The Bug You Were Sure You Didn’t Write
In 2011, the Chromium security team ran their codebase through Clang’s static analyzer. The analyzer was not new technology. It had been in development since 2007, built on top of the LLVM compiler infrastructure that Chris Lattner had started at the University of Illinois. But by 2011, it had grown sharp enough to find things that human reviewers missed routinely.
What it found in Chromium was not obscure corner-case nonsense. It found use-after-free errors, null pointer dereferences, and uninitialized memory reads in code that had been written by skilled engineers, reviewed by other skilled engineers, and tested in production. The bugs were not hiding in experimental branches. Several were in paths that ran on every page load.
This is the uncomfortable story of what happens when you give a compiler enough information to reason about your code more carefully than you reasoned about it yourself.
The Setup
LLVM started as a research project. Lattner’s original thesis work focused on building a compiler infrastructure with a cleaner intermediate representation than GCC, one that could be used for analysis and transformation as well as code generation. The academic goal was interesting but modest.
What made LLVM practically significant was Clang, the C/C++/Objective-C frontend that Apple funded starting around 2005. Apple had real grievances with GCC: the licensing terms made it hard to integrate into their tools, the codebase was difficult to extend, and the error messages were famously unhelpful. Clang was meant to fix all of that.
The error message problem got fixed first and most visibly. Clang’s diagnostics pointed at the actual source of the issue rather than a downstream symptom. That alone made developers switch.
But the deeper payoff came from what the cleaner architecture enabled: static analysis that could track state across function boundaries, reason about ownership, and follow execution paths through conditionals to find states the programmer had not considered.
The Clang Static Analyzer could not just parse your code. It could simulate it.
What Happened
When the Chromium team integrated the analyzer into their build process, they did not just find bugs. They found a category of bugs that human review had proven systematically unable to catch.
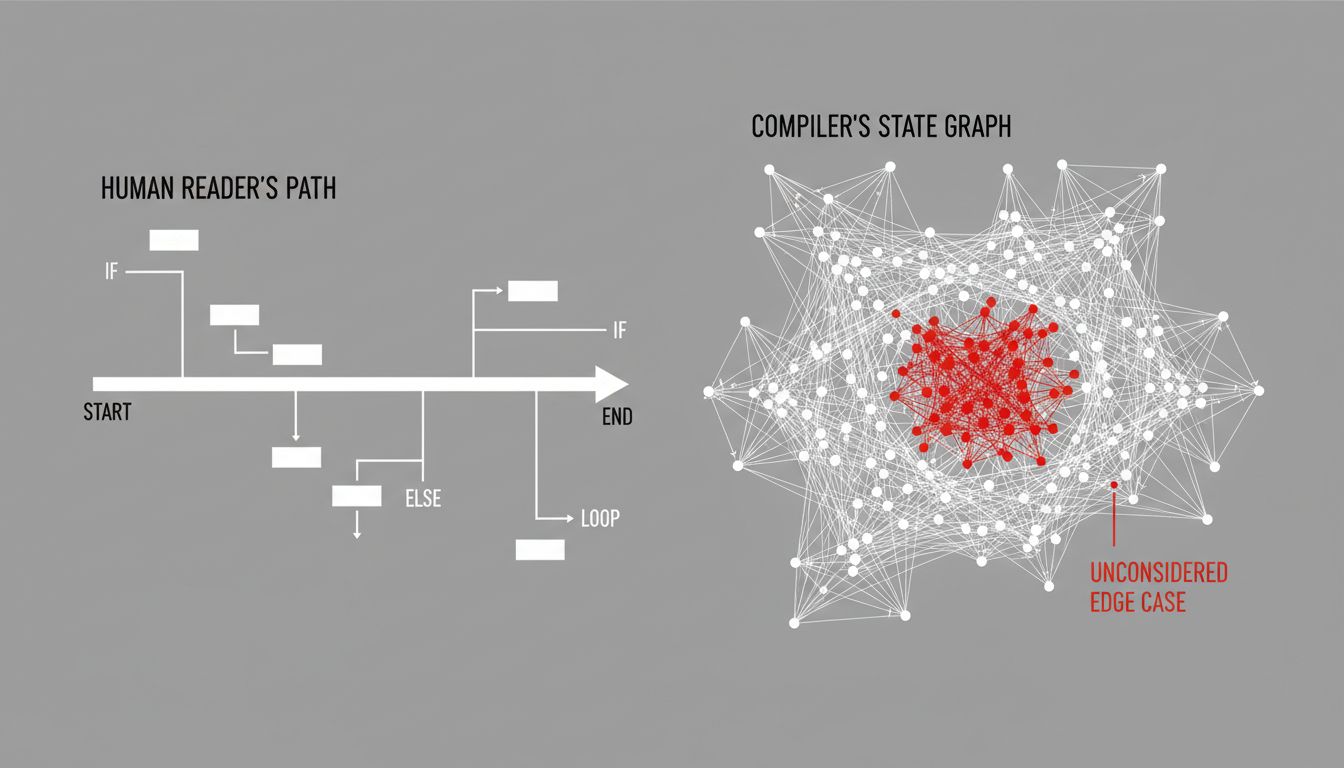
The pattern was consistent across many reports from that era: an engineer writes a function that allocates a resource, handles the success case carefully, handles several error cases carefully, and then forgets to handle one edge condition, typically a nested conditional three levels deep. The code looks right. It reads right. The reviewer, following the same mental model as the author, also reads it as right.
The analyzer does not have a mental model. It has a state machine. It follows every branch. It knows that on the path where the third condition is false and the second condition was true and the first condition checked a value that was set in the calling function, you are dereferencing a pointer you freed two stack frames ago.
This is not a superhuman capability in any meaningful sense. It is a mechanical one. The compiler is doing something humans are structurally bad at: holding every possible execution state in working memory simultaneously and checking each one against the rules.
Google eventually built this kind of analysis into their large-scale tooling across multiple languages. Their internal static analysis infrastructure, which they have written about publicly, runs continuously on submitted code and catches issues before they reach review. The friction cost of fixing a bug at submission time is a small fraction of the cost of fixing it after it has been in production.
Mozilla ran a similar exercise on Firefox. The results were similar: real bugs, real categories, real patterns that skilled engineers had been reliably missing for years.
Why It Matters
The lesson here is not that engineers are bad at their jobs. The lesson is more specific and more useful than that.
Humans reason about code narratively. We read a function and construct a story about what it does. That story is anchored to the happy path, the path the author intended. We check the error cases we thought of when we wrote it. We are not simulating a state machine. We are reading prose and inferring intent.
This works remarkably well most of the time, which is why we trust it. And the cases where it fails are exactly the cases where our trust is highest, the ones where the code does what we meant it to do on every path we bothered to consider.
The analyzer does not infer intent. It only reads what is there. That is both its limitation and its power.
Modern compilers have extended this principle considerably. Rust’s borrow checker is the most aggressive mainstream example: it refuses to compile code where the ownership model is ambiguous, catching entire categories of memory errors at compile time rather than at runtime. This is not magic. It is the compiler holding a stricter model of your program’s state than you held when you wrote it.
The friction this causes is real and well-documented. Developers new to Rust describe fighting the borrow checker as a significant part of early learning. But the fights are almost always with real bugs, cases where the mental model was wrong, not cases where the compiler is being unnecessarily pedantic.
What We Can Learn
The practical lesson for teams is straightforward: trust static analysis more than you trust code review for mechanical correctness, and treat the two as doing different jobs.
Code review is excellent at catching design problems, logic errors that require understanding the business context, missing cases that the reviewer thinks of that the author didn’t, and code that is technically correct but impossible to maintain. Humans are good at this. The narrative-reading mode is actually an asset here.
Static analysis is excellent at catching the mechanical errors that fall outside the paths you thought about. It is not trying to understand your intent. It is trying to find states you did not consider. Silent bugs are often the ones that do the most damage before anyone notices, and they tend to live exactly in those unconsidered states.
The mistake many teams make is treating static analysis as a box to check rather than a genuine source of information about their code. An analyzer warning that gets suppressed with a comment is an engineer asserting that their mental model is more reliable than the state machine. Sometimes that assertion is correct. Often it is not.
The deeper point is about epistemic humility with respect to your own code. Confidence is not the same as correctness. The fact that you wrote it and reviewed it and tested it and it mostly works does not mean you have a complete model of what it does. The compiler has read every branch. You probably haven’t.
Lattner once described the goal of good compiler infrastructure as making the machine a collaborator rather than a translator. That framing has aged well. The best argument for investing in your toolchain is not that it makes you faster, though it often does. It is that it gives you a second reader that never gets tired, never anchors to your intent, and will cheerfully follow your code into every dark corner you decided not to think about.