In 2021, Epic Systems integrated a sepsis prediction model into its electronic health record software and deployed it across dozens of hospital systems. The model had been trained on Epic’s own data and came with probability outputs, a numeric score that told clinicians how likely a given patient was to develop sepsis. High score, intervene. Low score, monitor.
The University of Michigan Medicine ran a prospective study on that model and published results in 2023. The model’s positive predictive value was around 12 percent. That means for every 100 high-confidence alerts the system flagged, roughly 88 patients did not actually have sepsis. The model was confident. It was also wrong most of the time.
This is not a story about one bad model. It is a story about a category error that the entire industry keeps making.
What a Confidence Score Actually Measures
When a machine learning model outputs a probability, say 94% confidence, most people interpret that as: “the model believes there is a 94% chance this answer is correct.” That is not what it means.
What it actually measures is something closer to: how strongly does the activation pattern of this input resemble the patterns the model associated with this output during training? Confidence is a measure of similarity to training data, not a measure of correctness in the real world.
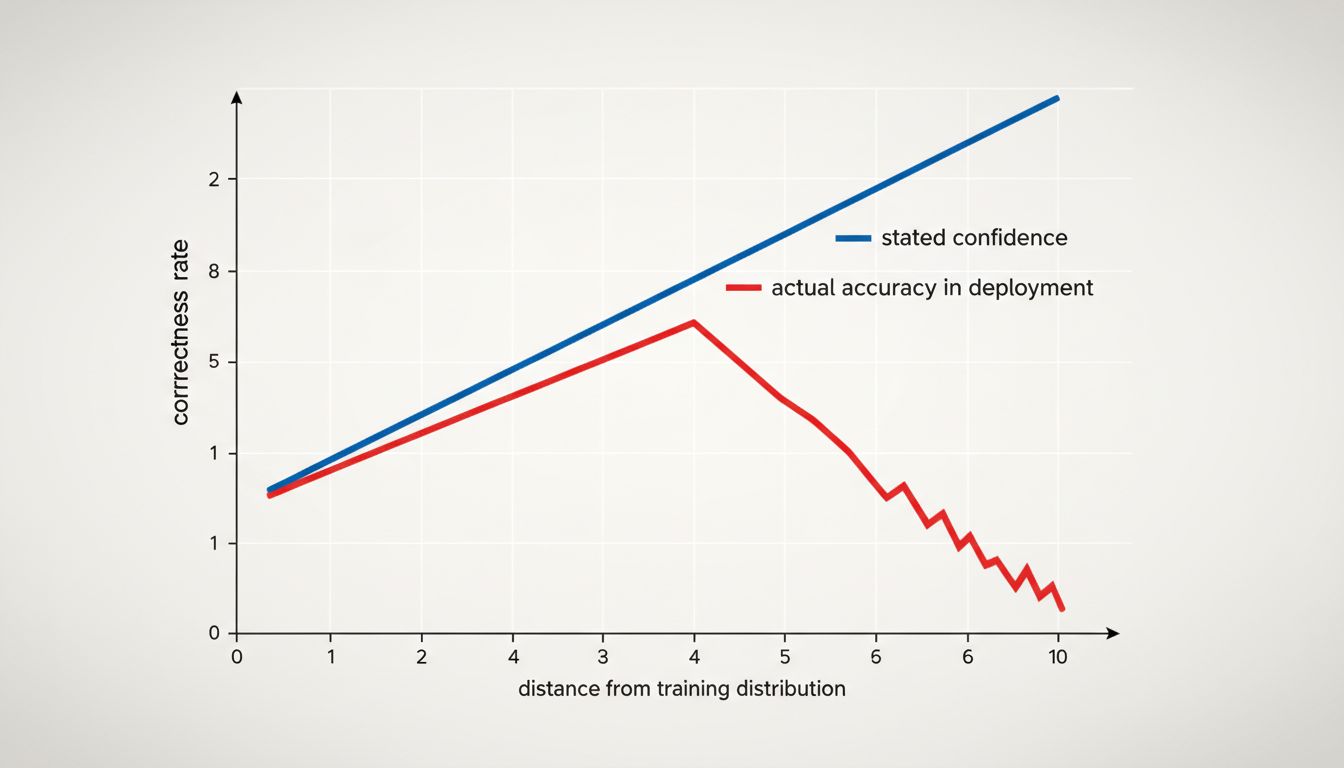
The gap between those two things is enormous, and it grows in exactly the situations where you most need reliability. A model trained on hospital records from large academic medical centers will express high confidence when it sees a patient who looks like patients from those hospitals. When that same model encounters a community hospital patient with a different demographic profile, different comorbidity mix, or different documentation style, the model’s internal representation of the world no longer matches reality. But the confidence score does not automatically reflect this. The model has no mechanism to say “this input looks like my training data but I suspect my training data was unrepresentative.”
The Calibration Problem
There is a technical concept called calibration that describes how well a model’s stated probabilities match actual outcomes. A perfectly calibrated model that says “70% confidence” should be right 70% of the time across many such predictions. Many production models are not well-calibrated, and the ones that are calibrated on their test set often drift when deployed to a different population.
Epic’s sepsis model illustrates this precisely. The model was likely reasonably calibrated on the data distribution it was trained and validated on. But deployed across a broader, messier set of hospital environments, the calibration fell apart. The 80% confidence alerts were not right 80% of the time. They were right roughly 12% of the time.
This is not unique to healthcare. Language models have the same fundamental structure. When GPT-4 states something confidently, it is expressing that the token sequence it is generating closely matches patterns in its training corpus. It has no epistemic access to whether those patterns reflect ground truth. Research teams at DeepMind, Google, and several universities have shown that large language models are systematically overconfident on questions where training data was scarce, contradictory, or outdated. The model does not know what it does not know. It just generates the next token.
If you want to go deeper on how that generation process actually works, the piece on chain-of-thought prompting covers some of the underlying mechanics in useful detail.
What Epic and Its Hospital Clients Should Have Done Differently
The Michigan study is valuable not just as a cautionary tale but as a template for how to actually evaluate AI confidence. The researchers did something simple: they tracked the model’s high-confidence predictions against actual outcomes over time in their specific patient population. They did not trust the validation metrics from the original training context. They re-evaluated in deployment.
This is the key move most organizations skip. They see a model with a 92% AUC on a benchmark, deploy it, and treat the confidence scores as meaningful. They are not. A confidence score is only meaningful relative to a base rate in your specific context with your specific data distribution.
For the hospitals running Epic, the practical corrective would have been to measure the positive predictive value of high-confidence alerts in their patient population before rolling out any clinical protocol that depended on those alerts. That measurement takes weeks, not years. They had the outcome data. They needed to look at it.
For software teams deploying language models, the corrective is similar: identify the categories of queries where your model tends to fail, and test those specifically. Do not assume that a model’s stated confidence maps to correctness. Build your own ground truth on your own data.
The Broader Lesson
There is an uncomfortable corollary here. If you cannot trust confidence scores, what do you do with them? The answer is: use them as one signal among several, and never as a binary gate.
High confidence from a model should trigger one question: is this input similar to the training distribution? If yes, the confidence is somewhat informative. If no, the confidence score is noise dressed up as signal. The problem is that most systems have no easy way to answer that question in real time.
Some newer approaches help. Conformal prediction, an approach that provides statistically valid prediction intervals rather than point probabilities, gives you coverage guarantees that raw confidence scores do not. Retrieval-augmented systems can surface the source documents behind a prediction, letting a human assess whether the retrieved context is actually relevant. Ensemble methods that show disagreement across multiple models are more honest about uncertainty than any single model’s output.
None of these are perfect. All of them are better than treating a softmax output as a percentage chance of being right.
The broader issue is that the AI industry has an incentive to make its outputs look decisive. A model that says “I think this might be sepsis, probability 94%” sounds more useful than one that says “I have no reliable way to tell you how accurate this prediction is in your hospital.” The second version is more honest. It is also harder to sell.
Medical AI is just the highest-stakes version of a problem that shows up everywhere: in fraud detection systems that are confident about edge cases they have never seen, in recommendation engines that express certainty about niche content, in code generation tools that produce plausible-looking but broken implementations with no hesitation. The AI writing your code cannot tell if it works, and neither can its confidence score.
The number a model puts next to its answer is not a probability in any meaningful Bayesian sense. It is a measure of pattern similarity to training data. In familiar territory, that distinction barely matters. In the territory where your actual hard problems live, it matters enormously.