In the spring of 2021, a mid-sized streaming platform serving several million subscribers went dark for nearly four hours. Not partially dark. Completely unreachable. The engineering team was staring at healthy application servers, healthy databases, healthy CDN nodes. Everything that was supposed to matter was fine. The culprit was a single Linux box that nobody on the current team had provisioned, nobody had documented, and nobody had thought to include in the disaster recovery runbook. It wasn’t running any user-facing service. It was a bastion host, a jump server sitting at the network perimeter, used exclusively for SSH access into the private subnet. When it failed, engineers couldn’t reach any of the other servers to diagnose or repair anything. A working infrastructure became an unmodifiable one.
This is not an unusual story. Variations of it happen constantly, in companies of every size, and the pattern is always the same: the server that does the least visible work turns out to be load-bearing in ways nobody mapped.
The Setup
The platform had grown quickly over three years, absorbing two rounds of funding and tripling its engineering headcount. Fast growth in engineering organizations tends to produce what you might call archaeological infrastructure: layers deposited by previous teams, often undocumented, that newer engineers inherit without fully understanding. The bastion host had been set up by a contractor during the initial AWS deployment. It was never added to the configuration management system (Ansible, in this case) because it predated the team’s adoption of Ansible. It wasn’t in Terraform state because the team had migrated to Terraform after the fact and the bastion was one of a handful of resources that got imported imperfectly and then quietly excluded.
It sat there for two years, doing its small job reliably, invisible in every dashboard and runbook that mattered.
When the host’s underlying EBS volume suffered a corruption event, the instance became unresponsive. The on-call engineer paged the team. The team looked at their monitoring suite and saw green across every service they tracked. It took 40 minutes just to correctly identify the problem, because nobody had instrumented the bastion. It wasn’t in their service map. Finding it required someone with institutional memory, a senior engineer who had been on a different team for 18 months, to say: “Wait, how are you trying to SSH in?”
What Happened
Once the team identified the problem, recovery was straightforward: spin up a new bastion, configure security groups, restore access. The technical fix took about 25 minutes. The preceding three-plus hours were pure detective work. The outage itself wasn’t caused by the bastion failing. It was caused by the team’s inability to act on a failure that, in isolation, shouldn’t have been catastrophic.
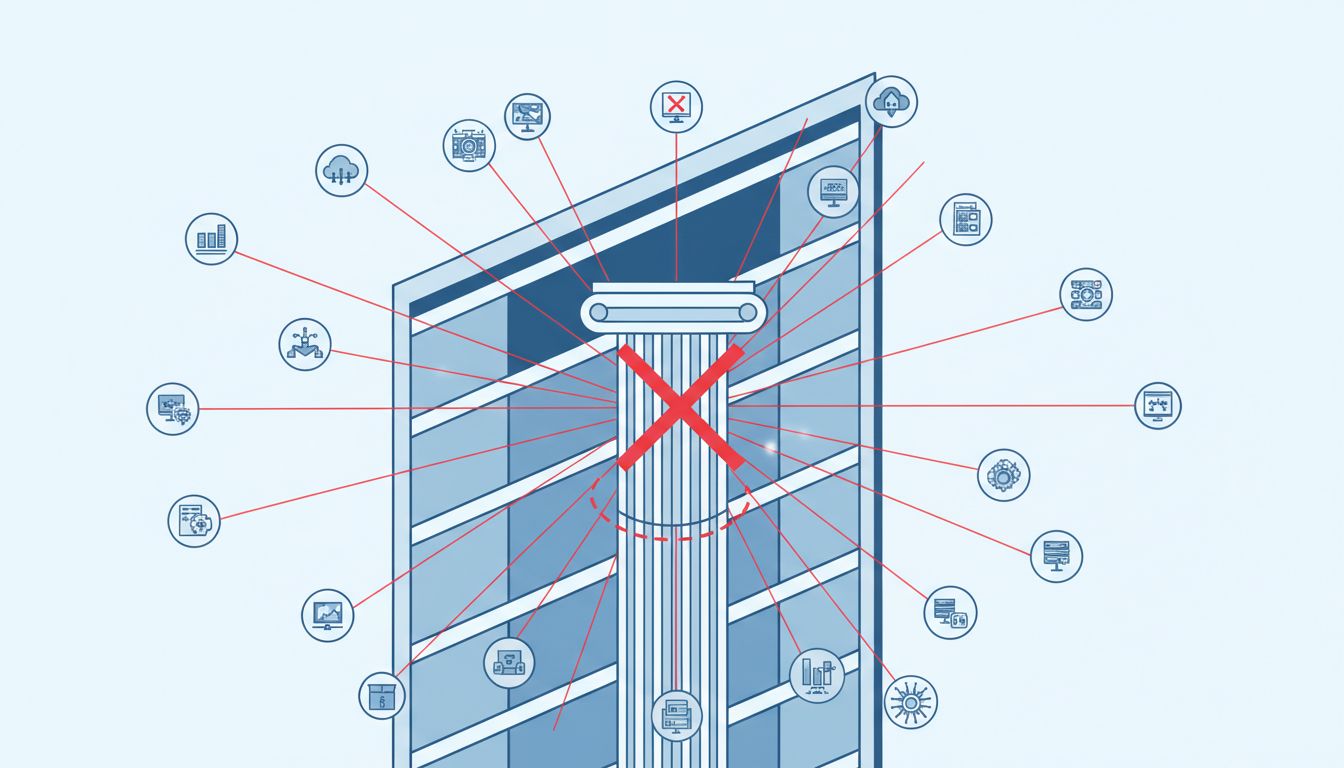
This distinction matters enormously. The bastion going down was a nuisance. Not being able to identify it, reach it, or replace it quickly turned a nuisance into a full outage. The organization’s failure wasn’t in its redundancy planning for user-facing services. It was in its implicit assumption that anything not serving user traffic was not really infrastructure.
After the incident, the post-mortem identified three specific failure modes that compounded each other. First, the bastion wasn’t monitored. Second, it wasn’t in any automated provisioning system, so the team had to reconstruct its configuration from memory and a two-year-old Slack message. Third, there was no runbook for the scenario “we cannot access the private subnet,” because nobody had thought to treat that as a scenario worth planning for.
The fix the team implemented was methodical. They rebuilt the bastion through Terraform, added it to their monitoring stack with the same alerting thresholds as production services, wrote a runbook that included bastion recovery as step one of any access-related incident, and conducted a broader audit to find other undocumented infrastructure. That audit surfaced a NAT gateway, two security-group rules with no clear owners, and an old Elasticache cluster that had apparently been orphaned but was still running and accumulating cost.
Why It Matters
The streaming platform story is a clean example of a broader infrastructure antipattern: the hierarchy of visibility. Engineering teams instrument what they think of as “the product.” Application servers, databases, queues, caches. These get dashboards, alerts, runbooks, and on-call rotations. Everything supporting that infrastructure, the network plumbing, the access layer, the tooling servers, tends to get treated as furniture. Present, assumed functional, not worth monitoring because it doesn’t serve users directly.
This is backwards. The correct frame is dependency, not visibility. A bastion host that 300 engineers use to access production is more critical in a failure scenario than most application servers, precisely because you need it to fix anything else. The same logic applies to VPN servers, internal DNS resolvers, certificate authorities, secrets management services (Vault, AWS Secrets Manager), and deployment pipelines. None of these serve users directly. All of them are catastrophically important when they fail.
There’s a useful parallel in how we think about latency and throughput as distinct problems. We tend to optimize and monitor for the thing we can measure easily: throughput, because it shows up in dashboards. Latency in the access layer, meaning the time it takes to even begin responding to an incident, doesn’t show up anywhere until an outage makes it visible. The bastion problem is the access-latency problem. When access infrastructure fails, your incident response time goes to infinity.
What We Can Learn
The practical lessons here are not complicated, but they require some organizational discipline to apply.
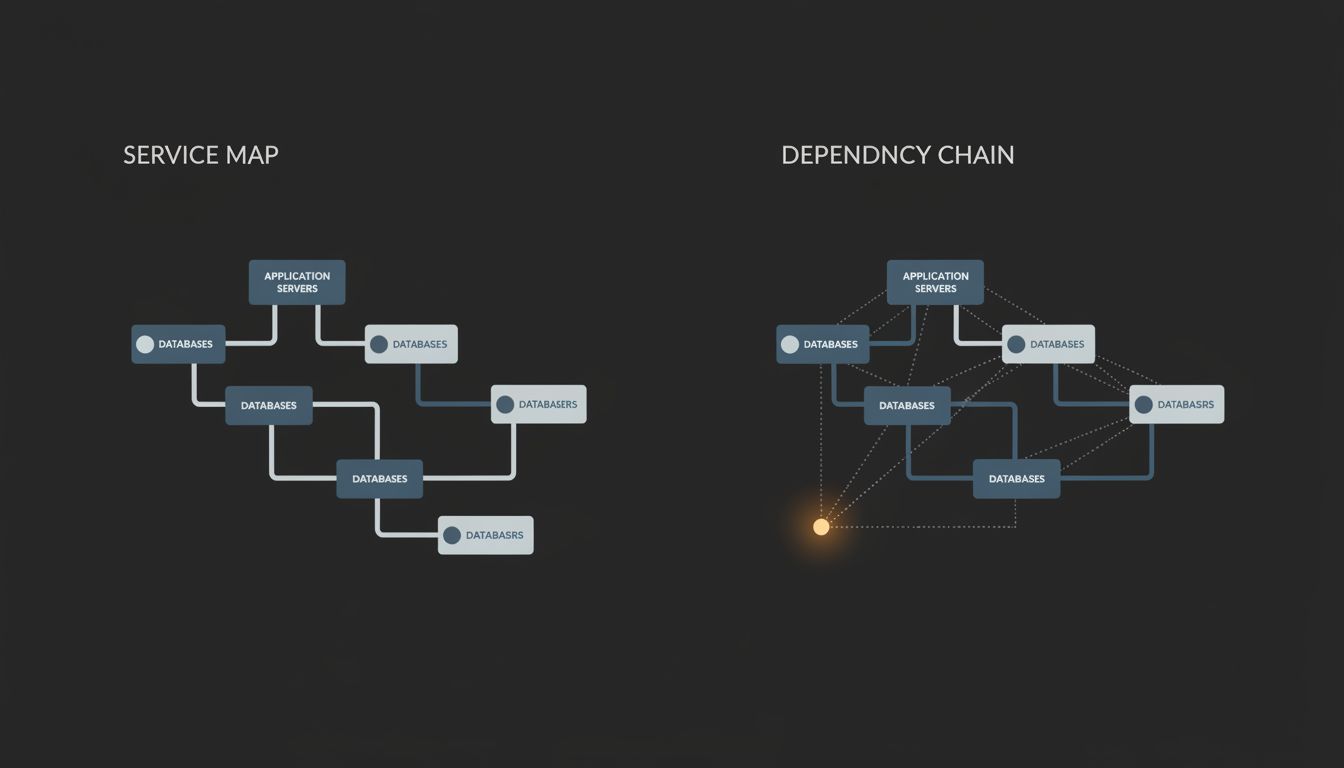
First, build your infrastructure inventory from dependency chains, not service maps. A service map shows you what talks to what during normal operation. A dependency chain shows you what you need to touch anything during abnormal operation. Those are different graphs, and most teams only maintain the first one.
Second, apply monitoring symmetrically. If a server’s failure would require engineer attention, it should have monitoring. The threshold shouldn’t be “does this serve user traffic” but “would this failing make anything harder to fix.” A bastion, a deployment server, an internal DNS resolver, all of these clear that bar easily.
Third, treat undocumented infrastructure as a risk that accrues interest. The streaming platform’s bastion was low-risk in year one, when the contractor who built it was still reachable. By year two, it was moderate risk. By the time the incident happened, the knowledge of how it was configured existed in one person’s partial memory. Every month of operating undocumented infrastructure is a month of compounding institutional-knowledge debt.
Fourth, runbooks should cover access failure explicitly. “We cannot reach production” is a scenario. It should have a documented path to resolution that does not depend on any single person’s memory of the network topology.
The streaming platform got lucky in one sense: the failure happened on a Tuesday afternoon with the full team available. The same failure at 2 AM on a holiday weekend, with a junior on-call engineer who had never heard of the bastion host, could easily have been a 12-hour outage. The gap between those two outcomes isn’t technical. It’s organizational.
The server that does nothing is always doing something. Usually, it’s quietly holding the rest of the rack together. The teams that figure this out before an incident are the ones with boring post-mortems.