

The simple version
When a bug vanishes after you add logging, the logging itself changed the program’s behavior. You’re not imagining things. The bug is still there, and it just told you exactly what kind of bug it is.
What’s actually happening
Your program isn’t magic and neither is your logger. When you add a console.log or a print statement, you’re inserting real work into the execution path. That work takes time. It accesses memory. It may trigger operating system calls to write to a file or a terminal. All of that changes when things happen inside your program, even if it doesn’t change what things happen.
For a large class of bugs, when is everything.
The most common culprit is a race condition. Race conditions happen when two parts of your program are competing to read or modify shared data, and the outcome depends on which one gets there first. The bug only shows up when the timing works out a specific (wrong) way. Add logging, and you nudge the timing. The race resolves differently. The bug goes away. You stare at clean output and feel like you’re losing your mind.
This is sometimes called a Heisenbug, borrowing from the quantum physics principle that observing a particle changes its state. It’s a useful name because it reminds you that your observation is part of the system.
The three flavors you’ll actually encounter
Race conditions are the classic case. Two threads, two async callbacks, or two processes are touching the same resource without proper coordination. The logging slows one of them down just enough that the other wins the race every time.
Uninitialized memory can also behave this way. In languages where you’re managing memory yourself (C, C++, and to some extent Rust before you learn its ownership model), an uninitialized variable holds whatever bytes happened to be sitting in that memory location. Adding logging statements changes what’s on the stack or the heap before your buggy code runs, which changes those stale bytes, which changes the behavior. The bug is still there. The data it was reading just changed.
Compiler and CPU optimizations are the sneaky third case. Modern compilers will reorder, cache, or skip operations if they believe the results are equivalent. Adding logging prevents some of those optimizations because now the compiler has to assume some side effects are visible. In optimized builds, a bug that looks like a simple off-by-one might actually be the CPU reading a stale value from a register cache. The logging forces a memory read. Problem solved, except not really.
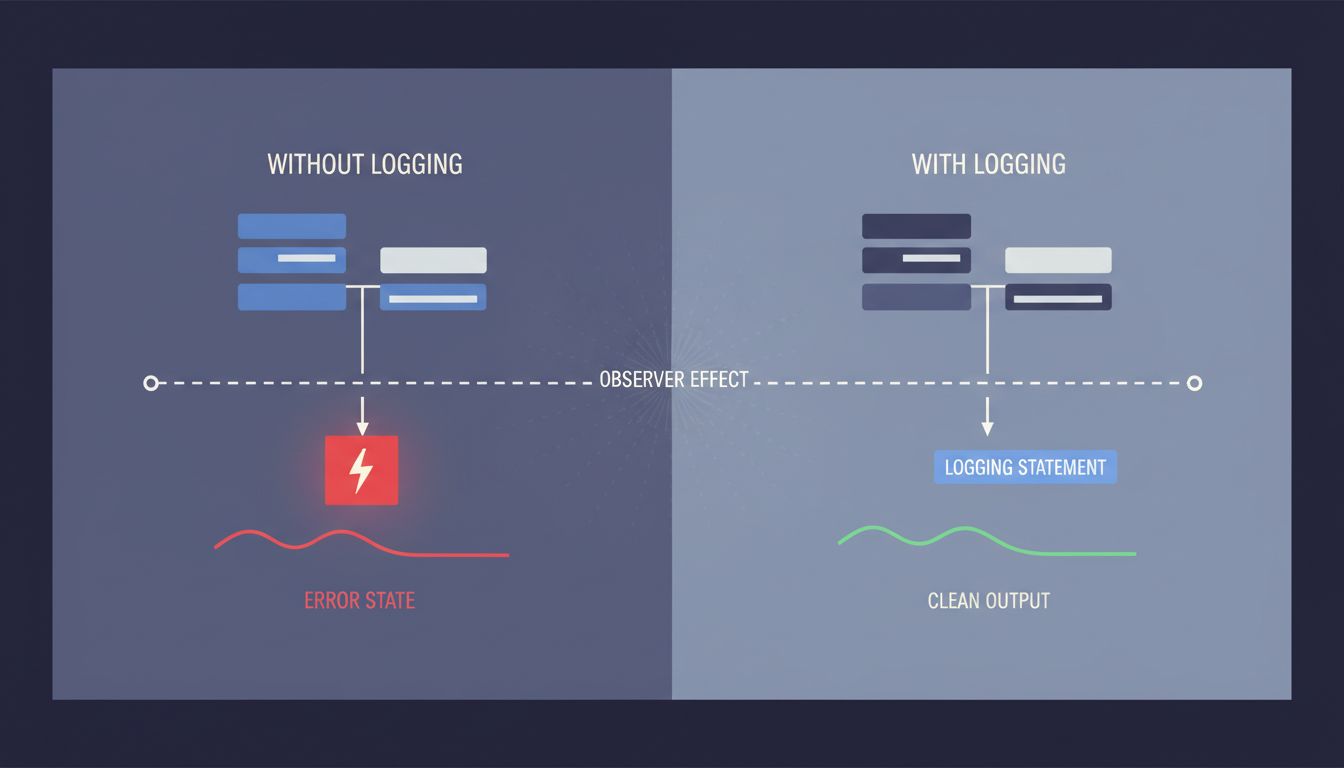
Why this matters more than it used to
Concurrent code is everywhere now. JavaScript’s async/await model, Python’s asyncio, Go’s goroutines, Rust’s async ecosystem. You don’t have to be writing multi-threaded C to run into timing-dependent bugs. Any time you have await in your code, you have a potential interleaving point where another piece of code can run.
Mobile apps that make multiple API calls in parallel. Web servers handling simultaneous requests. Data pipelines with concurrent workers. All of these are fertile ground for Heisenbugs, and the problem scales with complexity. The more concurrent the system, the harder the bug is to pin down, and the more likely that your logging is actively deceiving you.
If you’ve seen bugs that you can’t reproduce at all, a disappearing-logging bug is the easier cousin. At least you know what category you’re dealing with.
What to actually do about it
The good news: a Heisenbug is a useful diagnosis, not just a frustration. Here’s a practical approach.
Stop trying to observe your way to the answer. More logging won’t help. More print statements won’t help. Each one shifts the timing and moves the bug. You need to reason about the code statically, not observe it dynamically.
Look for shared mutable state. In whatever scope is misbehaving, find every variable or resource that more than one thread, coroutine, or callback can touch. Write them down. For each one, ask: is there a lock, a mutex, a semaphore, or some other coordination mechanism protecting this? If not, that’s your suspect.
Use the right tools. Most languages have thread sanitizers or race detectors built into their toolchains. Go’s race detector (go run -race) is excellent and has found real bugs in production codebases. Clang and GCC both support ThreadSanitizer. Valgrind’s Helgrind tool works for C and C++ programs. These tools run your program and watch for concurrent access patterns that would cause bugs, even if timing happens to prevent them this run. They find the crime before the accident, which is exactly what you need.
Add synchronization, not logging. Once you’ve identified your shared state, put a lock around it or restructure the code so the data isn’t shared at all. Immutability and message-passing architectures exist specifically to make this class of bug impossible rather than just unlikely.
Read the code with fresh eyes for assumptions. Race conditions often live inside assumptions that feel obviously safe. “This function always completes before the callback fires.” “Only one user can trigger this at a time.” Those assumptions deserve scrutiny.
The deeper point worth remembering
A disappearing bug is diagnostic information. It’s the code telling you something specific about its own failure mode. The frustrating part (you can’t see it directly) is also the useful part (you know it’s timing-dependent). That narrows your search considerably.
The instinct to add more observability is usually right in software. Observability is genuinely valuable. But there’s a category of problem where the act of observation is itself the interference, and learning to recognize that category will save you hours of confused debugging. When the bug runs from your logging, stop chasing it. Start reading.





