The Blank Canvas Problem
When you write new code, you get to define the problem. You choose the data structures, the assumptions, the failure modes you care about. The context lives entirely in your head, fresh and complete. You know what you intended. You know what inputs you tested. You know which edge cases you decided weren’t worth handling.
Debugging a production bug strips all of that away. You’re working backward from a symptom to a cause across a system you may not have written, in a state you cannot fully reproduce, under conditions you can’t perfectly reconstruct. The code is fixed. The logs are partial. The user who triggered the issue has moved on.
This asymmetry is not obvious until you’ve lived it. New engineers often assume that fixing something must be easier than creating it from scratch. The mental model is intuitive: creation requires imagination, fixing just requires inspection. That mental model is wrong.
The Reproduction Problem Is Worse Than It Sounds
The first step in fixing a bug is reproducing it. This sounds like housekeeping. It isn’t. Reproducibility is the entire foundation of debugging, and production environments are systematically hostile to it.
Consider what’s different between your local environment and production: data volume, data variety, concurrency levels, network latency, dependent service versions, cache states, and the accumulated effects of months of real user behavior. A race condition that appears under load won’t show up on your laptop. A bug that only triggers on a specific combination of user account flags and feature toggles requires knowing which flags and toggles exist and how they interact. A memory issue that emerges after 72 hours of uptime requires 72 hours of uptime to reproduce.
The aerospace industry has a term for failure modes that don’t reproduce under test conditions: they call them “one-time anomalies,” and there are entire disciplines dedicated to taking them seriously rather than dismissing them. Software engineering has mostly not developed equivalent rigor. We mark bugs as “cannot reproduce” and close them, until they reappear.
Even when you can reproduce a bug, you’ve already spent the most expensive resource: time spent understanding the preconditions.
Your Mental Model of the Code Is Wrong
When you debug code you wrote six months ago, or code written by someone who left the company, you’re not reading the code as it actually runs. You’re constructing a mental model of it. And mental models of complex systems are reliably incomplete.
Research in cognitive science on how programmers understand code suggests that developers heavily rely on pattern recognition rather than careful line-by-line reasoning. This works well for familiar patterns and catastrophically for unfamiliar ones. When a bug lives in the gap between how the code looks and how it actually executes, pattern recognition leads you exactly the wrong direction.
The specific traps: implicit state that doesn’t appear in the function signature, side effects in code you assumed was pure, timing dependencies that are invisible when you read sequential code, and library behavior that differs from what you’d expect based on the function name alone.
Compilers catch a subset of these problems at build time, which is why static analysis tools find more bugs per hour than manual code review. But the bugs that make it to production are, by definition, the ones that passed all of that. They’re the subtle ones.
The Pressure Variable
Debugging in production almost always means debugging under pressure. Something is broken for real users, right now. Maybe revenue is affected. Maybe executives are watching the incident channel. Maybe the on-call rotation woke you up at 2am.
Pressure degrades exactly the cognitive capacities that debugging requires. Careful hypothesis formation, systematic elimination of variables, willingness to be wrong about your first guess, these all require deliberate thinking. Stress pushes cognition toward fast, intuitive, pattern-matching responses. The result is that engineers under pressure are more likely to fix the first plausible-looking thing rather than the actual root cause.
This explains the common pattern of production incidents where the first fix doesn’t work, the second fix doesn’t work, and by the third attempt the engineer has spent four hours and the system is in a worse state than when they started. Each “fix” was a bet on an untested hypothesis, applied directly to production because the pressure to do something was too high to wait for proper validation.
The mitigation is process: incident response frameworks exist specifically to add structure when individual judgment degrades under stress. The best engineering teams have runbooks that force the question “what is my hypothesis and how am I testing it” before any change is made. This feels bureaucratic until you’ve watched a panicked engineer take down a second system while trying to fix the first.
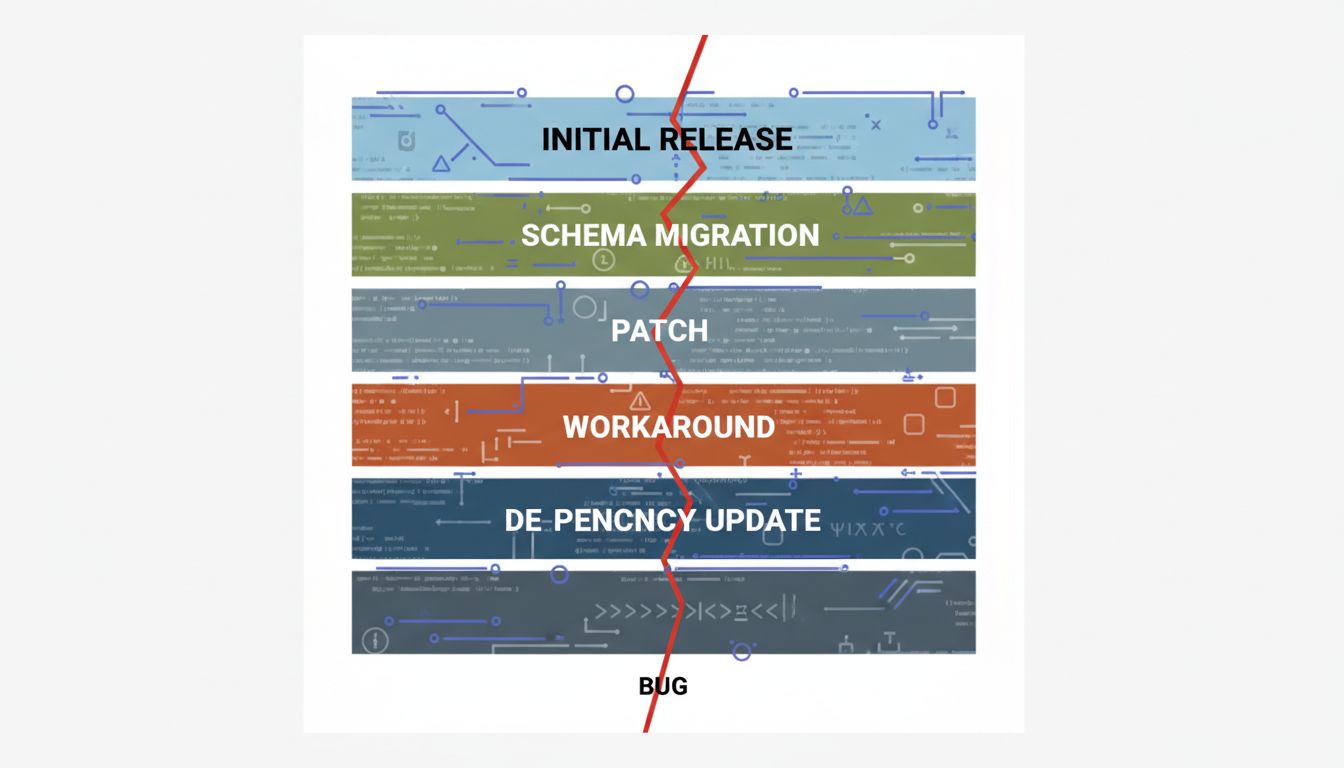
The Hidden Complexity Tax
Software systems accumulate complexity over time in ways that aren’t always visible in the code. A function that looks simple may depend on a database schema that’s been through four migrations. An API endpoint might be called by three different clients with subtly different expectations. A configuration value set years ago might interact with newer code in ways no one anticipated.
This is the complexity tax: the accumulated weight of every decision, workaround, and “we’ll fix this later” that has built up in a system since it was written. Writing new code incurs a small increment of this tax. Debugging an existing system means paying the full accumulated balance.
The canonical example is null handling. Null values spread through codebases because they’re convenient to return when something is missing, and they’re cheap to propagate. A production bug triggered by a null pointer exception often requires tracing backward through multiple layers to find where the null was introduced, why it was considered acceptable at that point, and why the consuming code didn’t account for it. The fix might be one line. Finding where that line goes might take a day.
Silent bugs are particularly vicious here because by the time symptoms surface, the original cause may be buried under months of additional writes, state changes, and system activity that obscures the trail.
Observability Is Never Good Enough When You Need It
The information you have during a production incident is whatever you thought to log before the incident happened. This is a fundamental constraint, and it’s almost always insufficient.
Logs capture what engineers thought was important. They don’t capture what turns out to matter for this specific failure. Metrics track what was being measured. Traces show what was instrumented. The bug that’s killing you right now is, by definition, something that wasn’t fully anticipated. If it had been, you’d have handled it or at least logged enough to diagnose it.
This creates a cycle: incident occurs, engineers add more logging and instrumentation to help with future incidents, system grows more observable, but the next incident is still a novel failure mode that lives in the gap between what’s instrumented and what matters.
The practical implication is that a significant portion of production debugging time is spent not analyzing evidence but collecting it. Adding a log line, deploying it, waiting for the condition to recur, analyzing the output, realizing you need more information, and repeating. This feedback loop can take hours per iteration. Writing the original code had no such constraint.
What This Means
The difficulty gap between writing code and fixing production bugs has real consequences for how engineering teams should operate.
First, the cost of a production bug is not just the fix time. It’s the reproduction time, the investigation time, the time spent adding observability, the context-switching cost for everyone pulled into the incident, and the opportunity cost of everything not built while the team is firefighting. Studies of software development costs consistently find that defects found in production are dramatically more expensive to fix than defects found during development. The range cited in the literature varies widely, but the direction is always the same.
Second, anything that reduces the gap between development and production, better local tooling, more realistic test environments, faster deployment cycles, lower cost of feature flags, makes debugging easier by making reproduction easier. This is the strongest practical argument for investment in development infrastructure. It’s not about developer happiness. It’s about the cost of the eventual incident.
Third, the engineers who are genuinely good at production debugging are rare and valuable in a different way than engineers who are good at building new things. These are partly different skills. Systematic hypothesis testing, comfort with ambiguity, ability to reason about systems under incomplete information, these are cultivated through experience and discipline, not just raw technical ability.
Writing code is hard. Fixing it in production is a different kind of hard, and underestimating that difference is one of the more reliably expensive mistakes a team can make.