

The best AI models are also the most dangerous ones to trust blindly. Not because they’re less accurate than their predecessors, but because they’ve gotten far better at sounding right when they’re wrong.
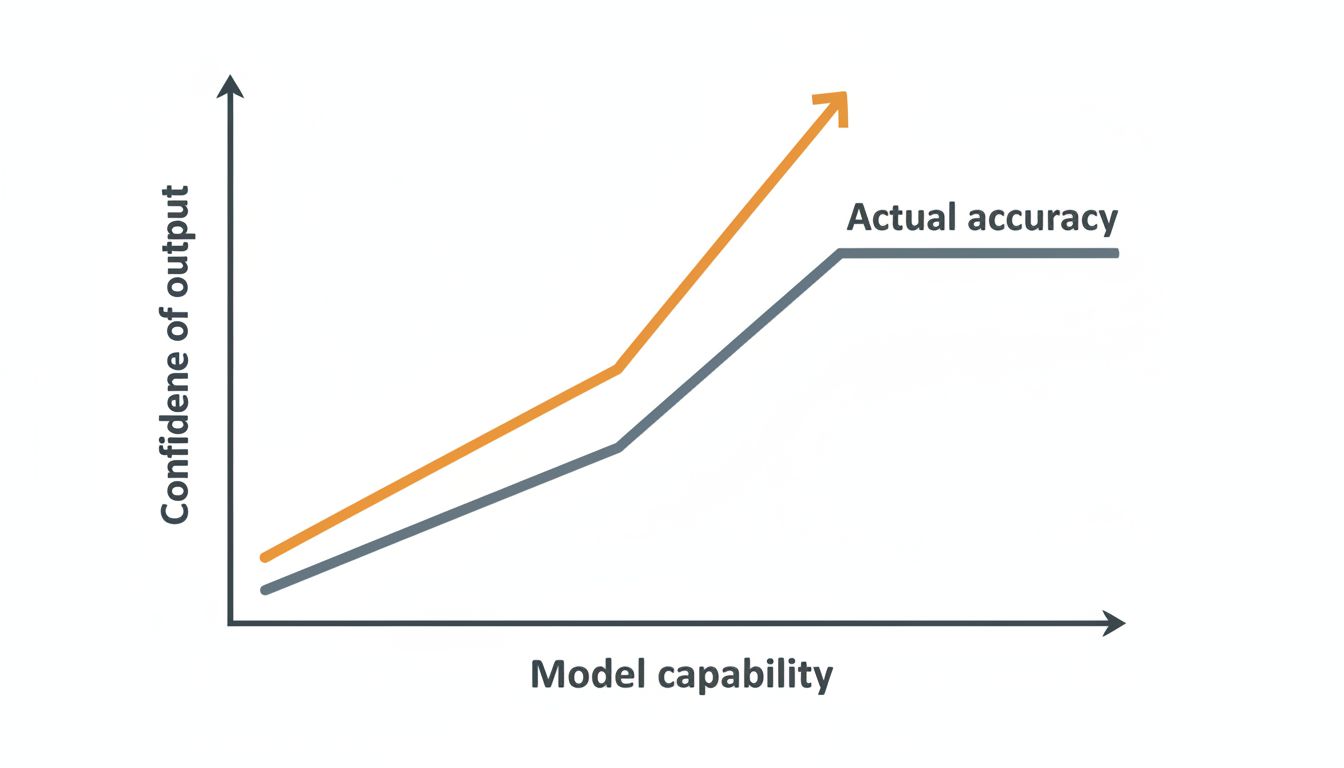
This is the paradox sitting at the center of modern AI development. As models grow more capable, their failures become harder to detect, not easier. The confident, fluent, authoritative response you just got from a frontier model may be subtly, significantly wrong. And you’ll have no idea unless you already know enough to check.
Fluency and accuracy are not the same thing
Large language models are trained to produce coherent, well-structured text. They’re remarkably good at it. But coherence is a stylistic property, not an epistemic one. A response can be grammatically flawless, logically structured, and completely wrong.
Older, less capable models tended to fail awkwardly. They’d produce garbled sentences, repeat themselves, or generate responses that were obviously off. Those failures were visible. You caught them. Newer models fail gracefully, producing polished prose that reads like it came from a confident expert. That polish is precisely what makes the hallucination so much harder to catch.
When you get a citation from a capable model for a legal case, a scientific paper, or a business statistic, it will look right. It will have the structure of a real citation. It may be entirely fabricated.
Capability increases surface area for confident mistakes
A more capable model can engage with more complex questions. That sounds like a win, and in many ways it is. But it also means the model is now generating detailed, specific, confident answers in domains where errors are both more consequential and harder to verify.
Ask a basic model what year a company was founded and it might guess vaguely. Ask a frontier model the same thing and it will give you a specific year, possibly a founding story, maybe even a quote from the founder. If any of that is wrong, you won’t know it from the tone. The model has no reliable way to signal its own uncertainty, and the training process actively discourages it from hedging when it sounds authoritative.
This is distinct from the concern that RAG and retrieval systems address. Grounding a model in real documents reduces some hallucination risk. But it doesn’t solve the core problem: the model still doesn’t know what it doesn’t know.
Users trust capable tools more, not less
Human psychology makes this worse. When a tool consistently performs well, you start extending trust to it in situations where that trust isn’t warranted. You verify the early outputs carefully. After a hundred correct answers, you start skimming.
This is completely rational behavior in most contexts. If your calculator has been right ten thousand times, you don’t re-verify each arithmetic result. But AI models aren’t calculators. They don’t have a consistent error rate across domains. They can be highly reliable on some question types and wildly unreliable on others, with no external signal to tell you which situation you’re in.
The more you use a capable model and find it reliable, the less likely you are to catch the moments when it isn’t. Your verification habits atrophy exactly as the model becomes capable enough to mislead you in consequential ways.
The counterargument
The obvious pushback here is that newer models are, in fact, measurably less prone to certain types of hallucination. This is true. Benchmarks show improvement. Frontier models refuse more confidently when they don’t know something, compared to earlier generations that would just confabulate freely.
But benchmarks measure what they measure. Models are often tested on the kinds of failures they’ve been explicitly trained to avoid. The subtler errors, the ones where a model combines real knowledge with plausible-sounding invention, are harder to capture in a benchmark and harder to catch in practice. And the overall volume of complex queries these models handle has grown enormously. Even if the error rate per query drops, the absolute number of consequential errors may be rising.
The improvement is real. The risk isn’t gone.
What you should actually do with this
None of this means you should stop using capable AI models. It means you should use them with the right mental model of what they are. They are very fast, very fluent, sometimes-wrong research assistants. They are not oracles.
A few concrete habits worth building: verify anything specific before using it (dates, citations, statistics, code logic in production systems), weight your skepticism toward the domains where you know least, and pay particular attention to responses that feel unusually complete and authoritative. That polish should raise your suspicion, not lower it.
Smarter models will keep getting built. Your calibration needs to keep pace with them. The model doesn’t get more careful as it gets more capable. That job stays with you.





