
The most dangerous bugs in software are not the ones that crash your program. They are the ones that disappear the moment you look for them.
This class of bug has a name: the Heisenbug, borrowed from Heisenberg’s uncertainty principle in physics. Attach a debugger, add a print statement, slow the execution down by any measurable amount, and the bug vanishes. Ship the code without those tools running, and it comes back. The behavior of the program changes depending on whether it is being observed. This is not a quirk or an edge case. It is evidence that our standard approach to software reliability is built on a flawed assumption, one that needs to be corrected before it causes serious damage.
The assumption is this: a program that passes testing is a program that works.
Timing is the silent variable most tests ignore
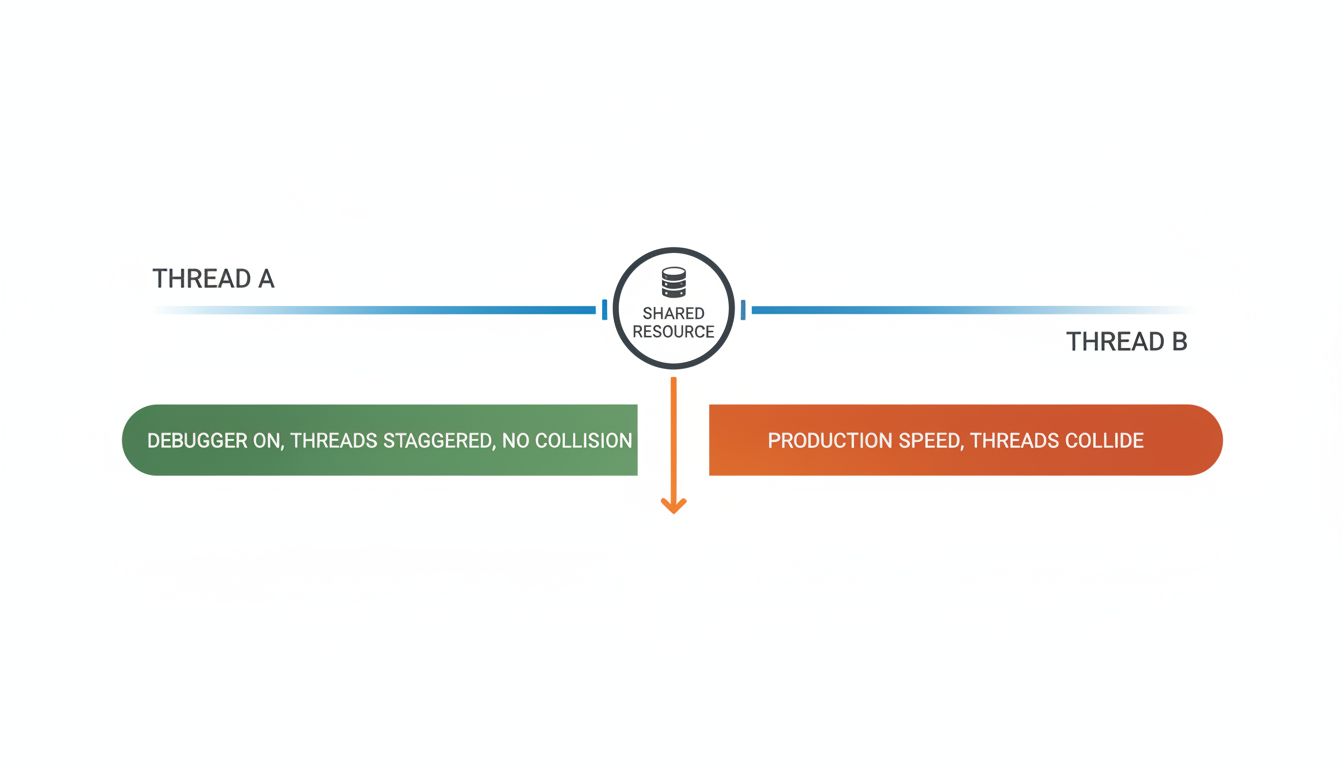
The majority of Heisenbugs are timing-related. Two threads reach for the same memory at the same time. A network packet arrives slightly out of order. A cache entry expires between the check and the use. These are race conditions, and they are notoriously difficult to catch because the test environment changes the timing.
A debugger adds latency. Breakpoints pause execution. Logging writes to disk. All of these slow things down, and in doing so, they eliminate the narrow window where the bad thing happens. The code appears correct under observation and fails in production, where it runs at full speed with real load.
This is not a new problem. Tony Hoare warned about concurrency bugs in his 1978 paper on communicating sequential processes. What has changed is the scale. Modern applications run across dozens of threads, distributed across multiple services, often coordinated by asynchronous message queues. The number of timing-sensitive interactions has grown faster than our testing tools have.
The observer effect is built into your toolchain
Consider what happens when you add instrumentation to diagnose a production issue. You add metrics collection. You add tracing. You add more detailed logs. Each of these changes the program’s behavior in small but real ways: more memory allocated, more CPU time consumed, more I/O in flight. In the best case, this is harmless overhead. In the worst case, it is enough to mask the problem you are trying to find.
This is not a theoretical concern. The practice of adding print statements to debug concurrent code is so reliably counterproductive that experienced engineers treat it as a red flag. Print statements serialize output to a buffer, which introduces locks, which changes thread scheduling. The act of debugging rewrites the very timing relationships you are trying to observe.
The deeper issue is that our testing frameworks are fundamentally deterministic tools being applied to non-deterministic systems. A unit test runs one thread. A typical production service runs many, against shared state, with inputs that arrive in unpredictable order. Passing every unit test is a weak guarantee.
The fixes that work are structural, not symptomatic
Engineers who have dealt seriously with Heisenbugs tend to converge on the same conclusions. The first is that you cannot test your way out of a concurrency problem. You have to design your way out of it.
Immutable data structures eliminate the category of bug where two threads fight over the same memory, because neither thread can modify the memory in the first place. This is why functional programming languages with enforced immutability, and systems designed around immutable event logs, have significantly lower rates of concurrency bugs. The Erlang runtime, which powers many telecommunications systems that are required to run at five-nines uptime, was built around this principle from the start. Processes share no memory. They communicate only by passing messages. Race conditions on shared state become structurally impossible.
The second conclusion is that observability tooling needs to be a first-class design concern, not an afterthought. The best tracing systems in production today, tools built around distributed tracing standards like OpenTelemetry, are designed to add minimal and predictable overhead. They are part of the architecture, not bolted on after the fact. That matters because instrumentation that changes behavior is instrumentation that lies.
The counterargument
The reasonable pushback here is that most software does not run at a scale where these bugs matter. A single-threaded web application with a connection pool and a database behind it is not going to suffer many race conditions. Most developers will go their entire careers without encountering a true Heisenbug in production. Why architect around a problem that might never bite you?
This argument was more convincing before cloud-native architecture became the default. A decade ago, many applications were genuinely simple enough that timing-related bugs were rare. Now the same application that once ran on one server runs across multiple containers, behind a load balancer, talking to a message queue, with background workers competing for database rows. The architectural complexity that was once the exclusive domain of large engineering teams is now the standard starting point for new projects. The problem has scaled down to meet developers who were never trained to handle it.
The counterargument also ignores the asymmetry of consequences. Heisenbugs are, by definition, the hardest bugs to find. They tend to surface under load, which means they surface in production, not in a test environment. And because they disappear when you attach tools to look at them, they can persist in a codebase for years. The costs compound in ways that are easy to underestimate.
The point is the premise, not the symptom
A bug that hides from your debugger is not just an engineering inconvenience. It is a signal that your mental model of how the program runs does not match how it actually runs. The debugger creates a slower, more orderly version of your program. The real program is faster and more chaotic, and the gap between those two versions is where Heisenbugs live.
The solution is not better debugging tools, though those help. It is building software that is correct by construction rather than correct by inspection. That means taking concurrency seriously at the design stage, using architectures that make shared mutable state rare, and treating any bug that only appears under specific timing conditions as a structural problem rather than a fluke.
A bug you cannot reproduce is a bug you cannot fix. And a bug you cannot fix is a bug that will keep finding you.





