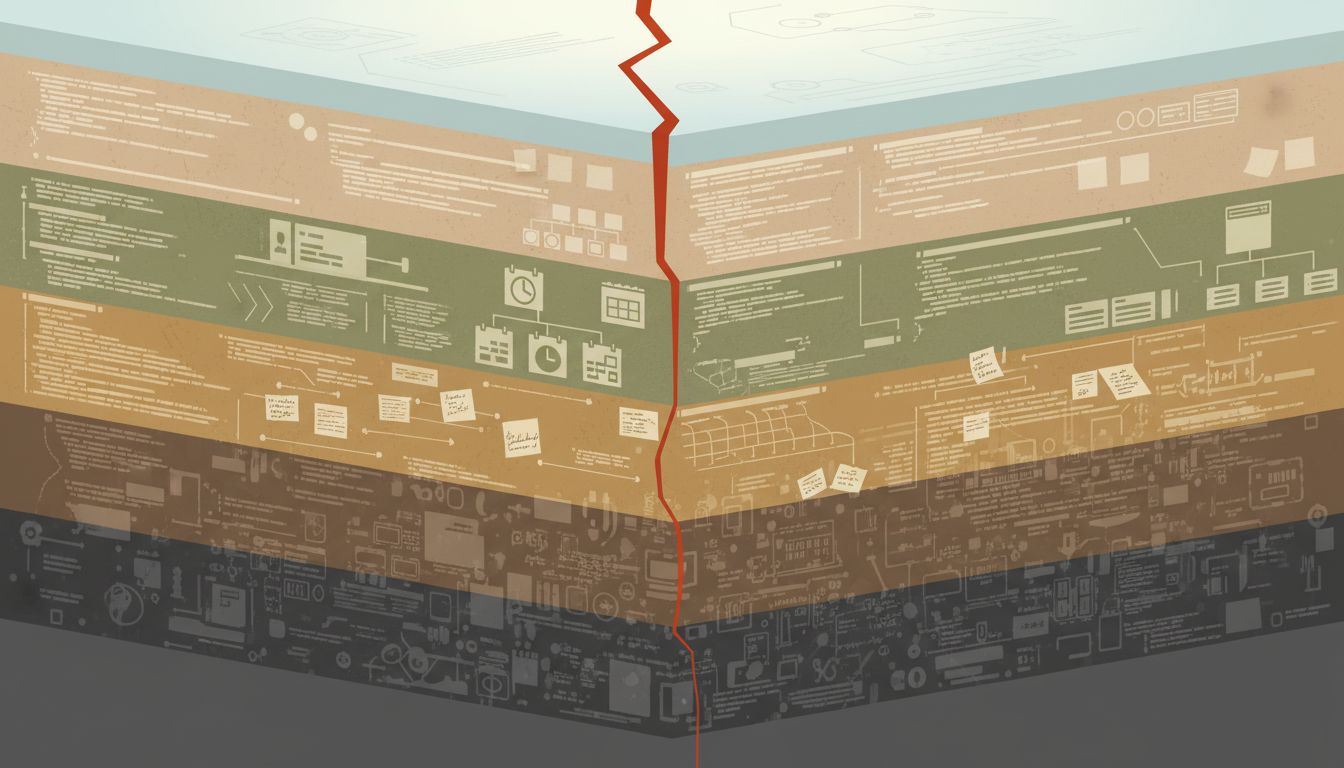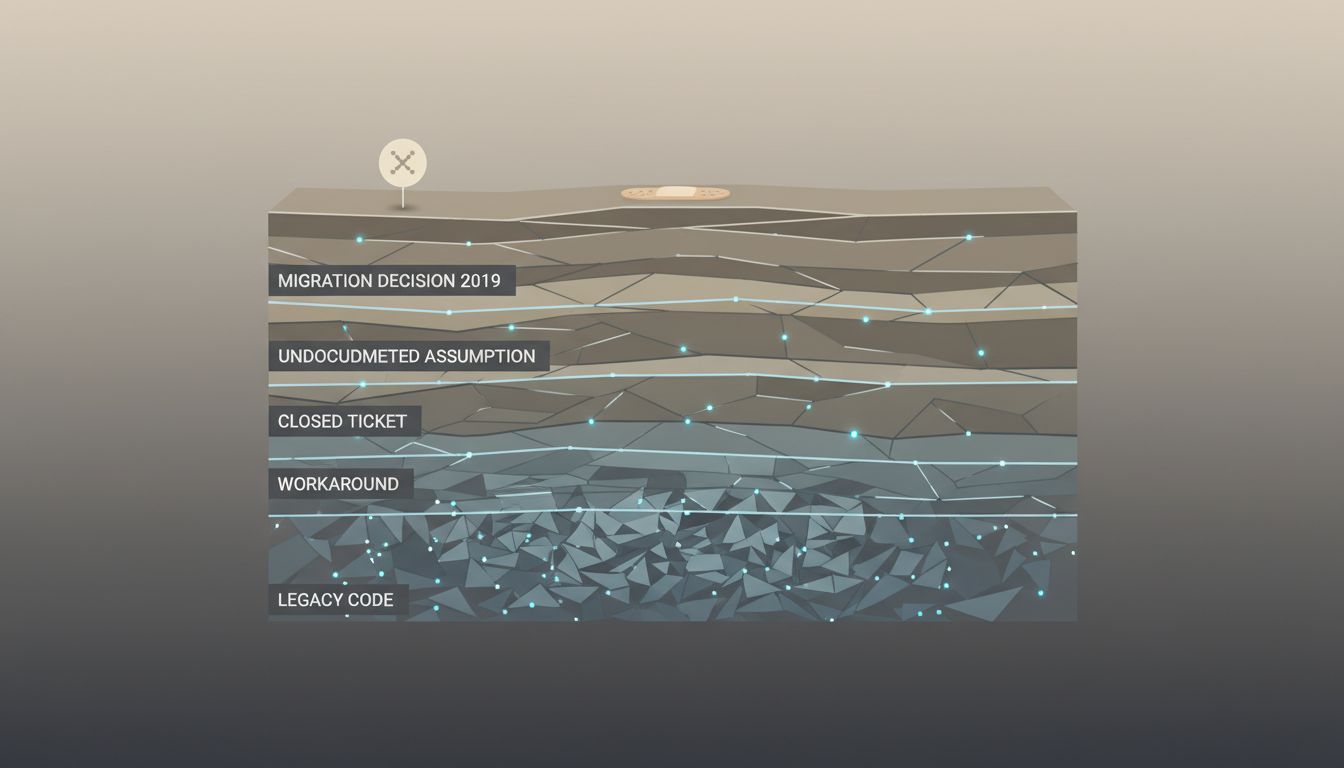
A senior engineer at a payments company once told me about a bug that had been silently corrupting transaction records for almost two years. When someone finally caught it, the fix took forty minutes. A missing null check, a guard clause, done. The engineer who wrote the fix was celebrated at the all-hands. He had no idea the bug had existed since a cost-cutting migration in 2019, that three different people had noticed strange behavior and filed tickets that were closed as “cannot reproduce,” or that the original developer had flagged the architectural decision that caused it in a design doc nobody ever read.
The fix was real. The understanding was absent. And in most engineering organizations, nobody noticed the difference.
Fixing and Understanding Are Different Skills
This is not a knock on engineers who fix bugs quickly. Fast diagnosis is genuinely valuable. But there’s a category error that runs through how most teams think about debugging: they treat a bug as a discrete object that exists in the code, rather than as a symptom of a decision made under constraints that no longer exist or were never fully visible.
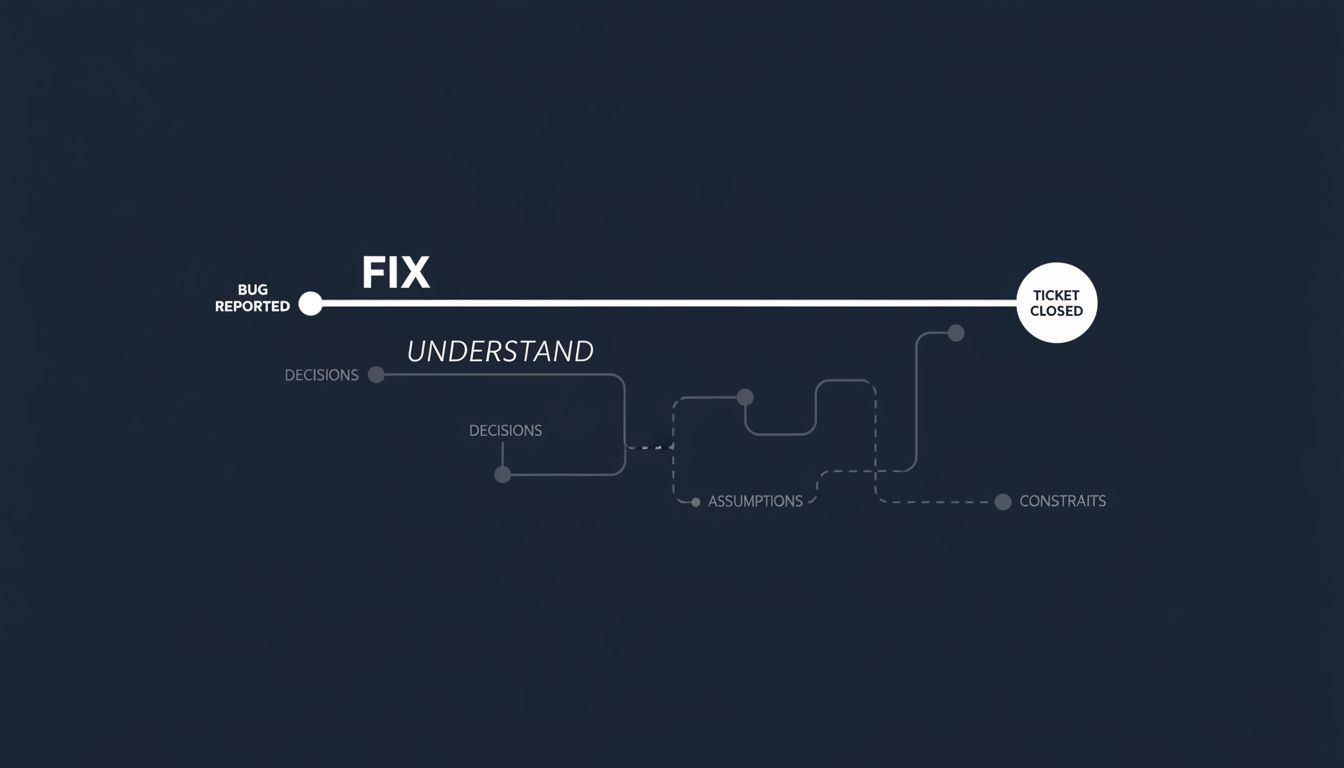
When you fix a null pointer exception, you’ve addressed what crashed the program. You haven’t necessarily addressed why the data was null in the first place, who expected it to never be null, what assumption that expectation was based on, and whether that assumption is violated anywhere else in the system. The first question is a debugging question. The rest are systems questions. Most postmortems gesture at the second category and then quietly return to shipping.
The economist would call this treating the symptom as the disease. The bug report says the system crashed on input X. The real story is often that six months ago, a product decision changed the shape of X without anyone updating the contracts between services that depended on the old shape. The fix patches the crash. The story stays unwritten.
Why Organizations Don’t Actually Want the Full Answer
Here’s the uncomfortable part: in most organizations, the incentives actively discourage deep understanding of why a bug existed.
Time pressure is the obvious culprit, but it’s not the only one. There’s also the problem of attribution. If you trace a bug back to its true origin, you often end up in territory that implicates a decision made by someone senior, or a process that the organization is proud of, or a previous quarter’s OKRs that pushed speed over correctness. That’s uncomfortable. A null check is not uncomfortable. So the null check gets merged, and the root cause gets softened in the postmortem to something like “insufficient validation” that assigns blame to no one and changes nothing.
There’s also the visibility problem. The engineer who spends three days tracing a bug through four systems and emerges with a five-page document explaining a design flaw produces something most organizations have no idea how to value. The engineer who pushes a fix in forty minutes produces a closed ticket. Closed tickets are counted. Documents are filed. The economics here are pretty clear about which behavior gets rewarded.
The Cost of Shallow Fixes
The obvious cost is that the same class of bug keeps returning. This is so common in software that it barely registers as a problem anymore. Teams develop institutional memory of workarounds rather than understanding of root causes. New engineers learn the workarounds. The original decisions recede further into history.
But there’s a subtler cost that’s harder to measure. When engineers repeatedly fix bugs without understanding them, they lose confidence in the system. Not in a dramatic way, but in the slow accumulation of “I’m not totally sure why this works, but it does” and “don’t touch that, nobody knows what it does” and “we tried to refactor that once and things broke in ways we couldn’t explain.” The codebase becomes a place where people navigate carefully rather than reason clearly. That instability compounds in ways that aren’t always obvious.
The people who actually understand why bugs exist are usually the ones who have been around long enough to remember the decisions that created them. When they leave, the understanding leaves with them. The fix stays. The context is gone.
What Actually Helps
A few teams get this right, and the pattern is usually the same: they create a formal distinction between fixing a bug and understanding it, and they staff accordingly.
This doesn’t mean every bug needs a full archaeological investigation. Most don’t. A typo in a config file doesn’t need a postmortem. But for any bug that makes it past testing into production and affects users, there’s value in a short, honest accounting that asks not just “what was the proximate cause” but “what decision, constraint, or assumption upstream of the code made this possible.” That question is often answerable in an hour. The answer is almost always useful.
The other thing that helps is treating design documents and decision logs as first-class artifacts, not bureaucratic formalities. A bug traced back to a deliberate trade-off in a documented decision is a very different problem from a bug that emerged from an invisible assumption. The first tells you whether the trade-off still makes sense. The second tells you that you have assumptions baked into the system that nobody is aware they’re making.
None of this requires a massive process overhaul. It mostly requires a cultural shift in what questions are considered worth asking after a fix ships. “It’s fixed” is the beginning of understanding, not the end of it.
The Gap Between Fixing and Knowing
The engineer who fixed that payments bug in forty minutes was good at his job. The bug was real, the fix was correct, and the users were unaffected going forward. Nobody would fault the repair itself.
But the two years of silent corruption, the closed tickets, the unread design doc, the migration decision that nobody revisited: those didn’t go away. They became part of the substrate, waiting for the next system that made the same assumption about what the data would look like.
Software is full of fixed bugs that aren’t understood. The economic pressure to close the ticket is real and often reasonable. But the organizations that consistently produce reliable systems are the ones that, at least sometimes, stay curious after the fix ships. The question “why did this exist” isn’t academic. It’s how you avoid writing the same postmortem two years from now.