

What the Compiler Actually Throws Away
Write a function called calculateMonthlyInterestAccrual and by the time your processor executes it, that name is gone. Not compressed, not abbreviated. Gone. The CPU receives a memory address, something like 0x4005a3, and it follows that address the way water follows a pipe. It has no idea what you called the pipe.
This is the foundational fact of compiled software that most developers intellectually know but rarely sit with long enough to understand its implications. The source code you write is not the program that runs. It is a description of a program. The compiler is a translator, and like all translators, it makes choices about what to preserve and what to discard. Names, in almost every compiled language, are among the first casualties.
Understanding this gap between the code you write and the instructions that execute is not an academic exercise. It explains why debugging is hard, why security vulnerabilities appear in code that looks correct, why performance profilers sometimes return results that seem to contradict the source, and why the entire discipline of reverse engineering exists as a profession.
The Translation Happens in Stages
A modern compiler does not perform a single transformation. It performs several, each one moving the representation further from human intent and closer to machine reality.
The first stage, parsing, converts your text into an abstract syntax tree. The tree preserves structure and relationships but starts discarding the superficial. Whitespace disappears. Comments disappear. The semantic content of your identifiers begins to matter less than their relationships to each other.
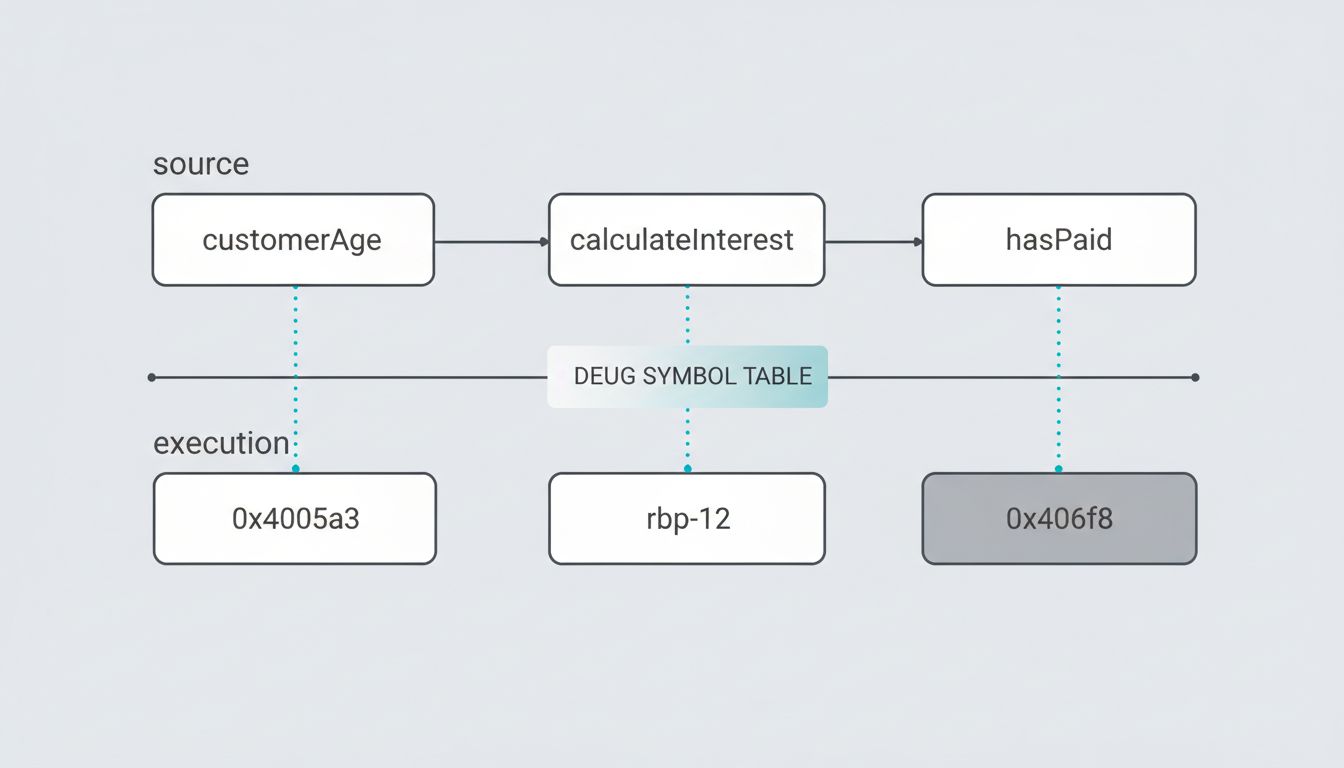
The second major stage is where names get their final demotion. During semantic analysis and symbol resolution, the compiler maps every identifier to a scope, a type, and ultimately a location. Once that mapping is recorded in the symbol table, the name itself has served its purpose. When the compiler emits intermediate representation, it is already working with references and offsets, not words.
By the time code generation runs, the compiler is thinking in registers and stack frames. A local variable is a slot at a specific offset from the stack pointer. A function is an entry point. An object’s field is a byte offset from a base address. The compiler knows customerAge lives at rbp - 12. It does not need to remember what you called it.
In an optimized release build, the situation is even more extreme. The optimizer may eliminate the variable entirely if it determines the value can be held in a register for its entire lifetime. It may inline your carefully named function, scattering its instructions across the call site as if the function boundary never existed. It may reorder your operations, combine your loops, or replace a division with a multiply-and-shift sequence that produces the same result faster. The structure you expressed in source is now a set of constraints the optimizer worked within, not a template it faithfully reproduced.
Debug Symbols Are a Separate Artifact
If names disappear during compilation, how does a debugger show you variable names when you set a breakpoint? The answer reveals something important: debug information is not embedded in the program. It is attached to it.
Formats like DWARF (used on Linux and macOS) and PDB (used on Windows) are separate data structures that map machine addresses back to source locations, variable names, type information, and line numbers. When you compile with debug symbols enabled, the compiler generates this mapping as a side effect and stores it either in a separate file or in a dedicated section of the binary.
This is why stripping a binary, removing its debug symbols, is a distinct operation from compiling it. The program runs identically either way. The debug information is purely retrospective. It exists to help humans reconstruct intent after the fact, not to help the machine execute.
When a security researcher reverse-engineers a stripped binary, they are doing exactly this reconstruction. They have the machine instructions, the addresses, the call patterns. They assign new names based on what they observe: sub_4005a3 becomes validate_license_key once they understand what the function does. The original name is unrecoverable. The behavior, however, is fully present.
Why This Matters for Security
Security engineers think about the compiler’s amnesia constantly, because attackers do.
Consider a developer who writes a conditional check: if (userHasPaid) { unlockFeature(); }. The compiled output does not contain a boolean called userHasPaid. It contains a comparison instruction operating on a register or memory location, followed by a conditional jump. An attacker with access to the binary does not need to find the variable. They need to find the conditional jump and flip it, either by patching the binary or by manipulating the value in memory at runtime.
This is why software license enforcement that relies purely on a flag in memory is structurally weak. The protection is not invisible just because the variable name is gone. The pattern of a comparison followed by a branch is a recognizable shape in any assembly listing. Obfuscation schemes try to make these patterns harder to find, but they work against the difficulty of searching, not against any fundamental opacity. The behavior is always there.
The same principle applies to buffer overflows. A developer writes code with clearly named bounds variables, expecting the structure to communicate intent. The compiled output is a sequence of memory accesses with specific offsets. If the bounds check can be made to fail, the named variable that was supposed to prevent the overflow is irrelevant. It no longer exists at the level where the attack occurs.
Interpreted Languages Don’t Escape This
Python, Ruby, and JavaScript programmers sometimes assume this problem belongs to the compiled world. It does not.
Interpreted languages preserve names longer, but they are not immune to the same fundamental translation. JavaScript engines like V8 compile frequently-executed code to native instructions through a process called just-in-time compilation. When V8 optimizes a hot function, it applies many of the same transformations a static compiler would: inlining, dead code elimination, type specialization. Variable names, if retained at all, live in a separate structure.
Python’s bytecode compiler, which runs before the interpreter ever touches your code, performs its own version of name resolution. Local variable names in a function get converted to indexed slot accesses. CPython’s dis module will show you the output: LOAD_FAST 0 instead of LOAD_FAST customerAge. The index is what matters at runtime.
The degree of name retention varies. Python does preserve more metadata than a stripped C binary, which is part of why Python introspection and dynamic attribute access work. But the execution engine does not use names as its primary mechanism. The names you see in a stack trace are reconstructed from stored metadata, not read directly from execution state.
The Useful Implication for How You Write Code
None of this means variable names don’t matter. It means they matter exclusively for the humans who read and maintain the code, which is the strongest possible argument for naming things well.
When the machine doesn’t care about names, the only beneficiary of a good name is a human. That human is often you, six months later, trying to understand a bug. Or a colleague trying to extend a feature. Or a security auditor trying to determine whether a check is correct. A developer hour costs far more than it appears on payroll, and a meaningful fraction of that cost is spent reconstructing intent from ambiguous names.
But there is a subtler implication. Because the compiler is going to translate your code anyway, and because modern optimizers are sophisticated enough to produce identical output from differently-structured source, the performance argument for writing cryptic, abbreviated code has largely collapsed. A function called calculateMonthlyInterestAccrual compiles to the same instructions as one called cmia. The readability cost is real. The performance cost is almost always zero.
This also reframes the debugging experience. When a debugger shows you a variable name, it is performing an act of translation in reverse, consulting the debug symbol table to show you the human-readable version of a machine address. When the debugger can’t find a variable, it often means the optimizer eliminated it entirely because it was never needed at that point in execution. The code looks wrong because the source-level model and the execution-level model have diverged. Understanding that divergence is the skill that separates engineers who can work from first principles from those who are stuck when the abstraction leaks.
What This Means
The source code you write is a communication to two audiences: the compiler, which will discard most of it in service of generating correct and efficient machine instructions, and the humans who will read and change it later. The compiler’s needs are largely mechanical and well-understood. It needs syntactic correctness, type consistency, and clear control flow. It will figure out the rest.
The humans’ needs are harder to satisfy. They need intent, context, and clarity. Those qualities live entirely in the parts the compiler throws away: names, comments, structure, the choice to extract a function rather than inline a calculation.
Treating code as a document for human readers, with the compiler as a secondary consumer, is not a soft preference about style. It is the accurate description of how compilation actually works. The machine will always recover what it needs. The question is whether the humans can.





