
Most debugging involves reading error messages, checking stack traces, inspecting variable states. You have tools. You have access. You can see inside the thing that’s broken.
Prompt engineering gives you none of that. The model is a system with billions of parameters you cannot inspect, trained on data you cannot fully audit, producing outputs you cannot reliably predict from first principles. Yet your job is to get consistent, useful behavior out of it. The mental model that actually helps here isn’t “writing instructions.” It’s debugging a system where all you can do is observe inputs and outputs, and reason about what’s happening in between.
Once you accept that framing, a lot of the frustrating weirdness starts to make sense, and the practical techniques get a lot clearer.
You Are Running Experiments, Whether You Realize It or Not
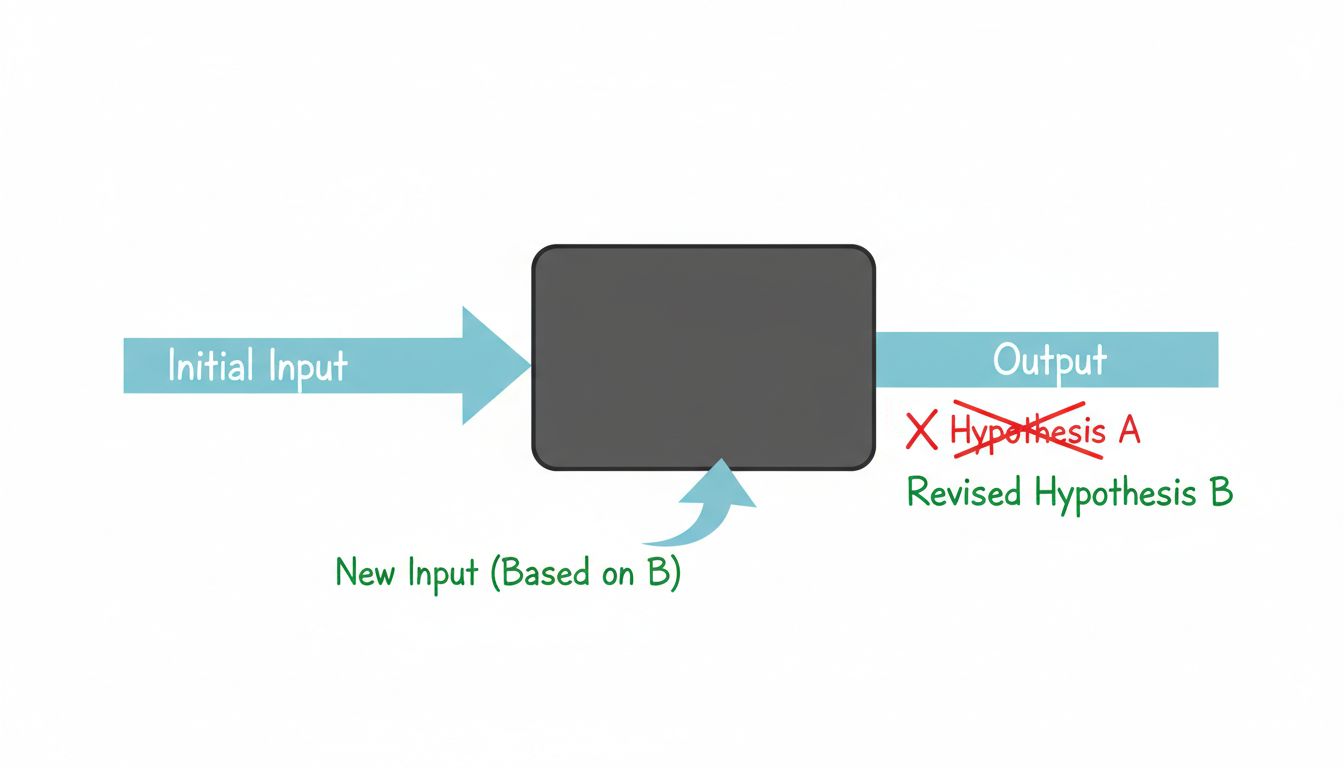
When a prompt doesn’t work, most people rewrite it based on instinct, run it again, and call that iteration. That’s not debugging, that’s guessing with extra steps. Real debugging requires a hypothesis.
Before you change a prompt, ask yourself: what specifically went wrong, and what do I think is causing it? “The output was too long” is an observation. “The model isn’t treating this as a summarization task because I haven’t given it a length constraint or an example of the output format I want” is a hypothesis. Those lead to very different fixes.
This matters because LLM outputs are noisy. Temperature settings, subtle phrasing differences, and the model’s stochastic nature mean that the same prompt can produce different results across runs. If you change three things at once and the output improves, you don’t know which change helped. You’ve made progress you can’t reproduce or explain. In production, unexplainable progress becomes a bug waiting to happen.
Change one variable at a time. Keep a log of what you tried and what changed. It sounds tedious, but you’ll save enormous time compared to re-exploring the same territory repeatedly.
The System Has Priors You Didn’t Set
Here’s the part that trips people up most: the model already has strong opinions before you send a single word. It was trained on an enormous corpus of human-generated text, which means it has absorbed patterns about what kinds of text follow other kinds of text. When you write a prompt, you’re not starting from a blank slate. You’re activating a context.
This is why seemingly minor phrasing changes produce dramatically different outputs. Asking a model to “write a summary” activates different learned patterns than asking it to “extract the key points.” Structuring your prompt like a formal document activates different behavior than structuring it like a casual conversation. The model is pattern-matching your input against everything it has seen, and responding in kind.
This is also why role prompting works, when it does. Telling a model “you are a senior software engineer reviewing code for production readiness” isn’t magic. It’s loading a context that statistically co-occurs with careful, technical, critical language. You’re steering the prior, not overriding it.
The practical implication: when a prompt isn’t working, consider what context your phrasing is actually activating. If you’re getting casual, vague outputs, your prompt may be reading as casual and vague. If you’re getting overly hedged, disclaimer-heavy responses, something in your framing may be triggering the model’s trained caution behaviors. Adjust the register, not just the content.
Constraints Are Your Compiler Warnings
In traditional software, you’d rather have a compiler error than a runtime bug. Strict types, linting rules, and explicit contracts catch problems early. Prompts without constraints are like dynamically typed code with no tests: they work until they don’t, and when they fail, you get very little information about why.
Constraints in prompts serve the same function. Specifying output format (JSON with these fields, a list of exactly five items, no more than two sentences) gives you something to test against. If the output doesn’t match the format, you have a clear failure signal. If it does match the format but the content is wrong, you’ve isolated the problem to the content logic, not the structure.
This is especially true if you’re building anything that uses the output programmatically. A model that usually returns valid JSON and occasionally returns a prose explanation wrapped around valid JSON will break your parser in ways that are annoying to debug. Explicit format constraints dramatically reduce that variance, and when they fail, they fail loudly. That’s what you want.
Few-shot examples act as constraints too. Showing the model three input-output pairs is a much more precise specification than describing the transformation in words. You’re showing it the shape of correct behavior, not telling it. For complex tasks, a handful of good examples usually outperforms a page of instructions.
Your Prompt Is Running in a Context You Don’t Fully Control
One thing traditional debugging has that prompt engineering doesn’t: a stable runtime. Your code runs on a machine with known specs, a known OS, known library versions. Your prompt runs inside a model that may be updated without notice, whose behavior varies by API parameters you may not be setting intentionally, and whose context window interacts with your prompt in ways that change as conversation history accumulates.
This is why prompts that work perfectly in testing can degrade in production, and why something that worked last month might behave differently today. As noted in “Your Carefully Engineered Prompt Has an Expiration Date”, model updates are a real source of prompt drift. Adding evals, even simple ones, lets you catch this early rather than learning about it from users.
The version control instinct from software engineering applies directly here. Treat your prompts as code. Store them in version control. When something breaks, you want to be able to diff what changed, not reconstruct it from memory. Teams that treat prompts as casual configuration strings eventually spend real engineering time debugging problems that would have been trivially identifiable with a little discipline.
What Good Prompt Engineers Actually Do
The best prompt engineers aren’t the ones who know the most arcane syntax tricks. They’re the ones who stay rigorous when the process feels fuzzy. They make one change at a time. They keep notes. They build small test sets of inputs with known correct outputs, so they can measure whether a prompt change actually improved things or just changed which examples it gets wrong.
They also know when to stop. Not every prompt problem is solvable with a better prompt. Sometimes the task is genuinely at the edge of what the model can do, and the right answer is a different architecture: retrieval-augmented generation, fine-tuning, breaking the task into smaller pieces, or using a different model entirely. Recognizing that limit is a skill, and it comes from treating prompt development as an empirical process rather than a creative one.
You can’t read the system you’re debugging. But you can be systematic about how you probe it, and systematic beats clever almost every time.





