
The Problem Spotify Couldn’t Solve With Keywords
In the early 2010s, Spotify had a recommendation problem. The service had millions of songs and tens of millions of users, and it was trying to connect them using largely metadata-driven approaches: genre tags, tempo, key, manually applied labels. If you liked one indie folk artist, the system looked for other artists tagged “indie folk.” It worked, sort of, the way a card catalog works. Functional, but deaf to the actual music.
The deeper issue was structural. Human-assigned categories are discrete. A song is either in “indie folk” or it isn’t. But musical similarity is continuous. Sufjan Stevens and Bon Iver share something that neither shares with Metallica, and what they share with each other is different from what Sufjan shares with Nick Drake. There’s a gradient, a geometry, that flat category labels can’t capture.
Spotify’s engineers eventually turned to a technique that had been percolating in research circles for years: embeddings. The story of how they applied it, and what it revealed, is one of the cleaner case studies in why modern AI works at all.
What an Embedding Actually Is
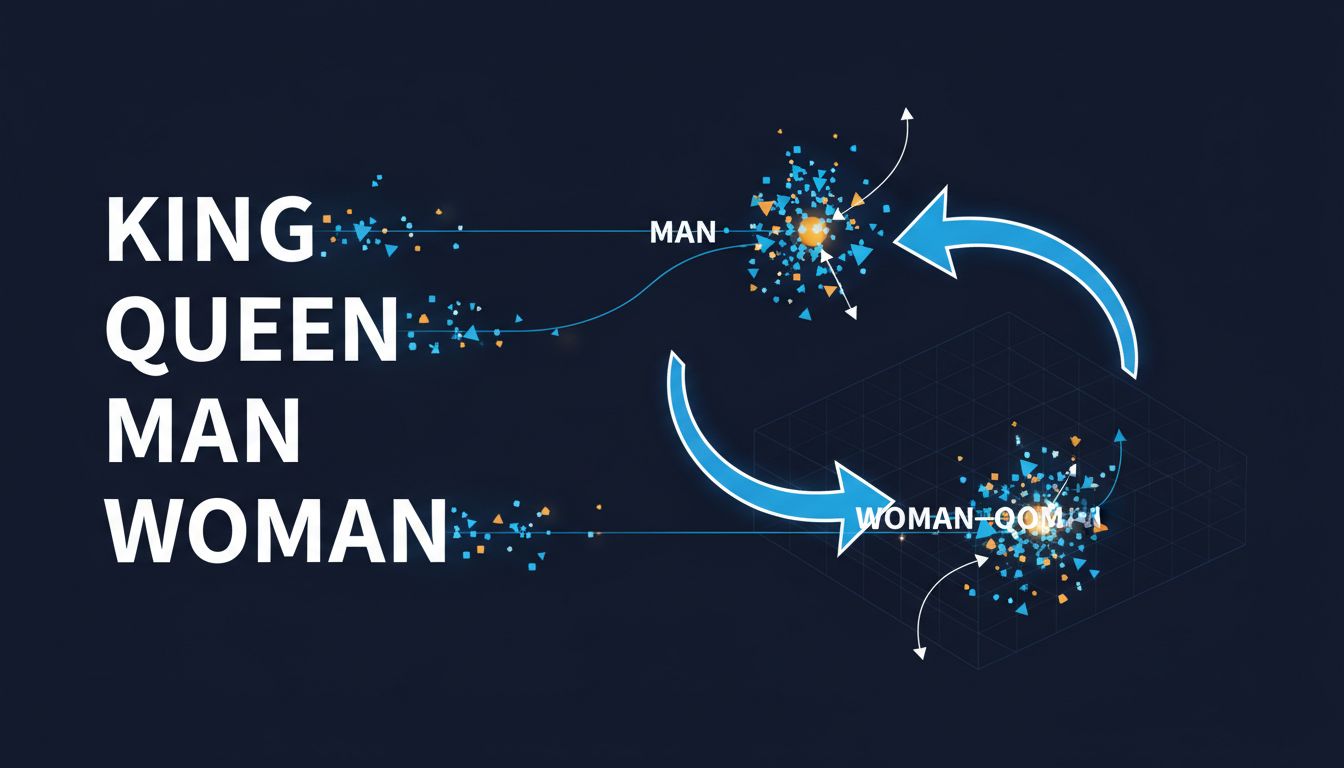
An embedding is a function that maps a thing (a word, a song, a user, a product) to a point in a high-dimensional vector space. That’s the whole definition. A 300-dimensional embedding of the word “king” is just a list of 300 numbers.
What makes this useful isn’t the mapping itself. It’s that the mapping is trained so that things which are similar in meaning end up geometrically close together. Distance in the vector space encodes semantic similarity.
The famous demonstration of this comes from Word2Vec, the embedding model Google researchers published in 2013. When you train Word2Vec on a large text corpus, you get vectors where arithmetic reflects meaning. The vector for “king” minus “man” plus “woman” lands very close to the vector for “queen.” The model learned that relationship from nothing but patterns in text. Nobody told it what royalty meant.
This is the trick. You don’t encode meaning manually. You let the geometry emerge from how words co-occur with each other. The structure of language, the statistical patterns of what appears near what, contains enough information to reconstruct something close to meaning.

How Spotify Applied It to Music
Spotify’s approach, which their data science team has written about publicly, used a technique inspired by Word2Vec but applied to listening behavior rather than text. The insight was to treat playlists as sentences and songs as words. If Word2Vec learns word relationships from words that appear near each other in sentences, you can learn song relationships from songs that appear near each other in playlists.
They trained a model on hundreds of millions of playlist sequences. Songs that users consistently grouped together ended up close in vector space. Songs that never appeared together ended up far apart. The model didn’t know anything about genre, tempo, or instrumentation. It learned purely from co-occurrence patterns in human behavior.
The results captured things keyword matching fundamentally can’t. Two songs in completely different genres but with similar emotional character, the kind of thing a human would group together without being able to articulate why, ended up near each other in the embedding space. The geometry encoded taste rather than taxonomy.
This is also how Spotify learned that user behavior contains more signal than explicit categories. The embeddings essentially crowdsourced the definition of similarity from millions of individual decisions about what to listen to next.
Why the Math Generalizes So Broadly
The reason this technique is now central to almost every serious AI application isn’t that it’s clever. It’s that it’s correct about something fundamental: most of what we mean by “understanding” a concept is understanding its relationships to other concepts.
Language models work on exactly this principle at massive scale. When OpenAI trained GPT-style models, they weren’t hard-coding facts about the world. They were training enormous embedding systems where the context of every word shapes a vector, and those vectors are processed to predict what comes next. The understanding is in the geometry.
Search engines use the same approach. When Google moved from purely keyword-based matching to neural embeddings with their BERT integration in 2019, search quality for long-tail queries improved significantly. A query like “can you get medicine for someone pharmacy” is semantically about proxy prescriptions, not just the literal words. An embedding model captures that. A keyword system doesn’t.
Document retrieval, fraud detection, drug discovery (where molecular structures are embedded as vectors and similarity search finds candidate compounds), recommendation at scale: all of these are, at the mathematical level, the same problem. Embed things. Measure distance. Return neighbors.
The Limits Worth Understanding
Embeddings aren’t magic, and the Spotify case illustrates some real limitations.
First, embeddings encode the biases in whatever data trained them. If certain genres are systematically underrepresented in playlist data because they skew toward older users who make fewer playlists, those genres get worse embeddings. The geometry reflects the population that generated the data, not the population you want to serve.
Second, embeddings are static snapshots. A model trained on playlists from 2018 doesn’t know about artists who emerged in 2022. Keeping embeddings current requires continuous retraining, which is expensive and creates its own challenges around consistency.
Third, and most importantly, embeddings are opaque. You can observe that two songs are close in vector space, but the 300 numbers don’t tell you why. The model found the pattern; you still have to figure out what it means. This matters for debugging and for trust. When a recommendation is wrong, you can’t easily interrogate the geometry to understand the failure.
The opacity issue extends to language models more broadly. The same representational power that makes embeddings useful also makes them hard to audit. More context can sometimes make these models perform worse, precisely because the geometry of the embedding space handles long-range relationships imperfectly.
What the Case Teaches
Spotify’s embedding work teaches a cleaner lesson than most AI case studies. The insight wasn’t about bigger models or better infrastructure. It was about recognizing that the right representation of the problem makes the solution almost automatic.
Keyword matching failed not because the algorithm was wrong but because the data structure was wrong. Categories are discrete; taste is continuous. Once you map songs into a continuous geometric space where distance encodes similarity, the recommendation problem becomes a nearest-neighbor search. The hard part is the embedding. The retrieval is straightforward.
This pattern repeats throughout software. The choice of representation shapes what’s possible before you write a single line of business logic. Choosing the right abstraction is doing most of the work.
For embeddings specifically, the practical takeaway is this: if you have a similarity or relevance problem, the right question isn’t “what’s my matching algorithm?” It’s “what’s my representation?” Once you have good embeddings, many problems that looked like hard AI problems reveal themselves to be geometry problems. And geometry is something we know how to solve.





