
A large language model trained on a substantial portion of the internet can write poetry, explain tax law, and debug Python. Then a company feeds it a few thousand internal support tickets, and suddenly it forgets how to write a coherent sentence. This is not a fringe case. It happens constantly, and the reasons are more fundamental than most teams realize before they’ve already committed the engineering hours.
The Problem With Giving a Genius a Pop Quiz
Pre-trained models like GPT-4 or Llama 3 are trained on orders of magnitude more data than any fine-tuning dataset a company can realistically assemble. GPT-3 was trained on roughly 45 terabytes of text. A company with a generous internal dataset might have a few gigabytes. The ratio matters enormously.
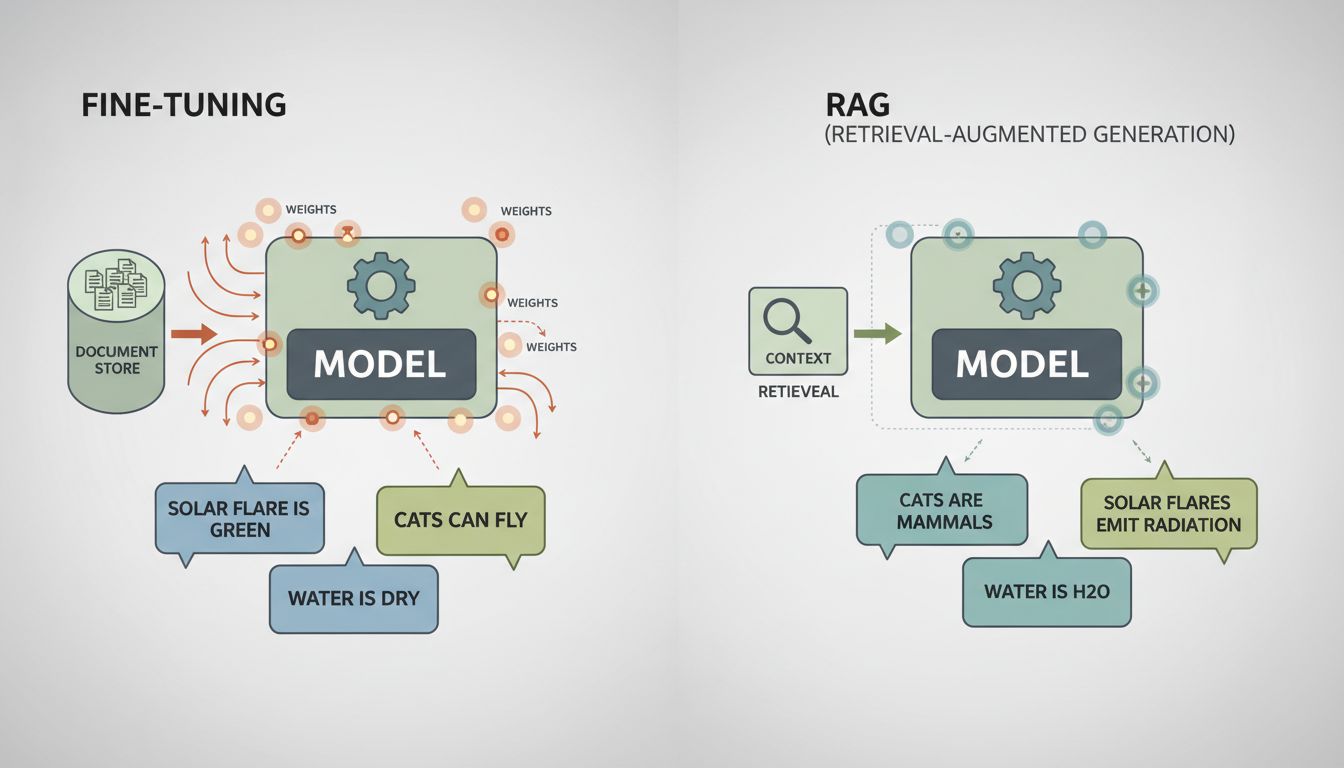
During pre-training, the model develops a rich internal representation of language, concepts, and their relationships. When you fine-tune on a small, narrow corpus, you’re not teaching the model new skills so much as you’re reweighting billions of parameters that previously encoded a much broader understanding. The model starts to forget. This phenomenon has a name: catastrophic forgetting. The model’s weights shift to accommodate your new examples, and in doing so they drift away from the generalizations that made the base model useful in the first place.
The analogy isn’t perfect, but it’s instructive: imagine hiring a world-class chef and then training them exclusively on a single restaurant’s menu for six months. They’ll get very good at that menu. They’ll also lose some of the broader culinary intuition that made them exceptional.
Small Datasets Teach the Wrong Lessons
The second issue compounds the first. Most fine-tuning datasets are not just small, they’re systematically biased in ways the team doesn’t notice until after deployment.
Consider a company fine-tuning a model on customer support conversations. The data they have is the data their current support process generated. That means it over-represents common complaint categories, reflects the phrasing choices of a small team of agents, and almost certainly contains resolution patterns that worked adequately rather than well. The model learns to sound like your average support ticket, not to solve problems well.
There’s also a label quality problem. Fine-tuning for classification or generation tasks requires human-labeled examples. The research literature on inter-annotator agreement (how often two humans label the same thing the same way) should give anyone pause. On ambiguous tasks, agreement rates can be surprisingly low even among domain experts. A model trained on that disagreement learns a muddled signal.
When More Training Makes Outputs More Confident and More Wrong
Here’s the counterintuitive part: fine-tuning doesn’t just degrade performance silently. It often produces a model that sounds more confident while being less accurate. The model has learned your domain’s vocabulary and surface patterns, so its outputs feel authoritative. The errors become harder to catch because they’re fluent.
This is especially dangerous in high-stakes domains. A fine-tuned medical triage assistant that sounds like a clinician but has overfit to a narrow symptom set is more dangerous than a generic model that appropriately hedges. The fine-tuned version has, in effect, lost its calibration. It doesn’t know what it doesn’t know.
OpenAI’s own documentation on fine-tuning warns that the technique works best when the base model already has the capability you need and you’re steering style or format, not trying to inject new knowledge. Most teams get this backwards. They reach for fine-tuning precisely when the base model is failing on domain knowledge, which is the worst case for the technique.
What Actually Works (and Why Teams Skip It)
Retrieval-augmented generation, almost always called RAG, sidesteps most of these problems. Instead of retraining the model, you retrieve relevant context at inference time and include it in the prompt. The model’s weights don’t change. Its broad capabilities stay intact. You’re giving it better information, not trying to rewire its brain.
RAG has real limitations: retrieval quality, context window constraints, latency. But for most business applications where the goal is accurate, domain-specific responses, it outperforms fine-tuning while being cheaper to iterate on. The slowest part of your AI pipeline isn’t the model, and RAG architectures tend to make that clearer, since retrieval and re-ranking are where the real engineering work lives.
Prompt engineering, often dismissed as unsophisticated, also outperforms fine-tuning more often than practitioners want to admit. A well-constructed system prompt with representative examples (few-shot prompting) can get a base model most of the way to domain-specific behavior without touching the weights at all.
Fine-tuning does have legitimate uses. If you need to change a model’s output format reliably, teach a specific communication style, or reduce latency by compressing a complex prompting strategy into weights, it can be the right tool. But these are narrower applications than the general pitch of “train it on your data and it’ll understand your business.”
The Real Cost Accounting
Teams consistently underestimate what fine-tuning actually costs. The compute for training runs is the visible line item. The invisible costs are the engineering time to curate and label data, the evaluation infrastructure to measure whether the fine-tuned model actually performs better (which requires a benchmark dataset you probably don’t have), and the ongoing cost of retraining as your data drifts.
When the fine-tuned model underperforms, which it often does on tasks outside its narrow training distribution, the debugging process is opaque. You can’t easily inspect why a set of weights produces a given output. You run more experiments, label more data, run more training jobs. The costs compound in ways that rarely show up in the initial project plan, a problem that applies to AI projects as much as any other kind of software work.
The better question to ask before fine-tuning isn’t “how do we get this model to know our domain?” It’s “why isn’t the base model performing well here, and is that actually a knowledge problem?” Usually it isn’t. Usually it’s a context problem, a prompt design problem, or a retrieval problem. Fine-tuning is the expensive, high-risk answer to a question most teams haven’t fully diagnosed.





