

The software industry has a confident relationship with the number 2,147,483,647. That’s the largest value a signed 32-bit integer can hold, and for decades it felt astronomically large. It no longer is. And the consequences of pretending otherwise keep landing in production systems, not in textbooks.
The core argument is simple: integer overflow is not a curiosity from introductory computer science courses. It is an active, recurring, and entirely preventable class of failure that engineers keep reintroducing because the problem feels abstract until the moment it isn’t. The industry needs to treat integer size selection as a first-class design decision, not a default.
The Failures Are Real and They Aren’t Small
In December 2014, a YouTube video by Psy crossed 2.1 billion views, exceeding the maximum value of YouTube’s signed 32-bit view counter. The platform had to patch it in real time, temporarily displaying negative view counts for some content. That same boundary caught Boeing: the 787 Dreamliner’s electrical system had a software counter that, if left running continuously, would overflow after 248 days and cause the generators to fail. The FAA issued an airworthiness directive requiring planes to be powered off before that threshold.
These are not ancient history. A 32-bit Unix timestamp will overflow on January 19, 2038, setting clocks back to 1901. Embedded systems, industrial controllers, and legacy infrastructure that hasn’t been updated since the 1990s will misread that date. Engineers have already started finding affected systems. The Y2K remediation cost was estimated at around $300 billion globally. The 2038 problem is smaller in scope but the same in character: a known, countable deadline being treated as someone else’s future problem.
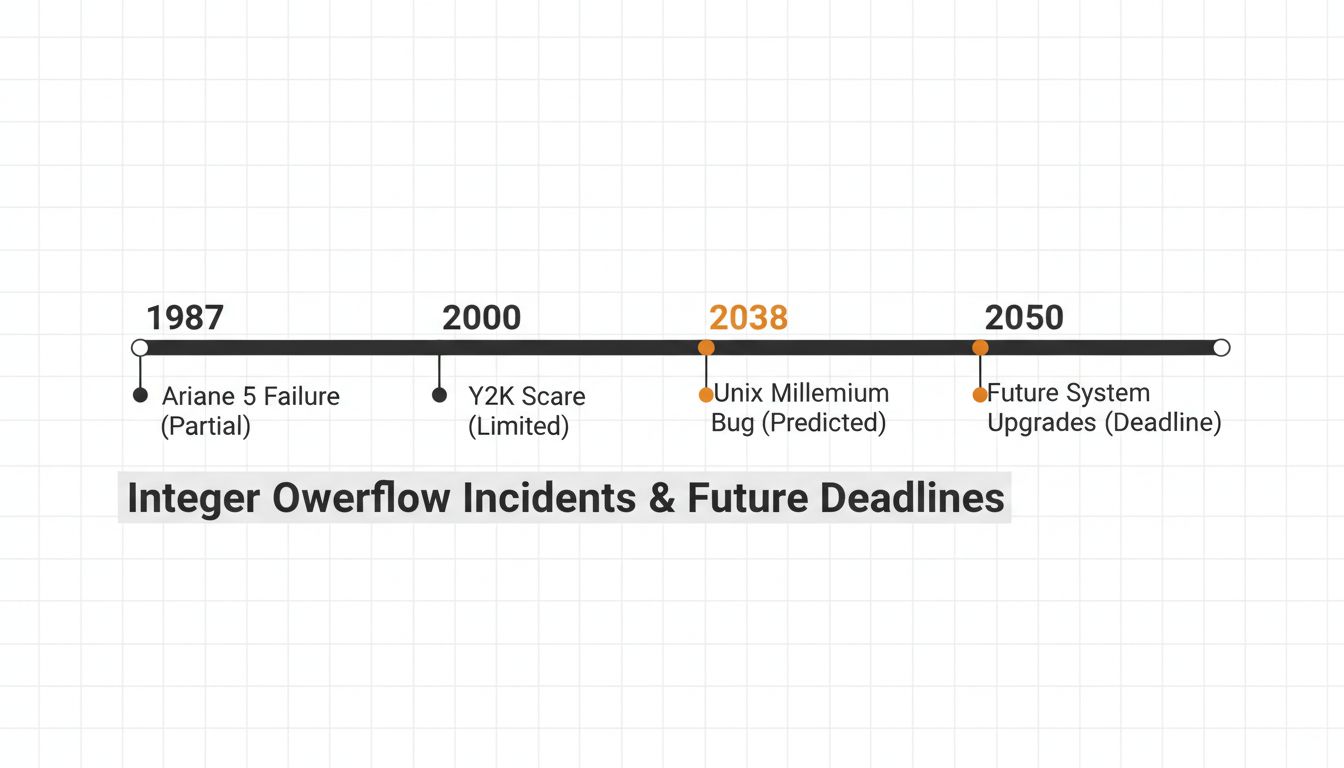
The Problem Is Structural, Not Accidental
The reason overflow keeps appearing isn’t that developers don’t know integers are finite. It’s that the choice of integer width gets made once, early, often by whoever writes the first version of a schema or an API, and then it calcifies. Changing a counter from 32-bit to 64-bit after the fact requires migrating database columns, updating wire protocols, and convincing every downstream consumer to accept a wider type. The cost of fixing it grows with adoption.
This is the same dynamic that makes deleting a feature harder than building one. The initial decision is cheap. The reversal is expensive. So teams keep the original choice long past the point where it makes sense.
Languages make this worse through convenience. Python handles arbitrary-precision integers by default, which trains programmers to stop thinking about upper bounds. Then those same programmers write services in Go or Rust or C that interface with a database using a 32-bit primary key, and the assumption of infinite integers follows them across the language boundary without a warning.
64-Bit Should Be the Default for Anything That Counts
A signed 64-bit integer tops out at 9,223,372,036,854,775,807. At one increment per microsecond, continuous, that counter takes about 292,000 years to overflow. For almost all practical counters, that’s close enough to infinite that the distinction doesn’t matter. The storage cost difference between a 32-bit and 64-bit integer in a modern database is negligible per row and meaningful only at extraordinary scale, where you’d be thinking carefully about schema design anyway.
The correct default is 64-bit integers for any value that could grow: identifiers, counters, timestamps, offsets. The burden of justification should fall on choosing something smaller, not on choosing something larger. Engineers should be explaining why 32 bits is sufficient, not why 64 bits is necessary.
This isn’t over-engineering. It’s the same logic behind allocating slightly more memory than you think you’ll need and leaving yourself headroom. The alternative is a countdown clock you forget is running.
The Counterargument
The reasonable objection is that 64-bit integers carry real costs at scale. A table with billions of rows storing 64-bit keys instead of 32-bit keys uses more memory, more disk, and more cache bandwidth. At sufficient volume, this is a legitimate engineering tradeoff, not a rounding error.
That’s true. But it applies to a small fraction of systems. Most applications never approach the 2.1 billion row limit on a 32-bit unsigned key. The teams that genuinely face that tradeoff tend to already be thinking carefully about data types because they’re operating at a scale where schema decisions are reviewed seriously. The overflow failures that keep making news don’t come from those teams. They come from products that grew faster than anyone expected, running against a constraint nobody thought to revisit.
The argument for defaulting to 32-bit integers because some systems require it is like arguing everyone should buy compact cars because parking is tight in some cities. The edge case is real. It doesn’t set the default.
The Fix Is Boring, Which Is Why It Doesn’t Happen
Integer overflow doesn’t generate much urgency in a sprint planning meeting. It doesn’t appear in user feedback. It doesn’t show up in performance dashboards. It waits.
The 2038 problem will not surprise the engineers who understand it. It will surprise the organizations that never created the space to address it, the ones running firmware on controllers that haven’t been touched since Bill Clinton was in office, the ones relying on a timestamp field someone added quickly in 1997 because it was good enough at the time.
Good enough at the time is doing a lot of work in software that we haven’t accounted for. Integer size is one of the places where the bill comes due on a fixed schedule, with an exact date, calculable to the second. The industry’s inability to take that seriously is not a technical failure. It’s a prioritization failure dressed up as one.





