
Six Reasons Your Staging Environment Is Lying to You
Every engineering team has a version of this story: staging looked fine, the deploy went out, and production caught fire within minutes. The post-mortem conclusion is almost always the same: staging didn’t reflect production closely enough. The team nods, writes it up, and then continues treating staging as though it does.
Here’s the uncomfortable position worth taking: staging environments, as most teams run them, are sophisticated placebos. They create confidence that isn’t earned. That’s often worse than having no staging at all.
1. Your Data Is a Costume, Not a Clone
The single biggest gap between staging and production is data, and it’s almost never fixable. Production data has mass. It has years of edge cases baked into it: the user who signed up before your schema migration, the order that got partially processed during an outage, the account with 47,000 line items that nobody ever anticipated. Staging gets a sanitized subset, usually seeded by hand or generated by fixtures, and it behaves accordingly.
This matters most for performance bugs. A query that runs in 12 milliseconds against 10,000 staging rows can take 4 seconds against 50 million production rows. You won’t see it until customers do. No amount of careful staging configuration compensates for the fact that real usage patterns create data shapes that are genuinely impossible to predict and replicate in advance.
2. Third-Party Integrations Are Performing, Not Operating
Staging typically hits sandbox versions of external APIs: Stripe test mode, a mocked Twilio endpoint, a stubbed Salesforce connector. These sandboxes are polite. They respond quickly, they don’t rate-limit you, they return clean JSON, and they never go down for unannounced maintenance at 2am on a Tuesday.
Production integrations do all of those things. Stripe’s production API has different latency characteristics than test mode. Payment processors have specific behaviors around retries, idempotency keys, and webhook delivery ordering that sandboxes approximate but don’t replicate. When your checkout flow breaks because a webhook arrived out of order, staging was not present to warn you.
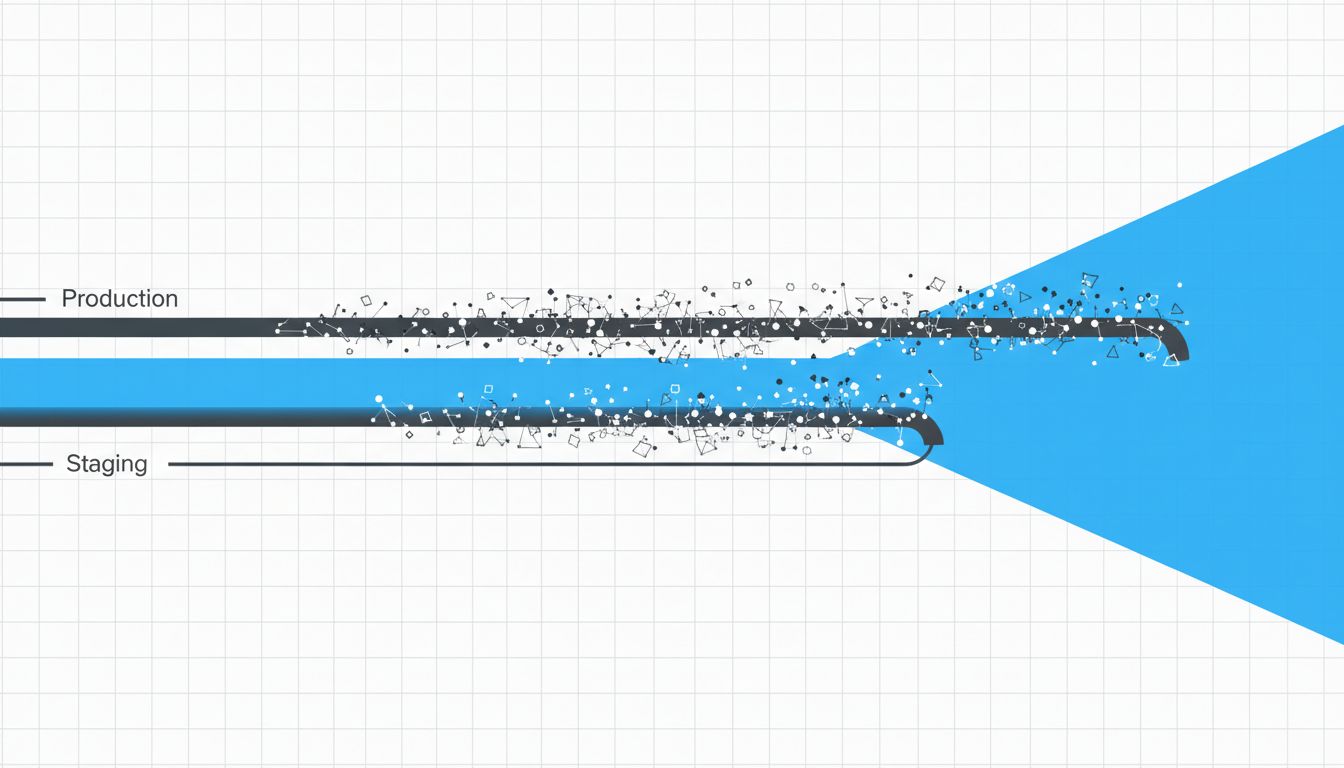
3. Traffic Shape Is Not Something You Can Fake
Load testing helps, but it’s a different kind of lie. You can simulate 500 concurrent users, but you can’t simulate the exact mix of operations those users perform, the session state they carry, or the way they hit your system after a marketing email goes out at 9am and creates a 40x spike in a specific funnel.
Real production traffic has memory. Users who signed up years ago have different object graphs than new ones. Your cache hit rates in staging are fiction because the cache was just warmed up by your test suite, not by a year of organic usage patterns. Cache misses in production are more frequent, more uneven, and more expensive in ways staging simply cannot reproduce.
4. Configuration Drift Is Slow and Silent
Staging environments rot. Not dramatically, but through accumulation. A feature flag gets toggled in production to fix something urgent and never gets synced back. An environment variable gets updated in production and someone means to update staging but doesn’t write a ticket. A database index gets added to production after a slow-query alert and nobody applies it to staging.
Six months later, staging and production are running different effective configurations, and nobody has a clean inventory of the differences. This is the norm, not the exception. The teams that manage it best are the ones who’ve accepted that drift is inevitable and built tooling to detect and reconcile it continuously, rather than treating staging as a once-configured artifact. As with how high-output teams actually define ‘done’, the discipline is in treating environment parity as an ongoing process, not a state you achieve once.
5. Observability in Staging Is Usually an Afterthought
When something breaks in staging, you care less. That sounds obvious, but the consequence is that staging tends to have weaker instrumentation. Fewer alerts, coarser metrics, no on-call rotation. This creates a perverse situation: the environment that’s supposed to catch problems before production is the one where you’re least equipped to understand what’s actually happening.
The irony is that you’d learn far more from staging if you treated it with production-level observability discipline. But most teams don’t, because the cost feels hard to justify for an environment whose failures have no user impact. The result is that bugs pass through staging not because staging didn’t surface them, but because nobody was watching carefully enough to notice.
6. Staging Builds Misplaced Confidence
This is the real problem, and it compounds everything above. If staging didn’t exist, teams would deploy more carefully. They’d think harder about rollback plans, feature flags, and incremental rollouts. They’d invest in canary deployments and production observability because those would be their only safety nets.
Staging, by existing, absorbs attention and budget that might otherwise go toward production-safe deployment practices. A team that deploys via feature flags to 1% of traffic has a much tighter feedback loop than one that runs a two-week staging validation cycle. The former catches real production bugs in minutes. The latter feels rigorous while missing the bugs that staging’s fundamental limitations guarantee it will miss.
The answer isn’t to eliminate staging outright. It’s useful for catching obvious regressions and giving developers a place to test integrations without touching real user data. But treating it as a reliable proxy for production behavior is the mistake. Staging is a development tool, not a safety guarantee. The teams that internalize that distinction are the ones that stop being surprised when production finds things staging didn’t.





