The most dangerous database operation isn’t a complex JOIN across a billion rows or a schema migration that adds a new index to a hot table. It’s the humble DROP COLUMN. The operation looks trivial. It is not.
Software engineers encounter this mismatch early in their careers: the gap between what a command does logically and what it does operationally. Dropping a column removes a piece of data you’ve decided you no longer need. Sounds like cleanup, sounds like discipline, sounds like the kind of housekeeping that makes a codebase healthier. The reality is that deleting a column from a production database table is a multi-step process that, done naively, can take down your application, corrupt data in flight, or create conditions for silent failures that surface weeks later.
The Lock Problem
In most relational databases, ALTER TABLE DROP COLUMN acquires a lock. In older versions of MySQL (pre-5.6 for most operations, and still true for many scenarios today), this meant a full table lock for the duration of the operation. On a large table, that duration can stretch from seconds to minutes. During that window, every write to the table queues up waiting for the lock to release. If the table is under constant write pressure, the queue grows, connections pile up, and eventually the application starts throwing errors. You haven’t dropped a column; you’ve staged an outage.
PostgreSQL handles this differently but not trivially. The DROP COLUMN operation in Postgres is a logical operation: it marks the column as dropped in the system catalog without immediately rewriting the table. This is faster, but it still acquires an ACCESS EXCLUSIVE lock that blocks all reads and writes for its brief duration. On a busy system, even a brief exclusive lock can be catastrophic if it arrives at the wrong moment in a transaction-heavy workload.
The tools built to address this (Percona’s pt-online-schema-change, GitHub’s gh-ost, and Postgres’s own lock_timeout parameter) exist precisely because the naive approach is genuinely risky. Their existence is the tell.
The Application Code That Hasn’t Shipped Yet
Locks are the obvious danger. The subtler one involves deployment timing.
Consider the sequence: you decide column legacy_price is unused. You audit the codebase, find no references, run the migration, and drop the column. What you may not have accounted for is the version of your application that is currently running in production. In a rolling deployment, old instances of your app may still be alive for minutes or hours after the new version starts serving traffic. Those old instances still reference legacy_price in their ORM models or raw SQL queries. The moment the column disappears from the database, they start throwing errors.
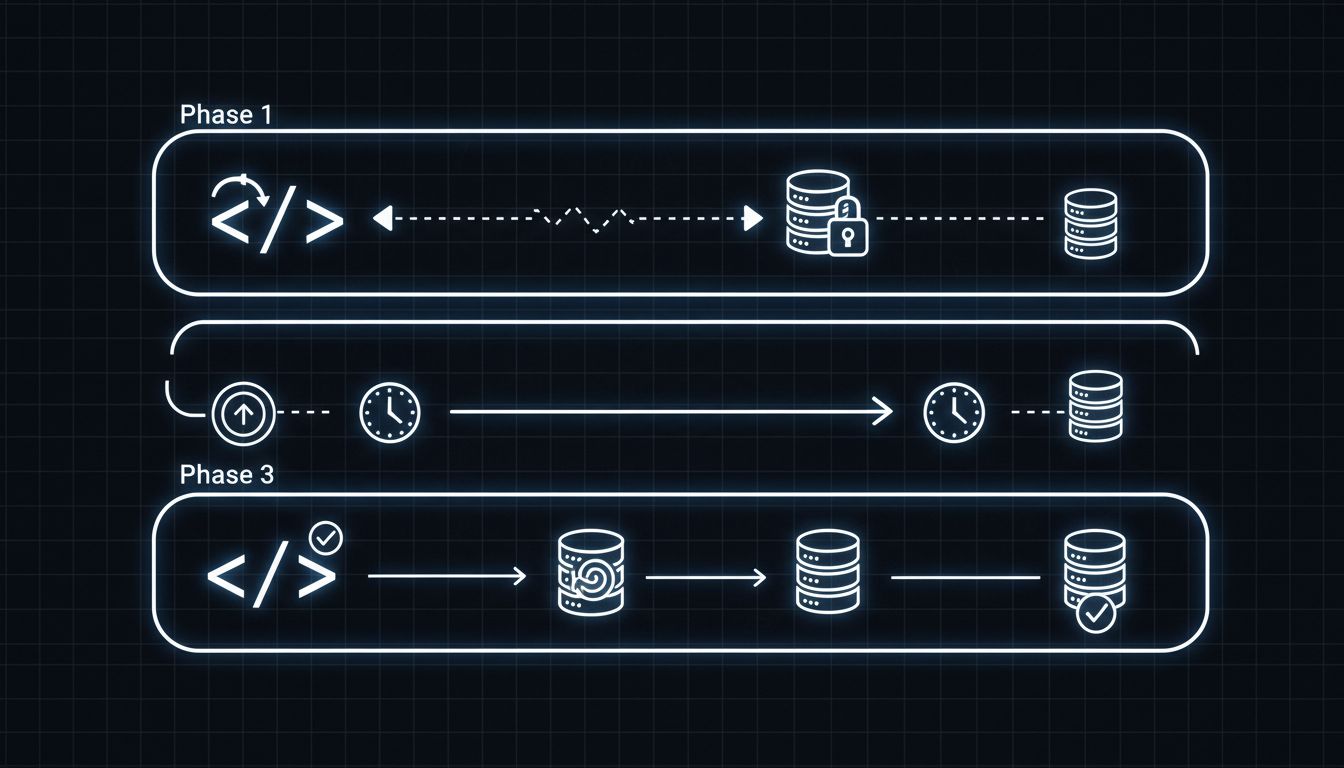
This is why the standard safe practice requires three separate deployments. First, you deploy code that stops writing to the column but still reads it (or simply stops referencing it). Second, you let that version run in production long enough to be confident no rollback will reinstantiate the old code. Third, you drop the column. This three-phase approach is operationally sound but organizationally painful. Most teams skip to phase three, especially under schedule pressure.
The same logic applies in reverse when you consider rollbacks. If you drop a column and then need to roll back the application code for unrelated reasons, you’re now running application code that expects a column that no longer exists. A rollback that should be safe becomes a data-layer crisis.
The Hidden Dependents
Auditing application code is at least tractable. The harder problem is auditing everything else.
Columns have a way of acquiring dependents that don’t show up in a standard code search. Analytics pipelines that query the database directly, sometimes written by data teams who operate independently of the engineering team. ETL jobs that run on schedules, possibly owned by a third-party vendor. Cached queries in an ORM’s query cache that were built against the old schema. Views and stored procedures that reference the column. Materialized views that were built from it. Triggers that fire on table updates and reference the column’s value.
In organizations with strong data governance, there is documentation of these dependencies. In most organizations, there is not. The engineers who wrote some of these dependencies may have left the company. The column you’re dropping might be the one feeding a reporting dashboard that the CFO looks at every Monday morning. You will find out about this on a Monday morning.
This is a version of the same problem that makes deleting a feature the hardest call in engineering: the blast radius is always larger than it appears from inside the codebase.
The Safe Path Is Boring
The correct process for dropping a column is not complicated. It is simply slower than engineers want it to be, and it requires coordination that most deployment pipelines aren’t built to enforce.
Start by making the column nullable if it isn’t already, and stop writing to it. This decouples the column’s presence from any active business logic. Then audit dependencies beyond the application code: run queries against your database’s information schema to find views, stored procedures, and triggers. Grep your data infrastructure for the column name. Talk to the analytics team. Set the column to return null or a default value for any reads, and monitor for anything that breaks.
After a waiting period (the right length depends on your release cadence and data retention policies, but weeks rather than days is appropriate for any table that matters), remove references from application models and deploy that code. Let it run. Then, and only then, drop the column. Do it during low-traffic hours. Use a tool like gh-ost or pt-osc if you’re on MySQL. Set a lock_timeout in Postgres so the operation fails fast rather than blocking indefinitely if something goes wrong.
What This Reveals About Infrastructure Debt
The difficulty of dropping a column is diagnostic. It reveals something about how systems accumulate invisible dependencies over time, and how operations that feel administrative carry real operational risk. A codebase in which you can safely drop a column in a single migration is a codebase where dependency tracking has been treated as a first-class concern from the beginning. That is rare.
The engineers who know this and act on it tend to be the ones who treat schema changes with the same rigor as API contract changes. Because that’s what they are. A database schema is a contract between your application and your data layer, and breaking a contract in production has consequences regardless of whether the syntax was valid SQL.
Cleaning up old schema is worth doing. The systems that stay healthy over years are the ones that shed accumulated technical debt deliberately rather than letting tables grow into archaeological sites of abandoned features. The point is to do it without breaking anything, which means treating the boring multi-step process as the actual standard rather than the cautious exception.