Servers Have Been Lying About the Time for Decades
The timestamp on your database record is probably wrong. Not by much, maybe a few hundred milliseconds, maybe a few seconds, but wrong. The server that wrote it has a clock that drifts, sometimes fast, sometimes slow, governed by a cheap quartz crystal oscillating at slightly the wrong frequency. The timestamp on the next record, written by a different server in the same cluster, might be wrong in the opposite direction. If you’re building a distributed system that relies on those timestamps to establish order, you are building on sand.
This is not a niche problem. It is one of the foundational awkward realities of computing, and the industry has been paper-mâché-ing over it for forty years.
Why Every Clock Is a Bad Clock
Computer clocks are built around quartz oscillators, crystals that vibrate at a predictable frequency when voltage is applied. The frequency is predictable, but not perfectly stable. Temperature shifts it. Age shifts it. Manufacturing variance means no two crystals are identical. A typical server-grade oscillator might drift by tens of milliseconds per day under normal conditions. Over weeks and months, without correction, a server clock can fall minutes behind or race minutes ahead of real time.
This would be a manageable curiosity if computers worked alone. They don’t. Modern applications span dozens or hundreds of servers, and those servers constantly make decisions based on time: which database write came first, whether a session token has expired, how to order events in a log, whether a certificate is still valid. When the clocks on those servers disagree, the software’s model of reality diverges from actual reality.
The deeper problem is that software engineers tend to treat system time as ground truth. You call Date.now() or time.time() or whatever your language provides, and you get back a number, and that number feels authoritative. The API offers no indication that the number might be stale, skewed, or freshly adjusted by something running in the background. You are handed a confident lie.
The Protocol That Holds the Internet Together (Mostly)
The solution the industry settled on is the Network Time Protocol, NTP, designed by David Mills in the early 1980s and formalized in RFC 958 in 1985. The idea is straightforward: your computer periodically asks a time server what time it is, accounts for network latency in the round trip, and adjusts its local clock to match. Repeat often enough, and clocks across a network converge on a shared reference.
NTP is arranged in a hierarchy called strata. Stratum 0 devices are reference clocks, atomic clocks, GPS receivers, radio signals tied to national standards. Stratum 1 servers connect directly to them. Stratum 2 servers synchronize from stratum 1, and so on down the chain. Most servers in the world sit at stratum 3 or 4, synchronized through several hops from an actual atomic clock.
In practice, NTP works well enough that most people never think about it. A well-configured server on a stable network can stay within a few milliseconds of UTC. That sounds impressive until you consider what modern distributed systems require.
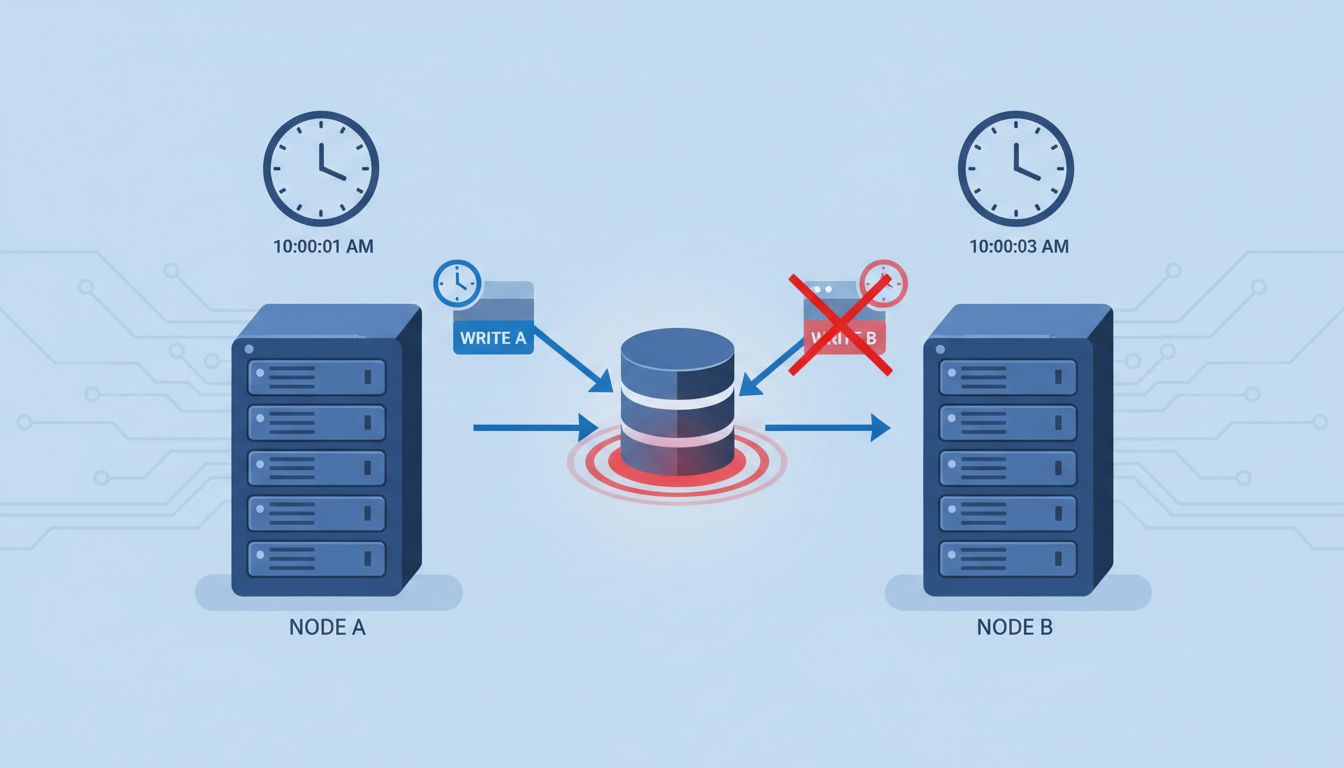
When Milliseconds Are Not Good Enough
Distributed databases make the problem concrete. Apache Cassandra, for instance, uses client-supplied timestamps to resolve write conflicts. If two clients write to the same key at nearly the same time, the one with the higher timestamp wins. This is fine in theory. In practice, if the client clocks disagree by more than the gap between the writes, the wrong write wins, silently, with no error, no warning, and no audit trail. Your data is corrupt and you have no idea.
Google addressed this problem for Spanner, their globally distributed database, by building a system called TrueTime. Rather than claiming to know the exact time, TrueTime returns an interval: the current time is somewhere between earliest and latest, where the interval is typically a few milliseconds wide. Spanner’s transaction logic explicitly waits out that uncertainty before committing, ensuring that causality is preserved even across data centers. It is a more honest API, because it admits what the system actually knows.
Google can pull this off because they run their own GPS and atomic clock infrastructure in every data center. The rest of the industry cannot. Most distributed systems simply assume their NTP-synchronized clocks are close enough and hope the assumption holds. Sometimes it doesn’t, and the resulting bugs are nearly impossible to reproduce.
Amazon’s response was the Amazon Time Sync Service, launched in 2017, which offers sub-millisecond accuracy within their cloud infrastructure using a fleet of atomic clocks and GPS receivers. Microsoft followed with similar infrastructure in Azure. The hyperscalers have effectively built private time utilities, because the public infrastructure wasn’t reliable enough for their needs.
The Political Infrastructure Nobody Talks About
The public NTP pool, the collection of servers most of the world ultimately traces back to, is a loosely organized volunteer and institutional operation. The pool.ntp.org project, started by Adrian von Bidder in 2003, coordinates thousands of servers donated by universities, ISPs, and individuals. It is a remarkable public good that has scaled surprisingly far.
But the root of the hierarchy, the stratum 1 servers tied to national time standards, depends on institutions like NIST in the United States, PTB in Germany, and NPL in the UK. These are government-funded scientific agencies. Their continued operation is not guaranteed. It is also not uniformly funded. The atomic clocks that anchor global internet time are maintained by a small number of national labs, and the coordination between them happens through a body called the BIPM, the International Bureau of Weights and Measures, which defines and maintains UTC.
This is infrastructure that almost no one in tech thinks about, tucked inside a geopolitical framework that most software engineers couldn’t name. The accuracy of every database timestamp, every TLS certificate validity window, every financial transaction record traces back, through multiple hops, to atomic clocks in a handful of government labs. The chain is longer and more fragile than it looks.
Leap Seconds: The Deliberate Disruption
Making things worse, UTC itself is occasionally adjusted. The Earth’s rotation is slightly irregular, and rather than let UTC drift from mean solar time, the IERS (International Earth Rotation and Reference Systems Service) periodically inserts a leap second, a 23:59:60 that shouldn’t exist, to keep clocks aligned with the planet.
Leap seconds have caused real outages. When a leap second was inserted in June 2012, servers running older Linux kernels hit a bug in the kernel’s timer code that caused CPU usage to spike to 100% across many systems, taking down services at Reddit, LinkedIn, Mozilla, and others. The same thing happened in June 2015. The problem isn’t the concept of a leap second; it’s that inserting one requires every piece of software that assumes 60-second minutes to handle an edge case that arrives, at most, once every eighteen months, with only six months’ notice.
In November 2022, the BIPM voted to eliminate leap seconds by 2035, replacing them with a larger, less frequent adjustment. This will reduce one category of disruption while potentially creating new ones, since any system built around the historical relationship between UTC and solar time will need updating.
The Newer Standard Most People Haven’t Heard Of
PTP, the Precision Time Protocol (IEEE 1588), is NTP’s more accurate successor for environments where the network is controlled and low-latency. Where NTP achieves millisecond-level accuracy across the public internet, PTP can achieve sub-microsecond accuracy within a data center using hardware timestamping in network switches.
Financial exchanges have adopted PTP aggressively, because high-frequency trading requires that the sequence of orders can be reconstructed with certainty. Under MiFID II regulations in Europe, trading venues are required to timestamp events to within 100 microseconds and synchronize to a traceable UTC source. NTP is not sufficient for that requirement. PTP is.
The broader tech industry has been slower. AWS offers PTP on certain instance types. Precision Time Sync is available in Azure. But most application developers still default to NTP, and most application code still treats the resulting timestamps as exact values rather than estimates with bounded error.
What This Means
The practical upshot for engineers is simple, if uncomfortable: timestamps are not facts, they are approximations, and any system design that depends on their precision should make that dependency explicit.
For distributed systems, this means preferring logical clocks or hybrid logical clocks (HLC) over wall-clock timestamps when ordering events. It means using monotonic clocks (which measure elapsed time and never go backward) for measuring durations, rather than wall-clock readings that can jump when NTP corrects a drift. It means treating any cross-machine timestamp comparison with suspicion unless you control the time infrastructure.
For everyone else, it means recognizing that the internet’s sense of time is a cooperative fiction, maintained by volunteer servers, government labs, a handful of IEEE standards bodies, and the BIPM. It works remarkably well, right up until it doesn’t, and when it fails, the failures are subtle, causality-breaking, and often invisible until long after the damage is done.
The servers aren’t lying out of malice. They’re doing their best with cheap crystals and a forty-year-old protocol. That’s almost worse.