

The term comes from Werner Heisenberg’s uncertainty principle: the act of measuring a particle’s position disturbs its momentum. Werner’s physics insight from 1927 mapped onto software with uncomfortable precision. A Heisenbug is a defect that changes behavior, or disappears entirely, when you attempt to examine it. Attach a debugger and the crash stops. Add a log statement and the race condition resolves. Remove the log statement, the crash returns. This isn’t magic. It’s determinism colliding with observation overhead.
Why Observation Changes the Outcome
The most common source of Heisenbugs is timing. Modern software runs on a substrate of shared state, threads, and network calls, none of which behave like simple functions that return the same output for the same input. When two threads access shared memory without proper synchronization, the result depends on which one gets scheduled first. That scheduling is determined by the operating system, the CPU, and a cascade of tiny timing decisions that can shift by microseconds depending on system load.
When you attach a debugger, you pause thread execution. Those pauses change the interleaving of operations. The race condition that produced the bug required Thread A to read a variable at exactly the moment Thread B was writing it. With the debugger adding latency, Thread B finishes writing before Thread A reads, and the bug never fires. The program appears correct. The bug appears fixed. Neither is true.
Logging introduces the same problem at smaller scale. A console.log call or a print statement takes time. Microseconds, usually, but sometimes more if the output is being flushed to disk. That added time is enough to shift the timing of concurrent operations. Engineers have spent entire days adding and removing log statements, watching a bug appear and disappear, convinced they must be doing something wrong. They aren’t doing anything wrong. The observation is the interference.
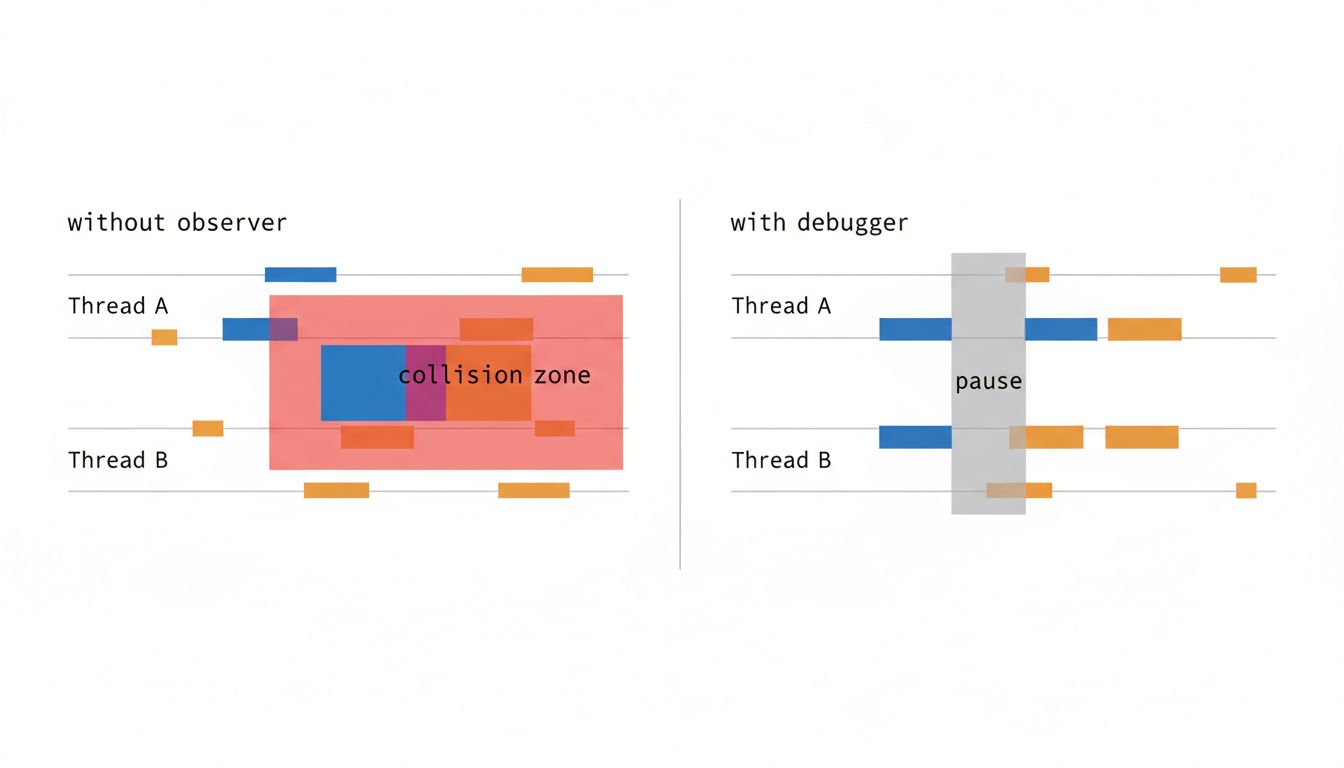
The Memory and Compiler Variants
Timing isn’t the only mechanism. A second class of Heisenbug comes from uninitialized memory. In C and C++, local variables don’t start at zero. They contain whatever bytes happened to be at that memory address from a previous operation. A function that reads an uninitialized variable is reading garbage, and that garbage changes depending on what the program has done recently.
In debug builds, many compilers fill uninitialized memory with a recognizable pattern (0xCD is a classic choice in Microsoft’s debug heap). This makes the garbage consistent and often obviously wrong, which helps catch the bug. In release builds, the memory contains real leftovers from prior computation, which may happen to produce a value close enough to a valid one that the program limps along. The debug build crashes immediately. The release build works, until it doesn’t.
Compiler optimizations add another layer. A compiler is allowed to reorder memory operations if it can prove (within the rules of the language standard) that the reordering doesn’t change program semantics. The catch is that those rules assume single-threaded execution. When multiple threads share memory without explicit synchronization primitives (mutexes, atomics, memory barriers), the compiler’s reordering can break assumptions that look perfectly reasonable in the source code. The bug exists in the compiled binary but not in the source as written, which is a particularly disorienting place to look for it.
Reproducing the Unreproducible
The working strategy for hunting Heisenbugs isn’t to reproduce them in a debugger. It’s to make the environment hostile enough that the bug fires reliably without your direct observation.
For race conditions, thread sanitizers are the right tool. ThreadSanitizer (TSan), available in both GCC and Clang, instruments the compiled binary to detect data races at runtime. It adds overhead (sometimes significant overhead), but it doesn’t change the fundamental timing the way a debugger does. It’s watching from inside the program rather than pausing it from outside. Valgrind’s Helgrind tool does similar work for C and C++ codebases.
For timing-sensitive bugs more generally, running the program under artificial load is often more useful than running it in isolation. A race condition that fires one time in a thousand on a developer’s laptop might fire one time in ten on a server that’s also handling disk I/O, garbage collection, and a dozen other processes. Reproducing the production environment is the precondition for reproducing the bug.
Stress testing with randomized delays is another technique. Tools like rr (Mozilla’s record-and-replay debugger for Linux) take a different approach entirely: they record a complete execution and let you replay it deterministically, examining it after the fact without changing when anything happened. For bugs that only manifest occasionally, rr changes the game entirely. You record thousands of executions, filter for the ones that crashed, and replay those at your leisure.
What Heisenbugs Reveal About Your Architecture
The existence of a Heisenbug in a codebase is diagnostic information. These bugs don’t appear in purely functional code that transforms inputs to outputs without shared mutable state. They live at the boundaries where state is shared, where threads meet, where timing assumptions hide in plain sight.
A Heisenbug is, in that sense, a signal that your architecture has implicit temporal dependencies that aren’t visible in the code’s structure. Two functions that look independent aren’t, because they both write to the same global, or because one assumes it runs before the other without enforcing that assumption. The bug is revealing a contract that nobody wrote down.
This is why fixing Heisenbugs at the symptom level is often the wrong move. You can add a mutex around the shared variable and suppress the specific race condition. But if the code has the kind of structure that produced one race condition, it probably has the structure to produce others. The real fix is understanding why the shared mutable state exists and whether it needs to. What production bugs are telling you about your tests applies here too: the bug is feedback, and ignoring the feedback to fix the symptom leaves the underlying design problem intact.
Heisenbugs are genuinely hard. They resist the standard debugging loop of observe, hypothesize, test. But they’re not random. They’re deterministic systems behaving deterministically under conditions you can’t easily control. The path through them is always the same: stop trying to watch the bug happen, and start building the tools to catch it without looking.





