
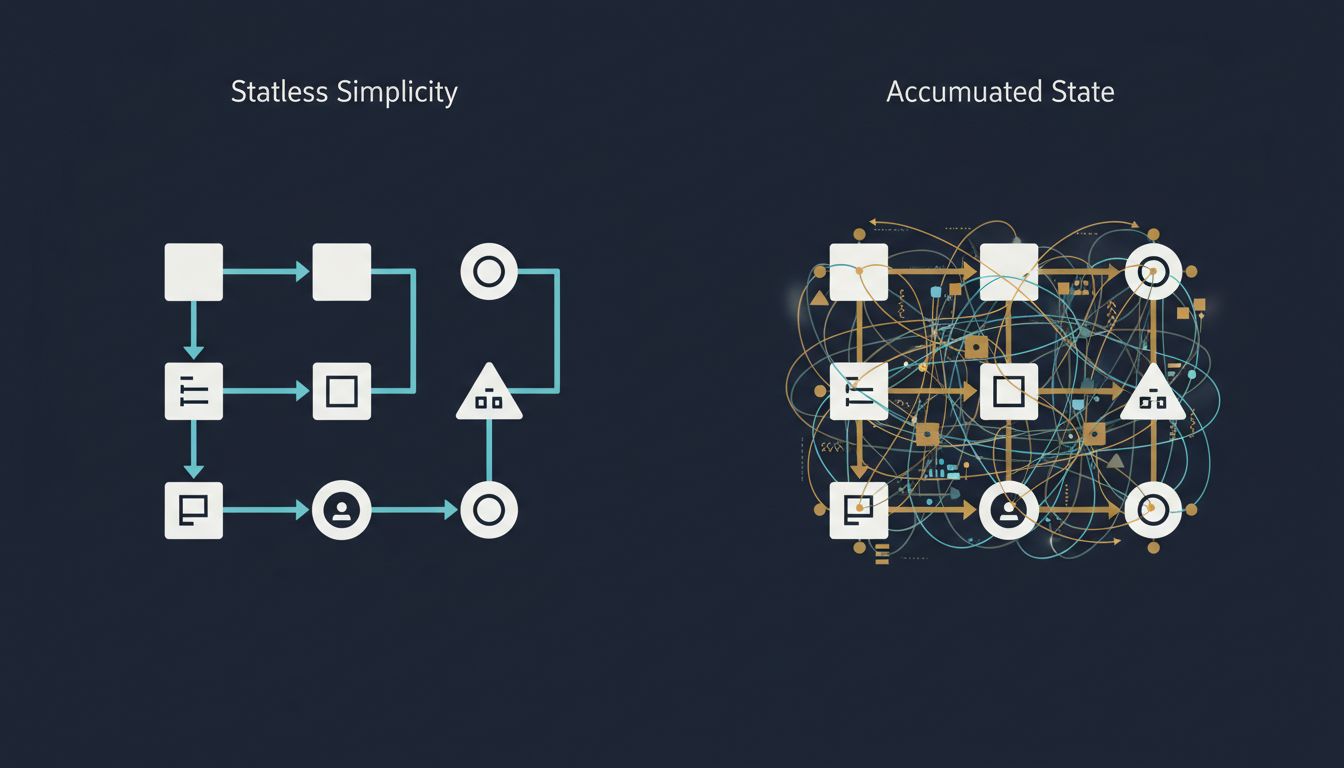
The promise of stateless design is compelling: a function takes inputs, produces outputs, and has no memory of what happened before. You can run it ten times and get the same result. You can run it on any server in your cluster. You can kill it, restart it, and nothing is lost. This is the kind of system that lets you sleep well.
And yet, across codebases and teams and companies of every size, you watch systems accumulate state like sediment. Sessions, caches, flags, queues, cursors, locks. Every addition has a reason. Every addition makes the system slightly harder to understand. The question isn’t why developers add state carelessly. It’s why careful developers add it anyway.
What Statelessness Actually Gives You
Before unpacking why state creeps in, it helps to be precise about what you’re trading away when it does.
A stateless function is, in the mathematical sense, a pure function: given the same inputs, it always produces the same outputs, and it causes no side effects. In practice, “stateless” in distributed systems means something slightly looser: the service itself holds no session-specific data between requests. All the information needed to process a request arrives with the request.
The concrete benefits are significant. Horizontal scaling becomes trivial because any instance can handle any request. Debugging is dramatically easier because you can reproduce a failure by replaying the inputs. Testing coverage is more reliable because you don’t have to construct elaborate before-states to exercise a code path. And failure recovery is cheap because a crashed instance can simply be replaced without asking “what was it in the middle of doing?”
HTTP, at the protocol level, was designed to be stateless. Each request carries everything the server needs: method, headers, body. That design choice is a large part of why the web scaled the way it did. Cookies were bolted on afterward, and they were the first crack in the wall.
The Pressure That Creates State
Here is what actually happens in practice. You build a stateless API endpoint. It works. Then product asks for user authentication. You add a session token. That token lives somewhere, which means something has to store it, which means you now have a stateful store. You’ve introduced state not out of laziness but out of a genuine requirement.
Then product asks for rate limiting. You need to know how many times a user has called this endpoint in the last minute. That information has to live somewhere, too. Redis gets added to the stack. Now you have a cache layer with its own failure modes, its own consistency questions, and its own operational overhead.
Then you need to send an email when a certain workflow completes, but the workflow spans multiple requests, which means you need to track where in the workflow each user is. Queue. Worker process. Job status table in Postgres.
None of these decisions were wrong in isolation. But the cumulative effect is a system that is now very hard to reason about because the state is distributed across a session store, a cache, a queue, and a database, and the interactions between them are implicit.
This is the trap: state isn’t usually added to a system carelessly. It’s added incrementally, each addition justified, each addition small. The problem is that state compounds. Two stateful components don’t give you twice the complexity; they give you the complexity of each component plus the complexity of their interactions.

The Hidden Cost of Distributed State
When state is localized (say, inside a single database with ACID transactions), the complexity is at least contained. The database makes promises about consistency, and you can reason about what those promises mean for your application.
Distributed state is different. If you cache a user’s account balance in Redis and also store it in Postgres, you have two sources of truth. They will drift. Maybe not often, maybe not by much, but under the right conditions (a network partition, a deployment, a slow write), they will give different answers to the same question. The bugs this creates are some of the hardest to reproduce and diagnose. They’re the kind that appear in production on a Tuesday and vanish before you can attach a debugger. (The Bugs That Never Get Filed is full of cousins to this problem.)
The CAP theorem (consistency, availability, partition tolerance: pick two) isn’t just a theoretical constraint. It’s a description of the choices you’re making whether you acknowledge them or not. When you add a distributed cache, you are implicitly choosing availability over strict consistency. That’s sometimes the right call. But it should be a deliberate call, not a side effect of “let’s add Redis for performance.”
Why AI Systems Blow This Up Even Further
The statelessness question has become more acute in the context of AI and machine learning systems, because those systems want to be stateful by nature.
A language model, at inference time, is actually stateless: you send it a context window, it produces an output. But making that model useful in a product means maintaining conversation history, user preferences, retrieved documents, tool call results, and intermediate reasoning steps. You end up building a stateful scaffolding around a stateless core, and the stateful parts are where almost all the failure modes live.
Consider an AI agent that takes multi-step actions: it retrieves documents, calls external APIs, writes intermediate results to a scratchpad, and then generates a final answer. The model itself is stateless. But the agent framework has to track which steps have been completed, which have failed, and what to do about retries. That state has to be stored somewhere, it has to survive failures, and it has to be consistent. All the old distributed systems problems come back, wearing a new hat.
This matters because teams building AI products often come from research backgrounds where the model is the product, and the model is stateless. The operational complexity of the stateful scaffolding catches them off guard. Understanding what an LLM is actually doing during inference is one thing; understanding the failure modes of the stateful system wrapped around it is a different discipline entirely.
When State Is the Right Answer
It would be a mistake to conclude from all this that state is always bad. That’s not the position. State is unavoidable in any system that models something that changes over time, which is most systems. The question is how you manage it, not whether you eliminate it.
Event sourcing is one pattern that takes this seriously. Instead of storing current state, you store the sequence of events that produced the current state. The current state becomes a derived view, recalculated from the log. This makes state explicit and auditable. You can reconstruct what the system looked like at any point in time by replaying events up to that point. The tradeoff is operational complexity and storage costs, but for systems where audit trails or temporal queries matter (financial ledgers, compliance systems, certain collaboration tools), it’s often worth it.
CQRS (Command Query Responsibility Segregation) takes a related approach: separate the model you write to from the model you read from. The write model handles commands and emits events. The read model materializes those events into whatever shape queries need. The state still exists, but its boundaries are explicit and its movement is documented.
The common thread in these patterns is that they make state visible. The problem with the Redis cache scenario isn’t that state exists; it’s that the state is implicit, undocumented, and its relationship to the authoritative store is a matter of convention rather than contract.
The Design Discipline You Actually Need
The practical answer to “why do we keep adding state?” is that we don’t have a consistent discipline for deciding when state is justified and when it should be pushed out of the system.
A useful heuristic: before adding any stateful component, ask what the source of truth is and how readers know when their view of it is stale. If you can’t answer both questions cleanly, you probably aren’t ready to add the state yet.
Another: treat your state boundaries the way you treat your API boundaries. Document them. Make them explicit in your architecture diagrams. When a new engineer joins, can they look at a single artifact and understand where state lives in your system and what moves it? If not, the state has already won.
There’s also a timing discipline. State added early in a system’s life is far more expensive than state added late, because early additions shape the mental model everyone develops about how the system works. This is related to why deleting a database column is never simple: once state exists, removing it is almost always harder than adding it was.
The teams that manage this best treat statelessness as a default and state as something that needs to be argued for, designed explicitly, and documented thoroughly. They don’t avoid state; they make adding it feel expensive, because it is.
What This Means
Stateless systems are easier to scale, test, debug, and recover from failure. That’s not a preference; it’s a consequence of their properties. The reason we keep adding state is that real requirements (user identity, rate limits, long-running workflows, caches) genuinely need it. The problem isn’t that state gets added; it’s that it gets added incrementally without accounting for the cumulative cost.
The key moves: treat state as a design decision that needs to be explicit and justified, not a side effect of implementation. Prefer localized state over distributed state where you have a choice. When you do distribute state, make the consistency model a first-class part of your design, not an afterthought. And build a habit of asking “where does this state live, and who is allowed to change it?” before any new component gets wired in.
The systems that stay maintainable over years aren’t the ones that avoid state entirely. They’re the ones where state is treated with the same seriousness as any other architectural constraint.





