

Checksums are infrastructure for people who have already been burned. Nobody adds them enthusiastically. You add them after a corrupted download costs you a week, or after a bit-flipped database row causes an incident nobody can explain. The concept is almost insultingly simple: run your data through a function, get a short string back, keep that string, check it later. If the data changed, the string won’t match. That’s it.
But the simplicity is load-bearing. Here’s what checksums are actually doing in the systems you rely on every day, and why they deserve more respect than they get.
1. They Catch the Errors That Aren’t Supposed to Happen
Storage hardware fails in ways that don’t announce themselves. A phenomenon called “silent data corruption” occurs when a drive returns data without any error signal, but the data is wrong. This isn’t rare or theoretical. Google published research in 2008 showing that checksum mismatches in their storage systems occurred at rates that would have been catastrophic without detection. The drives reported no errors. The data was wrong anyway.
Checksums are the layer between “the hardware says everything is fine” and “everything is actually fine.” Without them, you’re trusting a piece of spinning metal or flash memory to never quietly lie to you. That trust is not well-placed.
2. A Single Bit Flip Can Corrupt Meaning Entirely
In a UTF-8 encoded string, flipping one bit can turn a valid character into gibberish or, worse, into a different valid character that reads fine but means something wrong. In a compiled binary, a bit flip can silently change an instruction. In a financial record, it can change a number. The corruption is invisible to anyone not specifically looking for it.
CRC32, MD5, SHA-256, and their relatives exist on a spectrum. CRC32 is fast and catches accidental corruption well. SHA-256 is slower but cryptographically strong, meaning it’s practically impossible to construct two different inputs that produce the same output. For verifying software downloads, you want the stronger end of that spectrum, because you’re not just guarding against accidents. You’re also guarding against tampering.
3. Package Managers Live and Die on Checksum Verification
When you run npm install or pip install or apt-get install, your package manager is downloading code from external servers and running it on your machine. The chain of trust holding that process together is, in large part, checksums.
The npm registry stores a checksum for every package version. When your package manager downloads a package, it computes the checksum of what it received and compares it against the registry’s record. If they don’t match, the install fails. This is why supply chain attacks typically target the registry itself or the package metadata rather than intercepting downloads in transit. Breaking the download isn’t enough when the destination is also checking. The 2021 ua-parser-js attack, where a popular npm package was compromised to mine cryptocurrency and steal credentials, worked partly because the attacker had legitimate registry access. The checksum matched because the checksum was for the malicious version.
4. They Expose Assumptions You Didn’t Know You Were Making
A lot of software is built with an implicit assumption that data is immutable once written. A configuration file stays the same. A binary stays the same. A database row stays the same unless someone deliberately changes it. Checksums force you to make that assumption explicit and verifiable.
Adding a checksum to a critical piece of stored data is also a form of documentation. It says: this field’s contents mattered enough that we decided to detect if they changed unexpectedly. That’s information about intent. It’s worth thinking of checksums as a category of verification that pays its cost over time, not something you audit once and forget.
5. Git’s Entire Model Is Built on Them
Git doesn’t store file names as primary keys. It stores SHA-1 hashes of file content as primary keys, then builds a tree of those hashes. Every commit is identified by a hash of its contents, which includes hashes of its parent commits. This means any change anywhere in the history chain produces a different hash at the top.
The practical result is that Git history is tamper-evident by design. If someone quietly rewrites a commit, the hash changes. Everyone who has a copy of the original hash will notice. This is why git push --force to a shared branch is a social problem as much as a technical one: it changes the hash that other people’s work is referencing, breaking their local chains.
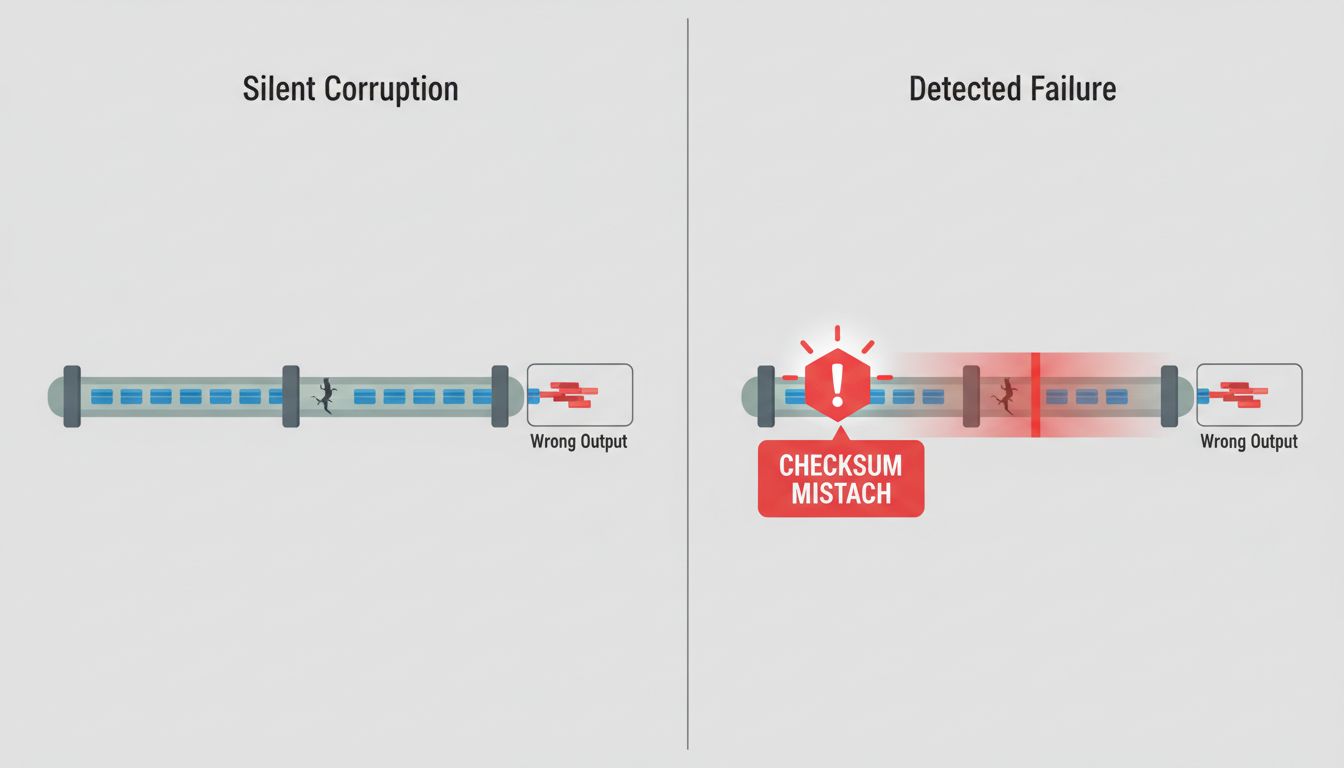
6. Checksums Don’t Prevent Corruption. They Prevent Ignorance.
This is the distinction that matters. A checksum cannot stop a cosmic ray from flipping a bit in your RAM. It cannot stop a drive from silently returning wrong data. It cannot stop a network packet from arriving corrupted. What it can do is tell you, reliably, that something is wrong.
That sounds modest. It’s not. The alternative is proceeding on bad data without knowing it. Silent, undetected corruption is categorically worse than detected corruption that causes an immediate failure. A system that fails loudly and specifically is fixable. A system that silently processes corrupted data for weeks before anyone notices is a forensic nightmare.
7. The Performance Cost Is Smaller Than You Think
A common objection is that hashing everything adds overhead. For large files or high-throughput systems, the concern is real. But for most applications, a SHA-256 computation on a multi-kilobyte payload adds microseconds. Modern CPUs have hardware acceleration for common hashing operations. The overhead is almost never the bottleneck.
The more honest version of the performance objection is about engineering time, not CPU time. Adding checksums means adding storage for the hash, adding code to compute and verify it, and adding logic to handle mismatches. That’s real work. But it’s also the kind of work that compounds positively: you write it once, and it quietly protects you for the lifetime of the system.
8. The Boring Infrastructure Is Usually the Most Important
Every time a software system survives something it shouldn’t have, a quiet layer of verification usually deserves partial credit. Checksums are in that category alongside input validation, connection timeouts, and retry logic. Nobody writes a postmortem where the headline is “our checksum verification prevented a catastrophe.” The postmortems get written when the verification wasn’t there.
The invisibility is actually the signal. Infrastructure that you never hear about is doing its job.





