
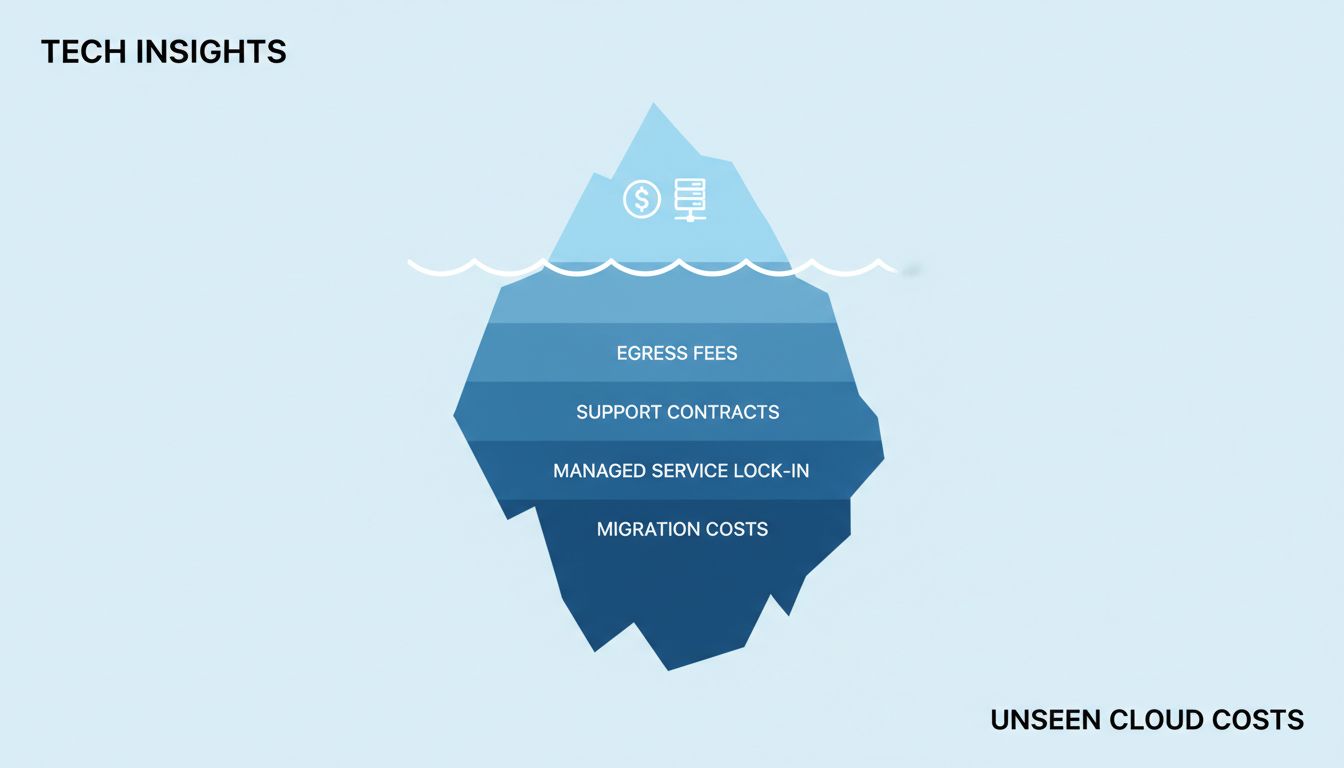
The Number That Doesn’t Matter Most
When companies shop for cloud infrastructure, they typically compare compute prices. AWS versus Azure versus Google Cloud, measured in dollars per virtual CPU per hour. It’s a reasonable starting point. It’s also largely irrelevant to what you’ll actually spend.
The list price of compute represents a fraction of total cloud spend for most production workloads. Networking, storage, support contracts, the managed services that quietly become load-bearing walls in your architecture, the engineering hours to maintain anything you try to self-host instead — these are where the real money goes. And none of them show up in the comparison blog posts that rank providers by compute cost.
This isn’t a new observation in enterprise software. The upfront price of any platform tends to be the smallest component of its total cost. What’s different about cloud is that the cost structure is designed to be opaque, and switching costs compound in ways that aren’t obvious until you’re already deep.
Egress Fees Are the Trap Door
Data transfer costs are the most reliably underestimated line item in cloud infrastructure. Getting data into a cloud provider is usually free. Getting it back out costs money, often significant money, and the pricing is structured in a way that makes it hard to forecast.
AWS, Azure, and Google Cloud all charge for data leaving their networks. AWS charges roughly $0.09 per gigabyte for outbound internet traffic from US regions (as of 2024). That sounds small. At scale, it isn’t. A company serving several terabytes of data daily is paying tens of thousands of dollars per month just to move its own data to its own users.
More insidiously, egress fees also apply to moving data between regions, and in some cases between availability zones. This means architectural decisions — keeping services close together to reduce latency, replicating data for redundancy — carry hidden costs that don’t surface until the bill arrives.
Cloud providers have historically competed on compute prices while holding firm on egress. In 2023, a coalition of European cloud customers and competitors pushed regulators to examine this practice, and the EU’s Cloud Switching and Porting requirements under the European Data Act explicitly target egress fees as a barrier to competition. The fact that regulators had to intervene to address this tells you something about how intentional the pricing structure is.
The Managed Services Dependency Problem
The cheapest raw compute provider may not offer the managed services your architecture actually needs. And when you start adopting managed services from your primary provider — a managed Kubernetes service, a serverless function platform, a managed database — you’re not just paying for that service. You’re building an application that only runs on that provider’s specific implementation.
This is the architecture trap. Amazon’s RDS, Google’s Cloud Spanner, Azure’s Cosmos DB — these services genuinely save engineering time and reduce operational burden. They also bind you. The moment you build a production system around DynamoDB’s specific consistency model or Cloud Spanner’s global transaction semantics, migrating becomes an engineering project measured in months, not a pricing decision measured in spreadsheets.
The TCO calculation that ignores migration costs is incomplete by design. A provider that charges 15% less per compute hour but whose managed services create a rewrite-the-application exit cost has not given you a discount. It has given you a deferred liability.
Support Contracts and the Hidden Floor
List prices assume you run your infrastructure without meaningful vendor support. Almost no production deployment actually does this.
AWS’s Business Support tier starts at 10% of monthly usage (with a minimum monthly charge). Enterprise support is negotiated, but commonly runs 3-10% of spend. Google Cloud and Azure have comparable structures. For a company spending $500,000 annually on cloud infrastructure, the support contract alone adds $50,000 to $150,000 before a single engineer has done anything.
This is a cost that doesn’t appear in any compute price comparison, because it scales with your spend rather than your workload. Two providers with identical raw prices can have meaningfully different effective costs based purely on support tier pricing and what that tier actually delivers. A provider with cheaper compute but worse support SLAs may cost you more when the outage hits and you need someone senior on the phone at 2am.
Reserved Instances and the Commitment Gamble
Every major cloud provider offers significant discounts for committing usage in advance. AWS Reserved Instances, Google’s Committed Use Discounts, Azure Reserved VM Instances — the mechanism varies, but the deal is the same: pay upfront or commit to paying, get a lower effective hourly rate.
The discounts are real and substantial. AWS Reserved Instances for a one-year term typically run 30-40% below on-demand pricing. Three-year commitments go deeper. If you can accurately predict your usage, these are not optional savings — you’re effectively leaving a third of your compute spend on the table by running fully on-demand.
The problem is that commitment-based pricing rewards stability and punishes growth and change. A startup that commits to one-year reserved capacity based on current usage, then grows faster than expected, gets to pay both the reserved price for the capacity it committed to and on-demand prices for the additional capacity it needs. A company that pivots its architecture away from the instance types it reserved is stuck paying for infrastructure it’s not using.
The cheapest sticker price often requires the largest commitment. That commitment is a financial instrument with real risk, and the expected value of that risk rarely appears in procurement conversations.
What Cheap Actually Costs in Engineering Time
The least visible cost in cloud procurement is the engineering labor required to operate the infrastructure you choose.
Smaller providers sometimes offer genuinely lower compute prices by offering fewer managed services and less mature tooling. This is a real trade-off. A team running self-managed PostgreSQL on bare VMs to avoid a managed database surcharge is spending engineering hours on backups, failover, patching, and performance tuning that engineers at a competitor are spending on product. That engineering time has a salary cost, an opportunity cost, and a compounding effect on delivery speed.
Conversely, a provider with a rich managed service ecosystem can introduce a different kind of engineering cost: the time spent understanding proprietary services, maintaining expertise in a specific provider’s tooling, and managing the complexity that comes from relying on services that evolve on someone else’s roadmap. AWS releases hundreds of new features and services each year. Keeping current with a platform that size is itself a job.
The honest calculus here requires knowing what your engineers are good at and what they’d rather be doing. Savings that come from converting product engineering time into infrastructure operations time are not obvious wins.
The Negotiation You’re Not Having
List prices are negotiable, but not in the way most companies pursue. Asking for a discount at the start of a procurement process rarely works. Providers negotiate seriously when they have reason to believe you might leave, when you’re large enough to matter as a customer, or when you’re willing to commit to a multi-year enterprise agreement that gives them revenue predictability.
This means the best time to negotiate cloud pricing is not when you’re signing up. It’s when you’ve demonstrated scale and have a credible alternative. Companies that run multi-cloud architectures, even partially, tend to negotiate better contracts because the threat of shifting workloads is credible rather than theoretical.
The implication is that the cheapest provider at the moment of initial selection may not remain the cheapest provider as the relationship matures, and vice versa. A provider that seemed expensive based on list prices may become more competitive after negotiation. A provider that offered low entry prices may reveal its actual cost structure at scale.
What This Means
The actual cost of a cloud provider is a function of at least six variables that list price comparisons ignore: egress fees at your specific data volumes, the architecture decisions that managed services force, support contract costs, the discount structure of commitment-based pricing and how well it fits your growth trajectory, engineering labor to operate whatever you don’t buy managed, and your negotiating leverage over time.
Running a realistic TCO comparison requires knowing your workload well enough to estimate data transfer volumes, predicting your scaling trajectory well enough to model commitment risk, and being honest about your team’s capabilities and preferences on the build-versus-buy spectrum.
None of this means that price is irrelevant or that the cheapest provider never wins. It means that cloud procurement decisions made primarily on compute price comparisons are not being made on the factors that determine the final bill. The providers know this. The savvier enterprise customers have learned it. The gap between those two groups is where a lot of money gets left on the table.





