In 2012, Knight Capital Group lost $440 million in 45 minutes due to a software deployment gone wrong. Most people remember it as a cautionary tale about automated trading and deployment processes. Fewer people notice the timestamps scattered throughout the post-mortem: orders firing milliseconds apart, systems disagreeing about sequence, logs that couldn’t be trusted to tell you what happened first. Knight Capital is the dramatic version of a problem that quietly corrupts data, breaks distributed systems, and produces bugs that look impossible until you understand what time actually means to a computer.
Time feels like a solved problem. Your laptop shows the correct time. Your phone syncs automatically. Clocks have existed for centuries. Surely software just reads the clock and records it. The reality is messier, and the gap between “what time is it” and “what time did this happen, in a way that’s consistent with what every other system recorded” is where production incidents are born.
The Setup
Consider a financial data company (the architecture here is representative of many real systems, not a single organization) running a distributed trading analytics platform across three data centers in New York, London, and Tokyo. Their core product is an audit trail: a timestamped record of every order, modification, and cancellation, used by trading desks to reconstruct what happened during volatile market periods.
The engineering team was experienced. They used NTP (Network Time Protocol) to synchronize clocks across servers. They stored timestamps as UTC to avoid timezone confusion. They wrote careful code. On paper, their time handling was sound.
The problem emerged during a particularly volatile trading session. A client disputed a trade execution. When the analytics team pulled the audit trail, the timestamps told a story that was physically impossible: a cancellation appeared to arrive before the order it cancelled. The sequence of events, reconstructed from logs across three data centers, was internally contradictory.
What Happened
The team dug in and found three separate problems, each of which was individually manageable but collectively catastrophic.
First, NTP synchronization has inherent drift tolerance. NTP keeps clocks close but not identical. Across a wide-area network under load, two servers that both think they’re “synchronized” can disagree by anywhere from a few milliseconds to, in degraded conditions, several hundred milliseconds. For most applications, a 50-millisecond clock skew doesn’t matter. For a system trying to reconstruct the causal sequence of orders firing in competitive markets, 50 milliseconds is an eternity.
Second, the application was using System.currentTimeMillis() in Java (or its equivalent in other services), which reads the system wall clock. Wall clocks can jump. When NTP corrects a drifting clock, it doesn’t always do so gradually. Sometimes it steps the clock backwards. A server that was running 200 milliseconds fast gets corrected, and suddenly timestamps in that server’s logs go backwards. Events that happened after other events now have earlier timestamps. The sequence inverts.
Third, and most subtly, the team was using timestamp ordering as a proxy for causal ordering. This is the root mistake. A timestamp tells you what the clock read when an event was recorded. It does not tell you which event caused which, which happened first in any meaningful sense, or whether the clocks generating those timestamps agreed with each other. As distributed systems and their relationship to time have taught many engineers the hard way, a timestamp is a measurement of a physical process, and physical processes have error bars.
The practical result: the audit trail was wrong. Not wrong in a way anyone had designed for, but wrong in a way that looked right until the moment a client needed it to reconstruct a disputed trade.
Why This Keeps Happening
The intuition that time is a global, consistent, monotonically increasing property of the universe is correct in everyday life. It is false in distributed systems.
Einstein aside, the practical issue is that computers measure time with clocks, clocks drift, and drift correction can cause discontinuities. More fundamentally, in a distributed system, there is no single authoritative clock that every node can read instantaneously. Reading a remote clock takes time, and the act of transmitting the reading introduces uncertainty. Leslie Lamport formalized this in 1978 with his paper on logical clocks, and the insight is still routinely ignored in production systems: if you need to know the order of events across machines, wall-clock timestamps are unreliable evidence.
Google’s Spanner database team faced this problem at scale and built TrueTime, a system that provides timestamps with explicit uncertainty bounds. Rather than claiming to know that an event happened at exactly time T, TrueTime reports that an event happened in the interval [T-ε, T+ε], where ε is a measured uncertainty bound. Spanner uses atomic clocks and GPS receivers in every data center to keep ε small (typically under 7 milliseconds) and then uses that bound to make correctness guarantees. When a transaction commits, Spanner waits out the uncertainty window before declaring the commit complete. It trades latency for correctness.
Most companies don’t have Google’s infrastructure budget. But the underlying lesson applies universally: if you’re using timestamps to establish ordering, you need to be explicit about what you actually know and what you’re assuming.
What We Can Learn
The distributed analytics company’s fix involved multiple layers, and each layer addressed a different failure mode.
For the clock synchronization problem, they moved from NTP to PTP (Precision Time Protocol), which achieves sub-microsecond synchronization on local networks by using hardware timestamping at the network interface level rather than in software. For cross-datacenter coordination, they adopted explicit uncertainty bounds rather than pretending clocks were synchronized.
For the wall-clock jump problem, they switched from wall-clock readings to a combination: wall time for human-readable logging, and monotonic clock readings (which never jump backwards, but don’t synchronize across machines) for measuring elapsed time within a single process.
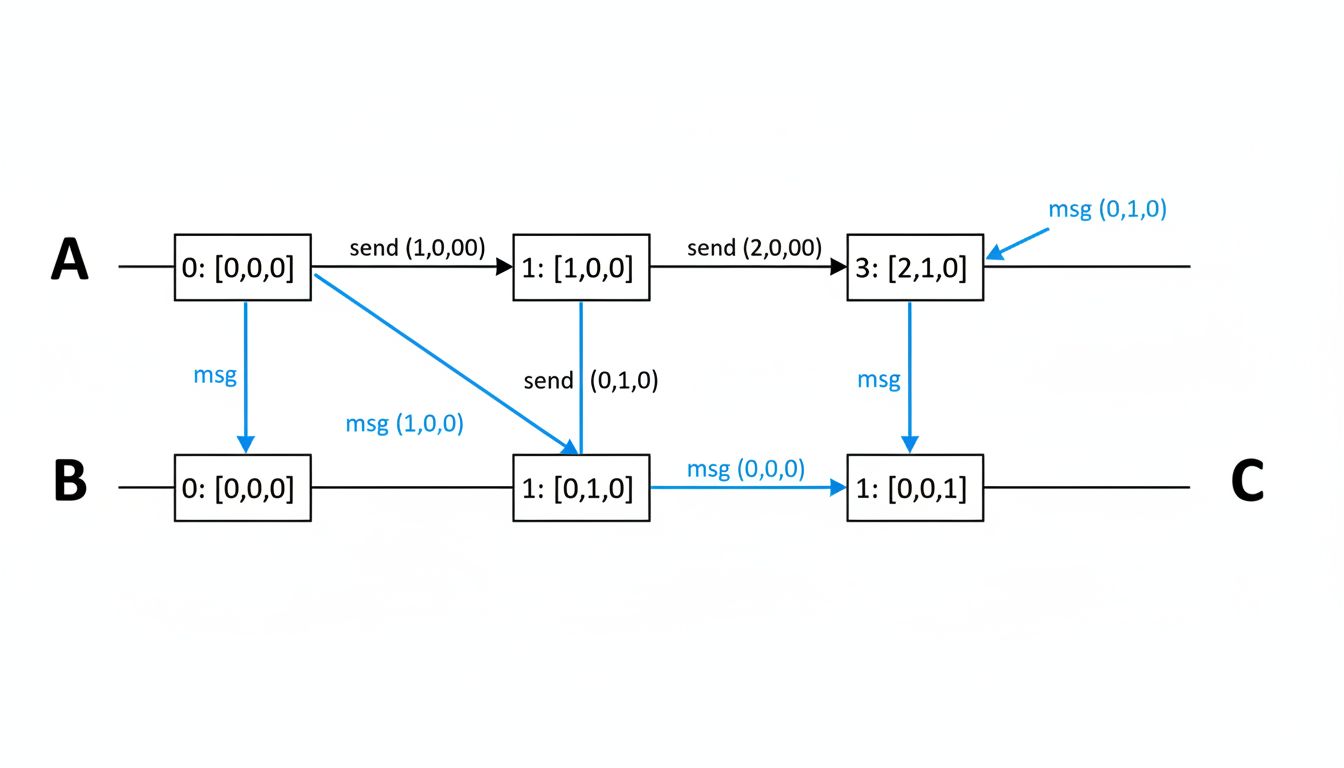
For the causal ordering problem, the real fix, they implemented vector clocks for events that needed causal ordering guarantees. A vector clock is a data structure that tracks not just when something happened but what the recording system knew about other systems’ states at that moment. It’s more expensive than a simple timestamp. It’s also actually correct, which a simple timestamp is not.
The broader lesson isn’t just about timestamps. It’s about the gap between what a data field looks like and what it actually represents. A timestamp column in a database table looks like a fact. It is a measurement, with all the imprecision that implies. When that measurement is used to make ordering decisions, that imprecision propagates into the logic built on top of it. This is similar to how race conditions often hide behind assumptions that feel safe but aren’t: the assumption is that concurrent events happen in a deterministic order, when in reality the order depends on timing you don’t control.
The audit trail failure cost the company a client relationship and months of engineering time. A more complete accounting would also include the invisible cost of decisions made on wrong data before anyone noticed something was wrong. Disputes that weren’t raised, patterns that looked real but were artifacts of clock skew, analysis built on a foundation that wasn’t level.
Timestamps are easy to add and hard to trust. The right posture is to decide early, for any system where sequence matters, what ordering guarantee you actually need, and then verify that your implementation provides it. If you need causal ordering, don’t use wall-clock timestamps and hope for the best. If you’re using a distributed system, measure your clock skew and make it visible. If you’re storing events for later reconstruction, record enough context that you can detect when the timestamps are lying.
The clock on your wall is right twice a day even when it’s broken. Production distributed systems don’t get that kind of grace period.