
Deploying a model to production is not the finish line. It is the starting gun for a completely different race, one that most teams are not trained for and not watching closely enough.
The machine learning community has built excellent tooling for training, evaluation, and benchmarking. What it has not built is a widespread culture of honest reckoning with what happens after. The result is a persistent, expensive illusion: that a model which performs well in testing will perform well in the world. It usually does not, and the gap is not random noise. It is structural.
Your Evaluation Set Is Already a Lie
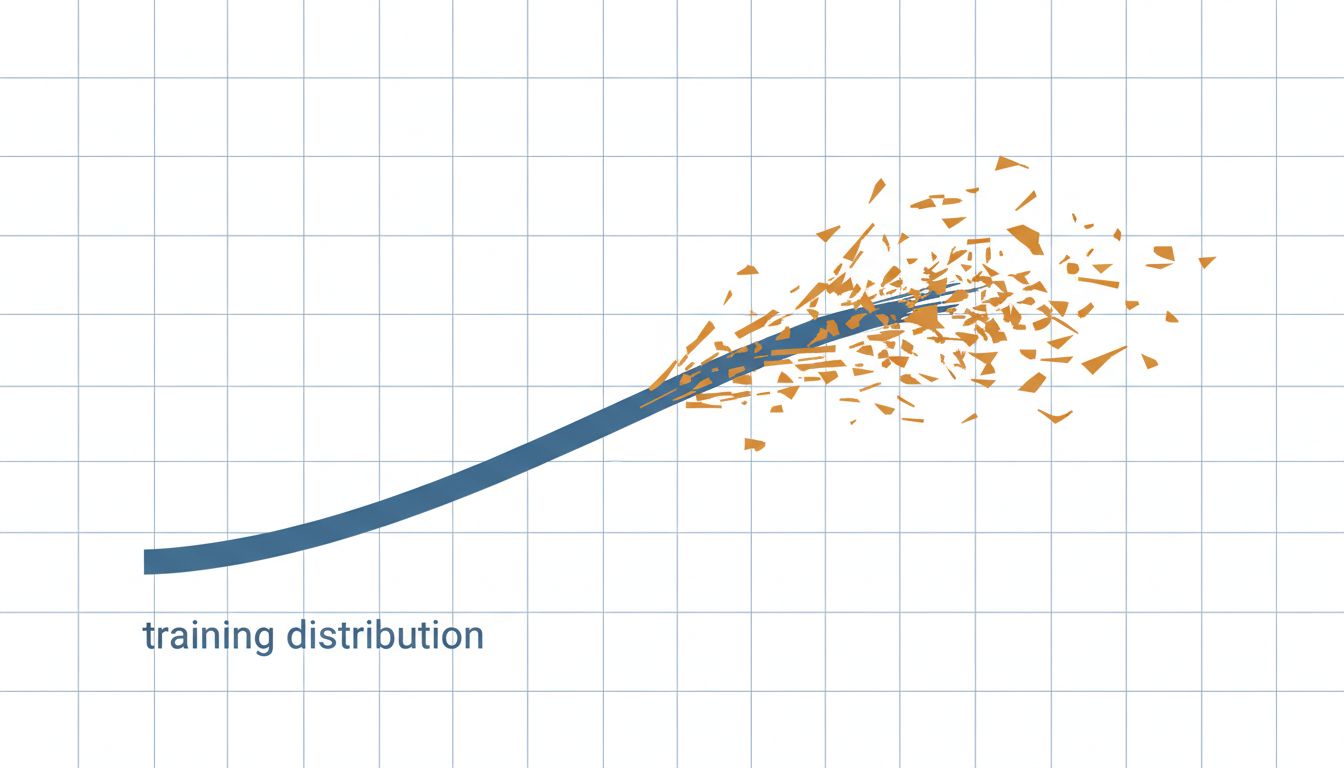
When you evaluate a model before deployment, you are measuring it against a snapshot of the world. The moment you ship, the world starts moving and your snapshot does not. This is called distribution shift, and it is not a rare edge case. It is the default.
User behavior changes. Language evolves. The product around the model changes. Seasonal patterns emerge that no one thought to include in training data. A customer support model trained on last year’s tickets will quietly degrade as your product ships new features that generate entirely new categories of complaint. Your evaluation metrics stay green. Your users start getting worse answers. Nobody notices for weeks.
The fix is not a better evaluation set, though that helps. The fix is continuous monitoring tied to real outcomes, not just model-internal metrics. You need to know when the distribution your users are generating diverges from the distribution your model was built for.
Latency at the 99th Percentile Will Surprise You
Benchmark numbers are averages. Production systems live and die by tail latency. A model that returns results in 200 milliseconds on average might take three seconds for a meaningful slice of requests, and that slice is often not random. It is frequently your most complex queries, which tend to come from your most sophisticated users.
This is not a new problem in software, but it hits harder with ML systems because inference latency is harder to reason about than traditional compute. Input length, batch size, hardware contention, and model architecture all interact in ways that are difficult to predict without load testing that genuinely mirrors production traffic. Fast benchmark numbers do not translate directly to a fast application, and the gap tends to widen exactly when you need the system to perform, under peak load.
Before you ship, run realistic load tests. After you ship, instrument the 95th and 99th percentile latencies separately from the mean. Treat tail latency as a first-class metric.
Cost Curves Are Non-Linear and They Will Catch You
A model that costs $200 a month in staging will not cost $200 a month at ten times the traffic. This is obvious when stated plainly, but teams routinely fail to model it correctly because inference costs scale with usage in ways that interact with pricing tiers, caching behavior, and whether you have invested in prompt optimization.
The math gets uncomfortable fast. If you are calling a frontier model API for every user request, your unit economics at scale may be fundamentally broken. You will not discover this from a staging environment. You will discover it from a billing alert, or worse, from a board meeting.
Cost forecasting for ML systems requires you to think about your most expensive request type, not your average request. Model the ceiling, not the floor.
Feedback Loops Will Corrupt Your Data
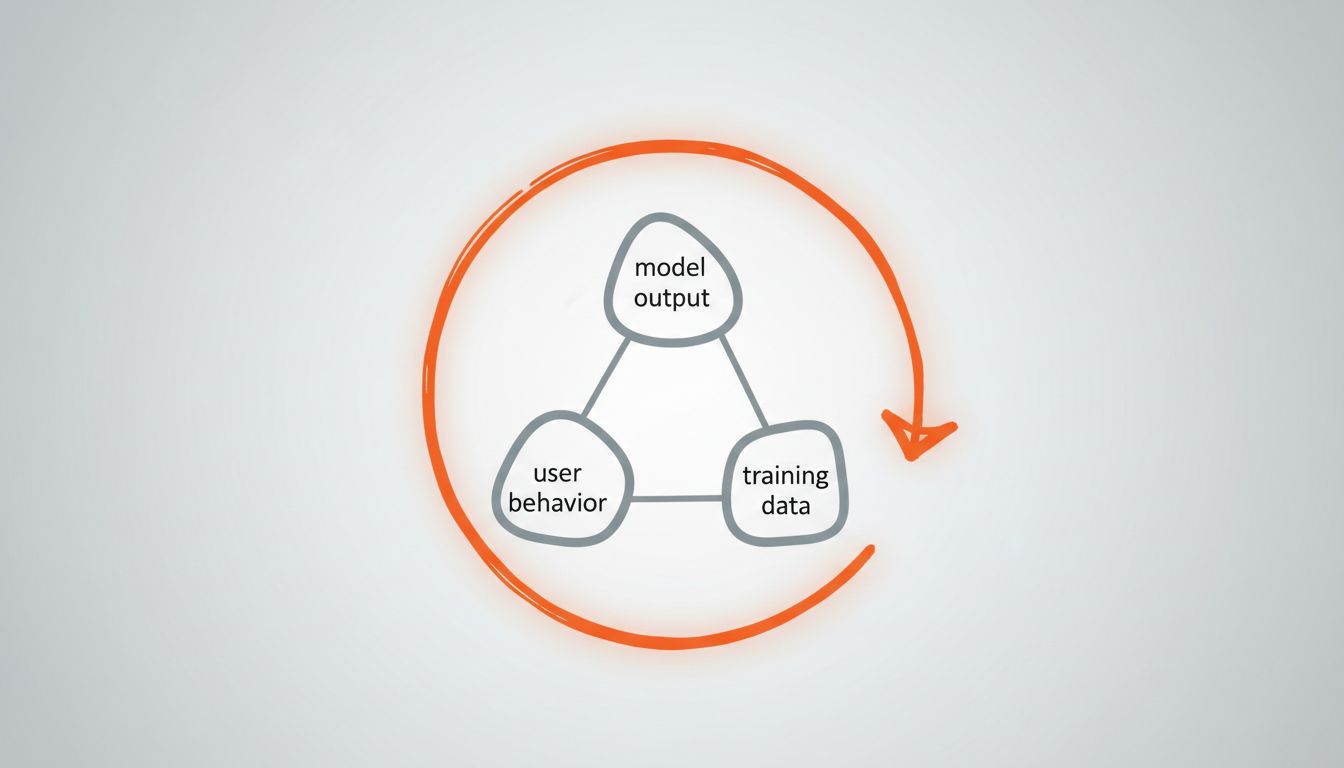
Once your model is in production, it starts influencing the data it will eventually be trained on. A recommendation model changes what users see, which changes what users click, which changes what future training data looks like. A content moderation model shapes what content gets posted. A code completion tool shapes how developers write code in ways that will show up in future fine-tuning datasets.
This is not hypothetical. It is a documented phenomenon in deployed ML systems, and it creates a slow drift that is almost invisible in short-term evaluation windows. You need to think about this before you deploy, because the architecture decisions that protect against feedback loop corruption are much harder to retrofit than to build in from the start. Hold out data that the model cannot influence. Track the statistical properties of your training pipeline over time.
The Counterargument
Some teams will push back and say that the answer is just to iterate quickly. Ship fast, watch the metrics, fix problems as they emerge. This is not wrong, exactly. But it assumes you have the observability infrastructure to catch problems when they emerge, and most teams deploying their first or second model do not. The issues described above are not loud failures. They are the kind that accumulate quietly while your dashboard stays green. By the time they surface, you have six months of degraded outputs in production and a confused user base.
Fast iteration is a good strategy. Fast iteration without instrumentation is just fast guessing.
What You Should Actually Do
The position here is simple: treat deployment as the beginning of an operational commitment, not the end of a development project. That means monitoring real outcomes, not just model metrics. It means load testing against realistic traffic before you ship. It means building cost models that account for your worst-case request, not your average one. And it means designing your data pipelines so that your deployed model cannot silently corrupt its own future training data.
None of this is especially complicated. Most of it is just applying operational discipline that good software teams already know to a domain that tends to attract people who are more comfortable with training runs than with on-call rotations. The two skillsets need to coexist, and the sooner your team acknowledges that, the less painful your production experience will be.





