The simple version
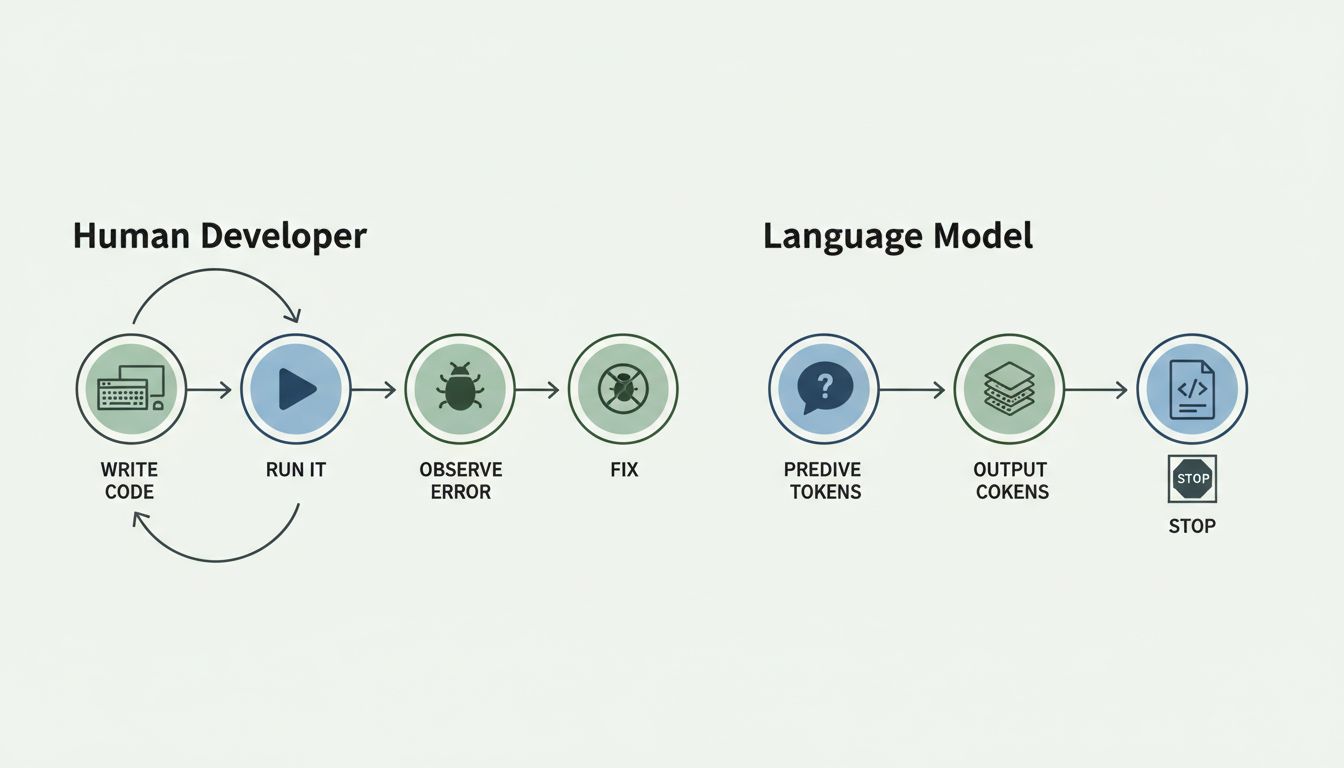
AI coding assistants like GitHub Copilot and Claude generate code by predicting what text should come next, the same way they’d complete a sentence. They have never compiled, run, or debugged a single program.
What the model is actually doing
When you ask an AI to write a function that sorts a list of users by last name, it doesn’t reason through the logic, test it against edge cases, and hand you the result. It does something more like this: it looks at your request and its training data (billions of lines of code scraped from GitHub, Stack Overflow, documentation, and other sources) and produces the sequence of tokens that most plausibly follows from your prompt.
A token is roughly a word or a punctuation mark. The model is, at its core, a very sophisticated function that takes a sequence of tokens as input and outputs a probability distribution over what token should come next. It picks from that distribution, appends the token, and repeats until it decides it’s done.
This process has no step that says “compile the output” or “run this against test cases.” The model has no runtime environment. It has no execution context. It has learned what correct-looking code looks like, which is genuinely useful, but that’s categorically different from knowing whether code is correct.
Why it works as well as it does
Here’s what makes this worth pausing on: the approach works surprisingly often, and understanding why helps you use these tools more intelligently.
Code has very strong statistical regularities. A for loop over a list almost always ends with a consistent pattern. A function that opens a file almost always closes it, or uses a with block that handles closing automatically. SQL queries follow tight grammatical rules. If you’ve ingested enough examples of correct code, you can produce code that looks correct, and in common cases, “looks correct” and “is correct” overlap substantially.
The model has also absorbed something like idiom. It’s seen thousands of implementations of binary search, quicksort, and REST API handlers. For these well-trodden patterns, its output is often indistinguishable from what a competent developer would write, because it’s essentially reconstructing the Platonic average of all those examples.
This is why Copilot handles boilerplate so well and why it starts to struggle in proportion to how far your problem departs from patterns that exist in its training data. Novel business logic, unusual library combinations, subtle concurrency requirements: these are the cases where the gap between “statistically plausible” and “actually correct” opens wide.
The fundamental limitation this creates
The model has no way to verify its own output. It cannot tell the difference between code that would compile and run correctly and code that contains a subtle off-by-one error, a race condition, or a security vulnerability. From its perspective, both look like plausible next tokens.
This is not a temporary limitation that will be patched in the next version. It’s structural. A language model that only predicts text cannot execute code as part of that prediction. Some systems layer execution on top (OpenAI’s Code Interpreter, for instance, actually runs Python in a sandbox), but that’s a different architecture built around the model, not the model itself gaining the ability to reason about runtime behavior.
The practical consequence is that the AI writing your code cannot tell if it works. It can tell you with great apparent confidence that it works. It may even explain, fluently, why it works. That explanation is also a prediction about what a correct explanation would sound like, not a trace of actual reasoning. If you want to understand the gap between a model’s expressed confidence and its actual reliability, this piece on confidence scores is worth reading.
What this means for how you should use these tools
The failure mode to avoid is treating AI-generated code as reviewed code. It isn’t. It’s a first draft from a contributor who is very fast, often right, and constitutionally incapable of knowing when they’re wrong.
That framing suggests the right workflow. Use the AI for what it’s genuinely good at: generating the structural skeleton of something you’d write anyway, handling boilerplate, translating between languages or frameworks where the mapping is mechanical. Then read the output with the same skepticism you’d apply to code from a junior developer who was confident but new to your codebase.
The places to be most careful are precisely the places where the model is most fluent. Security-sensitive code (authentication, input sanitization, cryptography) exists in the training data, which means the model can produce it confidently. It also means the model has ingested the vulnerabilities that appeared in that code, not just the correct patterns. The same logic applies to concurrency, where subtle bugs often don’t appear in any single file and therefore leave no clear statistical signal for the model to learn from.
The tools are genuinely useful. A senior developer who understands this limitation will get more out of them, and make fewer expensive mistakes, than one who doesn’t. The model is an extraordinarily capable autocomplete engine that has read more code than any human ever will. Just don’t mistake reading for understanding, and don’t mistake fluency for correctness. Those confusions are easy to make, and the bugs they produce are the kind that don’t announce themselves.