with word or sentence boundaries.
The word “unbelievable” might be three tokens. “ChatGPT” might be two. Hyphenated terms can get split at the hyphen or not, depending on how frequently that compound appeared in training data. Non-English text tends to tokenize less efficiently, meaning languages with larger or less common character sets use more tokens to express the same information.
This matters for a few reasons. First, the model operates on tokens, not words, so the boundaries affect how it processes meaning. Second, APIs charge by token count and enforce context length limits by token count, so tokenization choices have real cost implications (something that often surprises teams building on top of these APIs, in the same way that infrastructure costs surface in unexpected places). Third, certain tokens have unexpected properties because of quirks in how models were trained, which is why researchers occasionally discover that specific strings produce strange model behavior.
Why this matters for how you use AI tools
Understanding this gap has practical consequences.
When a model gives you a surprisingly constrained answer, the constraint probably lives in the system prompt, not the model itself. The same underlying model can behave very differently across products because the system prompts are different. Trying to extract different behavior by rewording your question is often the wrong approach. The limitation was set before your question arrived.
When you’re building on top of an AI API rather than using a consumer product, you control the system prompt. This is one of the more powerful levers available to you, and most teams underinvest in it. A well-constructed system prompt can enforce consistent output formatting, constrain the model to topics where it performs reliably, and dramatically reduce failure cases, without any changes to the underlying model. If you want to understand more about what the model is actually doing once it has all this context, the mechanics of how LLMs process and summarize text is worth understanding.
And when you’re evaluating an AI product, remember that what you’re testing is the full stack: the model, the system prompt, the retrieval pipeline, and the tokenization choices. A competitor switching to a newer model might appear to perform better even if the model itself is comparable, simply because they wrote a better system prompt. Attributing performance to “the AI” when you mean “this particular configuration of the AI” is an easy mistake that leads to bad product decisions.
The gap between what you write and what the model reads is not a bug or a dark pattern. It’s a necessary part of how these systems get deployed at scale. But it’s invisible by default, and invisible things have a way of causing problems when you stop accounting for them.





