

There’s a particular kind of engineering misery that arrives at 2am: a bug that every test in your suite swears cannot exist. Your staging environment never saw it. Your local machine reproduces nothing. But there it is, reliably failing for real users doing real things.
This isn’t bad luck. It’s a structural problem, and it happens for reasons that are predictable and fixable once you understand them.
The Environment You Test In Is a Comfortable Lie
Local development is, by design, a simplification. You’re running a single instance of your application on fast hardware, talking to a local database with a few hundred rows, behind no load balancer, with no competing processes, and probably with your IDE’s debugger attached. That setup is great for writing code. It is terrible for predicting production behavior.
Production is a different organism. It has real users making concurrent requests, network latency between services, database tables with millions of rows and actual lock contention, memory pressure, connection pool exhaustion, and configuration differences that crept in over months. A bug that requires three concurrent requests hitting a shared resource within the same 50-millisecond window will never surface on your laptop. It surfaces when you have enough traffic, and then it surfaces constantly.
The concurrency class of bugs is probably the most common production-only failure mode. A developer writes code that works perfectly when called by one user at a time, never considering that two users might read the same inventory count, both see “1 item left,” and both successfully complete a purchase. The test suite checked that the purchase flow works. It didn’t check what happens when two instances of it run simultaneously. Two users, one file, one moment of truth covers exactly this dynamic in detail.
Scale Changes the Rules
Many bugs are genuinely invisible below a certain traffic threshold. They’re not hiding, they’re not triggered. The code path that causes a memory leak might execute once per user session. With ten users in your test environment, you lose a few megabytes and nobody notices. With fifty thousand users over twelve hours, your process starts getting killed by the OS.
Database behavior is particularly sensitive to scale. A query that runs in 3 milliseconds against a table with 10,000 rows might run in 4 seconds against a table with 50 million rows, and the problem is usually in the query plan the database chose. Index selection, join order, and whether a full table scan happens are all decisions the database makes at runtime based on table statistics. Your local database doesn’t have those statistics, because it doesn’t have that data. The query that looked fine in testing genuinely was fine in testing.
Similarly, background jobs that process queues behave completely differently when the queue has 8 items versus 800,000 items. The algorithmic complexity problem that was always there becomes visible only when you actually have load. You can’t unit-test your way to discovering that your job processing is O(n²) in queue depth if you only ever test it with trivial queue depths.
Configuration Drift and the Third-Party Surprise
Production environments accumulate divergence from local environments over time. A configuration variable gets added directly in production without going through the repo. A third-party API key rotates in production but the local environment still uses the old sandbox credential with more permissive rate limits. A feature flag that’s on by default locally was turned off in production three months ago and nobody updated the docs.
This kind of configuration drift is insidious because the bugs it causes look like code bugs. You’re debugging the wrong thing. The code is fine. The environment is not what you think it is.
Third-party integrations deserve special attention here. External APIs have their own rate limits, timeouts, data quirks, and occasional outages. A payment processor that returns clean success/failure responses in sandbox mode might return ambiguous intermediate states under production load or during a partial outage. Your code was tested against the clean response. It was never tested against the response that says, effectively, “we’re not sure yet.”
What Actually Helps
The standard answer to this problem is “better testing,” which is true but not useful on its own. More specifically, the types of testing that catch production bugs are different from the types most teams invest in.
Load testing, even basic load testing, catches an enormous number of production bugs before they reach production. Running your application at 2x expected peak traffic for thirty minutes will surface concurrency bugs, memory leaks, and database performance problems that no amount of unit testing will find. Tools for this exist and most engineering teams simply don’t use them.
Chaos engineering, the practice of deliberately injecting failures (slow dependencies, dropped connections, killed instances) into a running system, reveals how your application behaves when the environment stops cooperating. It originated at Netflix as a formal discipline, but the basic idea applies at any scale: if your application assumes its dependencies are always available, you need to test what happens when they’re not.
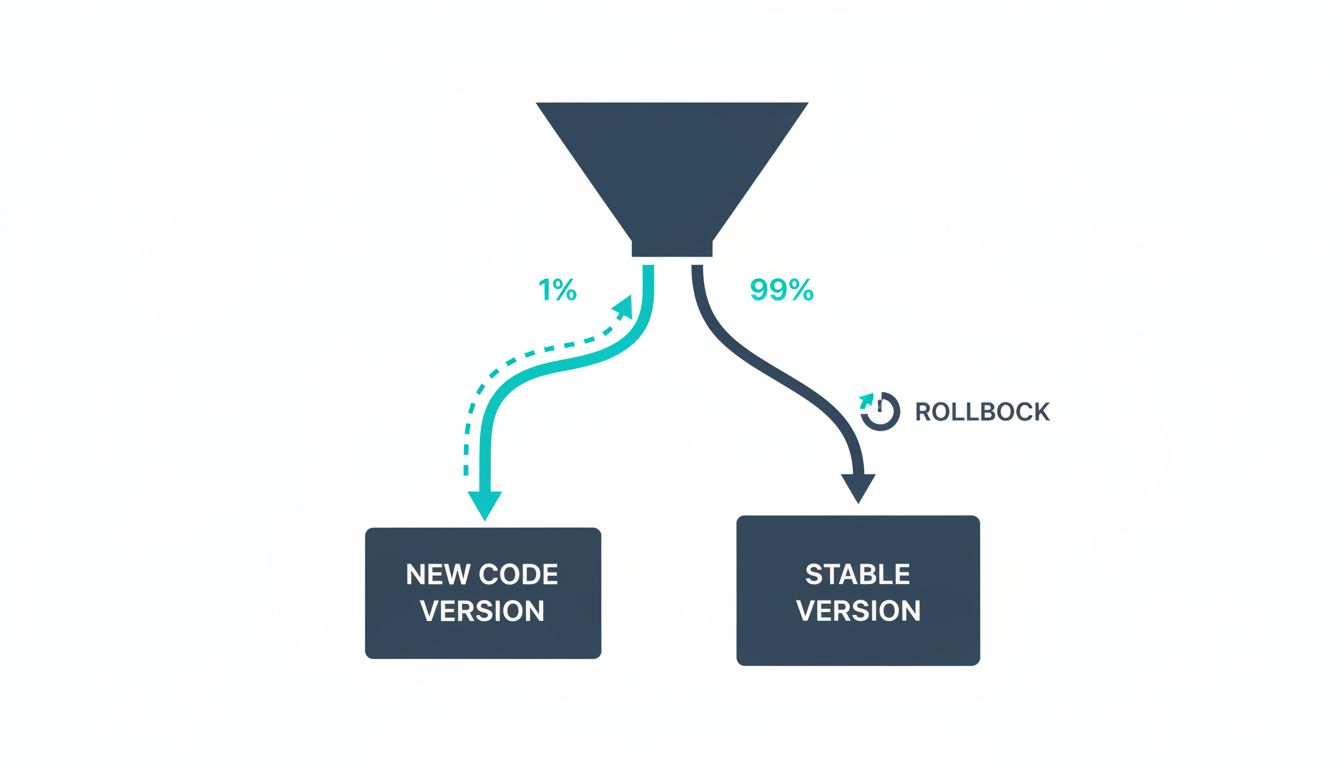
Feature flags that allow production traffic to be gradually shifted to new code paths are worth more than most testing strategies combined. A canary deployment lets you expose 1% of real users to new code under real conditions, with the ability to roll back in minutes. A bug that shows up in that 1% would have shown up across 100% without you.
Finally, invest in observability rather than just monitoring. Monitoring tells you when a threshold is breached. Observability (structured logging, distributed tracing, and meaningful metrics) tells you why. A production bug you can diagnose in twenty minutes is much less damaging than one you spend two days debugging because you can’t see what the system is actually doing. As production bugs themselves often point out, the failure is frequently also a diagnostic signal about where your test coverage has gaps.
The Honest Conclusion
Local testing is necessary but it is not sufficient. The gap between your test environment and production is not a failure of diligence. It’s structural. Your local machine is a controlled environment that removes the variables that cause production bugs. That’s its job. The problem arises when teams treat the absence of production in their tests as the presence of production confidence.
The goal isn’t to make local testing more realistic (though better tooling like Docker Compose helps). The goal is to maintain honest humility about what local testing can and cannot tell you, and to build the load testing, observability, and deployment practices that catch the rest.





