

The internet feels seamless. You click send, the email arrives. You start a video call, and a face appears. The experience is so smooth that most people assume the underlying machinery is similarly elegant, a clean pipe carrying your data from here to there.
It isn’t. The actual mechanism is closer to mailing a book by tearing out every page, sending each one in a separate envelope through different post offices, and trusting that enough of them arrive in the right order to reconstruct the text. The marvel isn’t that it sometimes fails. The marvel is that it works at all.
1. Your Data Gets Shredded Before It Goes Anywhere
When you send anything over the internet, TCP (Transmission Control Protocol) doesn’t transmit your file or message as a single unit. It breaks the data into chunks called packets, each one typically capped at around 1,500 bytes. A single 5MB photo becomes thousands of packets before it leaves your machine.
This isn’t a design flaw. It’s a deliberate architectural choice made by Vint Cerf and Bob Kahn when they formalized TCP/IP in 1974. A network that routes small, uniform chunks can recover from congestion, route around failures, and share bandwidth fairly in ways that a connection-oriented circuit cannot. The old telephone network used dedicated circuits. The internet uses packets. One of those models scaled to billions of simultaneous users; the other didn’t.
Each packet gets a header containing the destination IP address, the source address, a sequence number, and a checksum. That sequence number is what allows the receiver to put everything back in order even if packets arrive scrambled.
2. Every Packet Finds Its Own Way to the Destination
Packets from the same transmission don’t travel together. Each one is an independent unit, routed hop by hop through whatever path looks fastest at that moment. Your email to someone across town might send one packet through a data center in Dallas and another through one in Chicago. Neither packet knows about the other.
Routers are the decision-makers here. Each router maintains a routing table, a continuously updated map of which direction to send traffic headed for any given IP address range. When a packet arrives, the router consults its table, picks the best next hop, and forwards the packet. It takes no responsibility for what happens after that. This is the “best effort” model, and it means the network makes no guarantees about delivery, order, or timing.
The practical consequence is that packets can arrive out of sequence, delayed, or not at all. This is expected. The system is designed around it. What really happens when two packets hit a router at once is its own grim story involving queues, priority decisions, and deliberate drops.
3. Packets Get Dropped on Purpose
When a router’s queue fills up, it drops packets. Not because something went wrong, but because dropping is the mechanism routers use to signal congestion to the sender. TCP interprets a dropped packet as a message: slow down.
This feedback loop is the core of TCP’s congestion control. The sender starts with a small transmission window, grows it aggressively until a packet drops, then backs off and grows again more cautiously. This algorithm (TCP Slow Start, followed by Congestion Avoidance) is why a large download often starts slow and accelerates before hitting a plateau. The protocol is literally feeling out how much the network can handle.
The counterintuitive implication: on a congested network, dropping packets is the right call. A router that holds every packet in an ever-growing queue introduces latency that makes real-time applications like video calls unusable. A dropped packet costs you a retransmit. A 500ms queue delay costs you the conversation.
4. TCP Forces the Receiver to Confirm Every Packet
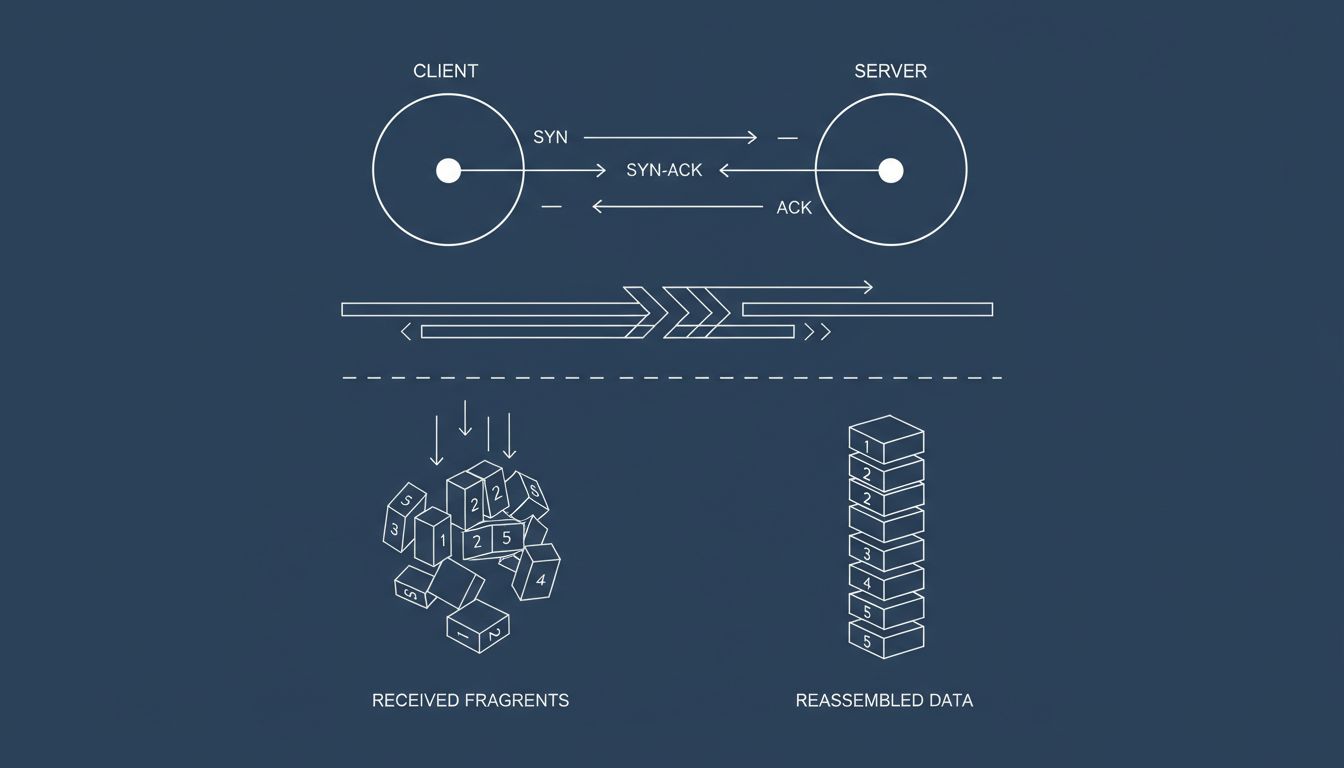
TCP is a handshake-heavy protocol. Before any data transfers, the two endpoints run a three-way handshake (SYN, SYN-ACK, ACK) to establish a connection. During transmission, the receiver sends acknowledgments (ACKs) back to the sender confirming which packets arrived. If the sender doesn’t receive an ACK within a timeout window, it retransmits.
This reliability mechanism is what distinguishes TCP from UDP (User Datagram Protocol). UDP sends packets and doesn’t ask whether they arrived. Live video streaming and online gaming often use UDP for exactly this reason: a dropped frame is better than a frozen screen while TCP waits for a retransmit. A missed packet in a video call is a small glitch. Pausing the call to re-send it would make the conversation impossible.
TCP’s acknowledgment system does mean the protocol pays a latency tax. Every retransmit adds a round-trip delay. On long-distance connections, the speed of light itself becomes the bottleneck. This is why content delivery networks (CDNs) exist: terminating TCP connections closer to the user reduces round-trip time and makes retransmits less painful.
5. The Receiver Rebuilds Everything in Order
At the destination, the receiving system’s TCP stack collects packets as they arrive, potentially out of order, uses the sequence numbers to sort them, detects gaps, waits for retransmits to fill those gaps, and then hands the complete, reassembled data up to the application. The application (your browser, your email client) sees none of this. It receives a clean stream of bytes as if the underlying chaos never happened.
This abstraction is one of the more elegant achievements in computer science. Just as what actually happens inside a CPU when code runs is invisible to the developer writing the code, the entire packet shredding and reassembly process is invisible to the application using the socket. The programmer calls send(), the programmer calls recv(). TCP handles everything in between.
The cost of that abstraction is the overhead: headers, acknowledgments, retransmits, the three-way handshake. HTTP/3, the latest version of the web’s core protocol, replaces TCP with QUIC (which runs over UDP) specifically to reduce this overhead. Google developed QUIC to fix TCP’s head-of-line blocking problem, where a single lost packet can stall an entire connection. QUIC multiplexes streams independently so one dropped packet doesn’t freeze everything else.
6. The Failure Mode Is Actually a Feature
The deepest insight in TCP/IP’s design is that the network isn’t required to be reliable. Reliability is the job of the endpoints. The network’s job is to move packets toward their destination as efficiently as possible right now, without state, without guarantees, without memory of previous packets.
This separation of concerns, dumb network, smart endpoints, is why the internet absorbed technologies its inventors never imagined. Nobody designed TCP for video streaming or voice calls or financial transactions. The protocol doesn’t care. It moves bytes. What those bytes mean, whether they arrived in full, and what to do when they don’t are problems the applications solve themselves.
The engineers who built TCP/IP didn’t try to anticipate every use case and build support for it into the network. They built the simplest possible reliable transport and let applications handle the rest. Fifty years of internet history suggests that was the right call.





