

A message queue and an append-only log look similar from the outside. Both accept writes. Both let other processes consume data. Both sit between producers and consumers in a system diagram. But they make opposite assumptions about what consuming data means, and that difference shapes everything downstream.
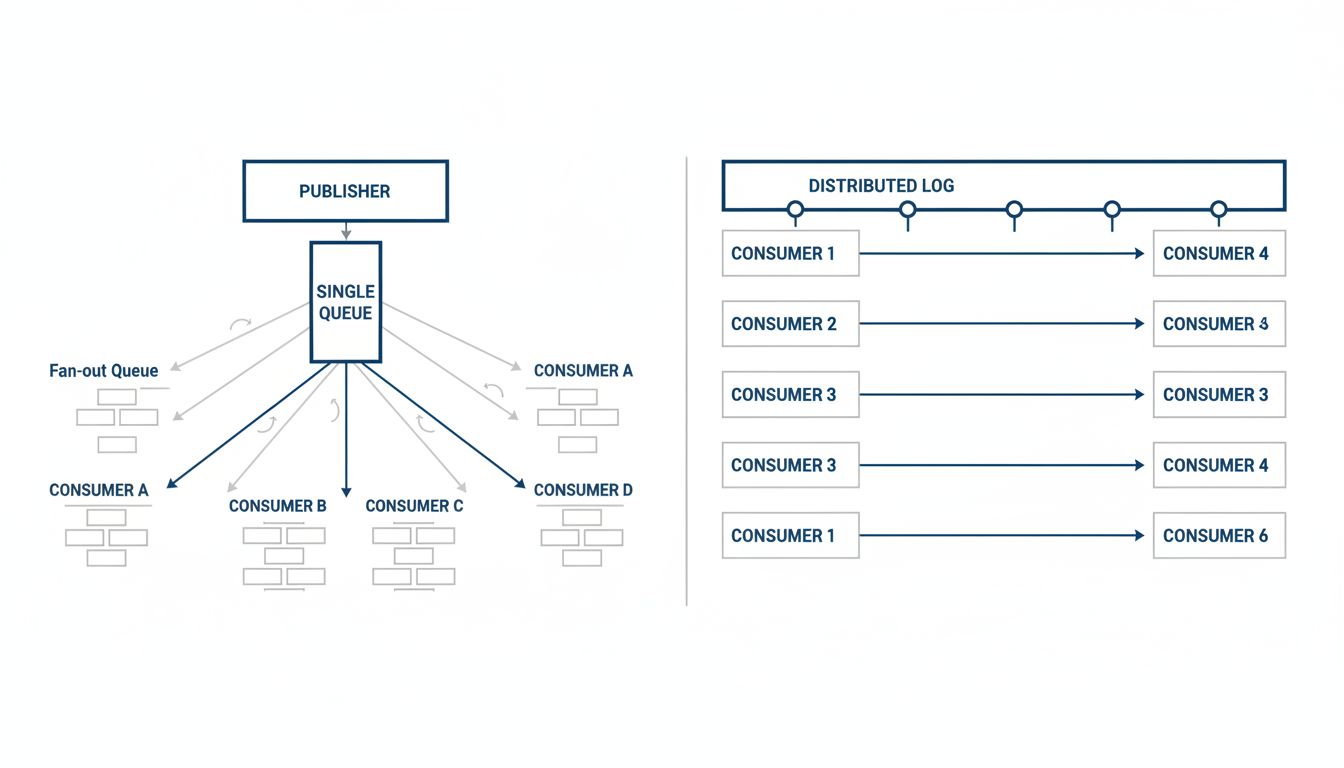
Most developers understand queues intuitively because queues are simple. A job goes in, a worker picks it up, the job disappears. RabbitMQ, SQS, Celery backed by Redis: the mental model is a to-do list that shrinks as workers process it. Queues are about work distribution. The message exists to be consumed and discarded.
A log is different. Kafka is the canonical example, but the concept predates it. In a log, messages are appended and retained. Consumers track their own position (an offset) in the sequence. Reading a message does not remove it. A new consumer can start from the beginning and replay everything. The log is the source of truth; consumers are stateless readers of it.
The confusion arises because queues can be made to approximate logs with enough configuration. SQS has long retention periods. RabbitMQ has persistent queues. Redis Streams, introduced in 2018, added consumer groups and offset tracking to a system most people use as a cache. Engineers reach for familiar tools and bend them, often without fully recognizing the tradeoff they’re accepting.
The Problem Isn’t Performance, It’s Semantics
The queue-versus-log debate gets framed as a performance question, but that framing misses the real issue. Yes, Kafka handles higher throughput than most queue implementations in practice. But the meaningful difference is semantic: what does it mean for a consumer to “read” a message?
In a queue, reading is consuming. Once a worker acknowledges a message, it is gone (or dead-lettered, if something went wrong). If you need a second system to act on the same event, you either duplicate the queue, implement a fan-out pattern, or build something more elaborate. Every new consumer requirement becomes an architectural problem.
In a log, reading is just reading. You can add a new consumer service, point it at offset zero, and replay every event in history. Your analytics pipeline can join the same stream as your notification service without either one affecting the other. This matters enormously when requirements change, which they always do.
The practical consequence: teams that build on queues for event data routinely find themselves implementing workarounds for the thing logs give you for free. Dead-letter queues to preserve failed messages. Duplicate queues for multiple consumers. External audit tables to recreate what a replay would have provided natively. The real cost of keeping a software product alive includes all of this accidental complexity, even when it doesn’t show up on any architectural diagram.
Where Queues Actually Belong
None of this is an argument that queues are bad. Queues are excellent tools for a specific, well-defined category of problem: distributing discrete units of work across parallel workers where exactly-once (or at-least-once) processing semantics matter and the result of processing is not itself interesting to other systems.
Background job processing is the paradigm case. A user uploads a video. A transcoding job goes into a queue. A worker picks it up, transcodes the video, and writes the output to storage. The queue message is an instruction, not a fact. Once the job is done, nobody needs the original instruction. The queue is the right tool here.
Order fulfillment workflows fit this pattern too. Inventory reservation, payment processing, shipping label generation: these are discrete tasks with clear completion states. They benefit from the backpressure and retry semantics queues provide. Modeling them as a log would add complexity without adding value.
The trouble is that the same infrastructure team that deployed RabbitMQ for background jobs also gets asked to handle “events” when the company decides to build an activity feed, an audit trail, or a data pipeline. The queue is already there. It handles writes. Why not use it?
When the Wrong Tool Teaches You the Right Lesson
Many organizations learn this distinction the hard way when they try to rebuild history from a queue-based system and find there is no history to rebuild. The queue did its job: it deleted everything after it was processed.
This is particularly acute in audit and compliance contexts. A queue tells you what work got done if you instrument it carefully. A log tells you what happened, period, because the events themselves are the record. Financial services companies running transaction processing on queue-based infrastructure frequently maintain parallel database tables just to reconstruct the event history the queue throws away. They’ve built a log manually, on top of a queue, at considerable cost.
Apache Kafka was designed at LinkedIn specifically because this problem kept recurring. The engineering team published their reasoning: they needed a system where multiple consumers could independently process the same stream of events, where consumers could fall behind and catch up, and where the event history was durable by default. None of that was achievable with the queue-based tools available at the time. They built a log.
The insight wasn’t that queues are bad. It was that event data and job data have different shapes and different retention requirements, and a single abstraction can’t serve both well.
Choosing Before You Build
The question to ask before reaching for either tool is not “what delivers my messages?” but “what is the message for?”
If the message is an instruction, a task, a unit of work that one consumer should process and complete, use a queue. If the message is a fact, an event that occurred and that multiple systems may need to know about now or later, use a log. The distinction sounds obvious when stated plainly. It gets obscured when the same word (“message”) describes both.
For teams evaluating this choice mid-project, the practical signal is this: if you have ever found yourself building an audit table alongside a queue, or wiring up fan-out patterns to duplicate messages to multiple consumers, you are probably using a queue to do a log’s job. The refactor to a proper log-based system is not painless, but it tends to simplify everything it touches.
The append-only log is one of the most underrated ideas in distributed systems. It makes replay free, fan-out trivial, and event history durable by default. Kafka made it accessible at scale. But the idea itself is older, simpler, and worth understanding on its own terms before you reach for any specific tool.





