Race conditions show up in every CS curriculum. Two threads, one shared variable, a missing lock. Students encounter the classic counter increment example, nod in understanding, and move on. The problem is that this mental model covers maybe fifteen percent of the ways race conditions actually appear in production code.
The cost of that gap is not abstract. The Therac-25 radiation therapy machine, which injured and killed patients in the 1980s, had a race condition at its core. The machine’s safety interlocks could be bypassed when an experienced operator typed commands quickly enough to outrun the software’s state checks. Nobody wrote malicious code. Nobody forgot a mutex. The race was between a human and a state machine that the developers had implicitly assumed would always run to completion before the next input arrived.
That assumption, that some operation will always finish before the next one starts, is where most real-world race conditions live.
The Textbook Version Is Too Clean
The canonical race condition goes like this: two threads each read a shared counter, each increment it locally, and each write back. The final value is one instead of two. The fix is a lock or an atomic operation. Problem solved.
This framing is useful for teaching but actively misleading in practice, because it implies race conditions are about threads and shared memory. Many aren’t. They’re about time, ordering, and violated assumptions about sequence.
Consider a web application that checks whether a username is available, then creates an account with that username. If two requests arrive simultaneously, both checks pass, both inserts attempt, and one fails with a constraint violation. This is a race condition between two processes that share no memory and run no concurrent threads. The “critical section” is a database row that neither process explicitly locks.
Or consider a build system that checks whether a file exists before creating it, or a deployment script that reads a config file while another process is writing it. These are all races, and none of them involve a mutex.
Check-Then-Act Is a Pattern That Lies to You
The underlying structure of most race conditions is called TOCTOU: time-of-check to time-of-use. You verify some condition, then act on the assumption that condition still holds. Between the check and the act, the world can change.
This pattern appears everywhere once you start looking. File system operations are full of it. Linux’s access() system call checks file permissions, but if you use that result to decide whether to open the file, an attacker can swap the file between the check and the open. This is the basis of entire classes of privilege escalation exploits.
Database transactions give you tools to fight TOCTOU, but only if you understand what isolation level you’re actually operating at. Read committed isolation, the default in PostgreSQL and many other databases, does not prevent another transaction from modifying a row between two reads within your transaction. You can read a row, see a valid state, act on it, and have your action be based on data that was stale before your query returned. Serializable isolation prevents this, but most applications never request it, partly because the performance implications feel scary, and partly because developers don’t realize they need it.
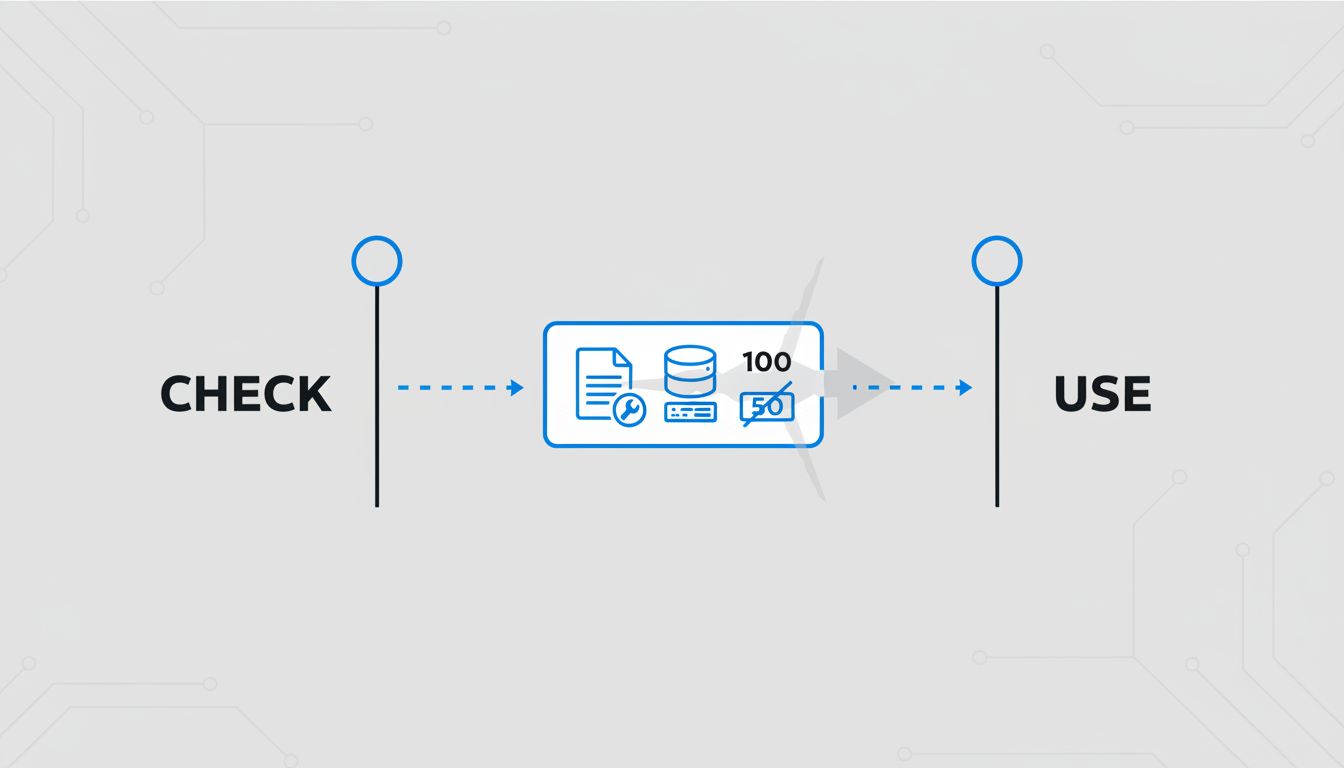
Concurrency Without Threads Is Still Concurrency
JavaScript developers sometimes feel insulated from concurrency bugs because the language is single-threaded. This is technically true and practically misleading. JavaScript has asynchronous execution, and async code is concurrent in every meaningful sense.
Consider a React component that fetches user data on mount. If the component unmounts before the fetch completes (because the user navigated away), the callback fires against a component that no longer exists. Or consider two async operations that both modify the same state variable, where the second operation starts before the first completes. Each await point is a moment where control yields, where the world can change, where your assumptions about state can become stale. The absence of threads does not give you safe ordering for free.
Go’s channel-based concurrency model, Rust’s ownership system, and Erlang’s message-passing approach all try to make these ordering assumptions explicit rather than implicit. They don’t eliminate race conditions, but they force you to think about the boundaries. Rust is particularly aggressive here: its compiler will refuse to compile code where two threads could access the same data without synchronization, which sounds restrictive until you realize how many bugs that rule prevents before they ever run. The bug that only appears when nobody is looking is often a race, and Rust is specifically designed to catch those at compile time rather than 3am in production.
Distributed Systems Turn This Into a Different Problem
Once your system spans multiple machines, race conditions become harder to even define precisely. Two servers can both believe they are the leader of a cluster. Two payment processors can both approve a transaction that should only be approved once. Two cache nodes can disagree about whether a value is valid.
The distributed version of a race condition often doesn’t look like a bug at the time it occurs. Both operations succeed. Both return 200 OK. The inconsistency surfaces later, when the data is read, when an audit runs, when a customer calls to ask why they were charged twice.
Google’s Spanner database was built specifically to handle distributed race conditions by synchronizing clocks tightly enough across data centers to make “happens before” a meaningful guarantee. The engineering involved, GPS receivers and atomic clocks in every data center, is a measure of how hard the problem actually is when correctness truly matters. Most systems settle for weaker guarantees and hope that conflicts are rare and detectable.
Why This Matters Beyond Bugs
The gap between the textbook race condition and the real one has a practical consequence: developers fix the races they recognize and miss the ones that don’t fit the pattern. A code reviewer who thinks “race condition” means “shared memory, missing lock” will not flag a check-then-act sequence in application logic. A developer who associates races with threads will not consider that their async event handlers might interleave in ways they haven’t accounted for.
The better mental model is this: any time your code reads state and then acts on that state, with any gap in between (a function call, a network request, a yield point, another process, another server), you have a potential race. Most of the time, that gap doesn’t cause a problem. But the conditions under which it causes a problem are precisely the conditions that are hard to reproduce and easy to overlook.
Race conditions are not a concurrency problem with a standard solution. They’re a category of assumption violation, and the assumption is almost always the same one: that the world stays still while you’re thinking about it.