
The simple version
A stateless system doesn’t remember anything between requests. That sounds simple, but it means all the memory has to live somewhere else, and “somewhere else” is where the hard problems start.
What stateless actually means
When we say a system is stateless, we mean that any single unit of processing (a function, a server, an API endpoint) handles each request as if it’s never seen you before. No session, no history, no context carried over from the last call. You hand it everything it needs, it does the work, it returns a result, and it forgets you exist.
The canonical example is HTTP. The protocol itself is stateless. Your browser sends a request, the server responds, and the connection closes. The server has no inherent memory of that exchange. This is why cookies were invented: not to add features, but to paper over a fundamental limitation. Every time your browser talks to a server, it re-introduces itself by sending a cookie. The server looks up who you are. The illusion of a continuous session is reconstructed from scratch on every single request.
That reconstruction is not free.
Where the complexity goes
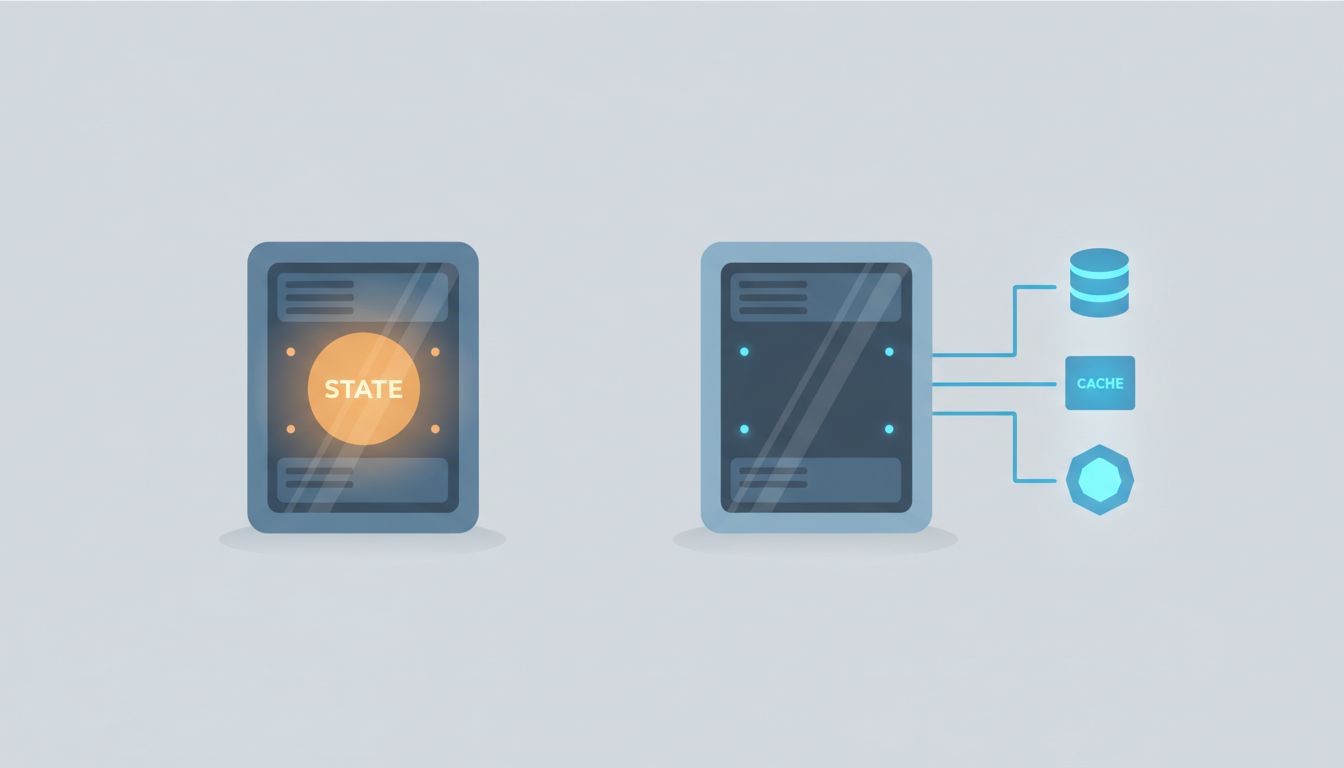
Here’s the thing that gets glossed over in most architectural discussions: stateless systems don’t eliminate state. They relocate it.
Imagine a login flow. In a stateful system, the server keeps a session object in memory. It knows you’re logged in. In a stateless system, that knowledge has to exist somewhere the server can find it on demand, which usually means a database lookup, a cache hit against something like Redis, or a cryptographically signed token (a JWT) that gets passed back and forth on every request.
All three of those approaches introduce their own complexity. The database lookup adds latency and a dependency. The cache introduces invalidation problems (what happens when you change someone’s permissions, but their token doesn’t expire for another hour?). The signed token means you need to manage signing keys, rotation schedules, and the fact that you can’t revoke a valid token without building additional infrastructure to track revocations.
You didn’t remove the complexity. You unpacked it into problems that live in different places, which is sometimes better and sometimes worse, depending on your situation.

Why stateless became the default recommendation
For most of the last decade, stateless architecture has been the default recommendation for backend systems, and the reasoning is genuinely good. If your servers don’t hold any session state, you can spin up ten more of them and route requests to any of them without coordination. Horizontal scaling becomes straightforward. You can kill and replace individual servers without users noticing. Deployment gets cleaner because there’s nothing to migrate.
This is the legitimate value. Stateless design makes certain operational problems much easier, particularly at scale. This is why REST APIs are designed to be stateless, why serverless functions are stateless by definition, and why the microservices movement leaned so hard into the pattern.
But notice what all of those gains are: they’re operational gains. They make infrastructure management easier. They say nothing about the logical complexity of the system, which is determined by what the system actually does, not how its servers are arranged.
A stateless function that processes a JWT, validates its claims, checks a permissions database, and reconstructs a user session on every request is not a simple function. It’s a function with complex behavior that happens to not hold local state.
The places this misunderstanding causes real problems
The most common place I see this confusion cause trouble is in AI and ML systems. Large language models are themselves stateless: you send a prompt, you get a response, the model holds no memory of the exchange. Each API call is independent.
This is often described as a limitation, and engineers reach for workarounds immediately. They stuff previous conversation turns into the prompt context. They build retrieval systems that fetch relevant memories and inject them. They maintain external state stores that track what the model “knows” about a user across sessions.
All of these are the right approaches. But none of them are simple, and calling the underlying model stateless doesn’t help you reason about the complexity of the system you’re building around it. The statelessness is a property of one component. The system is still stateful. The state just lives in your prompt engineering, your vector database, and your session management layer. (If this pattern is new to you, what most explanations get wrong about embeddings covers the retrieval side in depth.)
The same confusion shows up in frontend architecture. React components are often described as “just functions” because they’re stateless pure functions of their inputs. This is true for a narrow category of components. Real applications have useState, useEffect, context providers, external stores, server state from React Query or SWR, and URL state from the router. The components are technically stateless. The application is deeply stateful. The gap between those two descriptions is where bugs live.
What to actually think about instead
The useful question isn’t “is this stateless?” The useful question is “where does the state live, who owns it, and what are the failure modes when that ownership breaks down?”
Stateless components are often the right choice, but for specific reasons: they’re easier to test in isolation, easier to scale horizontally, and easier to reason about in a narrow sense. Those are real advantages. Just don’t let them make you think you’ve escaped the hard parts.
Every meaningful system needs to remember something. A to-do app needs to remember your tasks. An authentication system needs to remember who’s logged in. A recommendation engine needs to remember your history. The art isn’t in avoiding state. The art is in deciding deliberately where state lives, keeping it from spreading into places where it’s hard to inspect and hard to change, and being honest about the complexity you’re managing rather than pretending an architectural pattern made it disappear.
Stateless is a tool. So is a database. Neither one is a complexity eraser.





