
You type a question, hit enter, and assume the model is reading exactly what you wrote. It isn’t. Between your keyboard and the model’s attention mechanism, your text goes through several transformations, each one quietly shaping what the model actually processes. Most prompt advice skips this entirely, which is why so much of it feels like superstition. Here’s what’s actually happening.
1. Your Words Become Numbers Before Anything Else
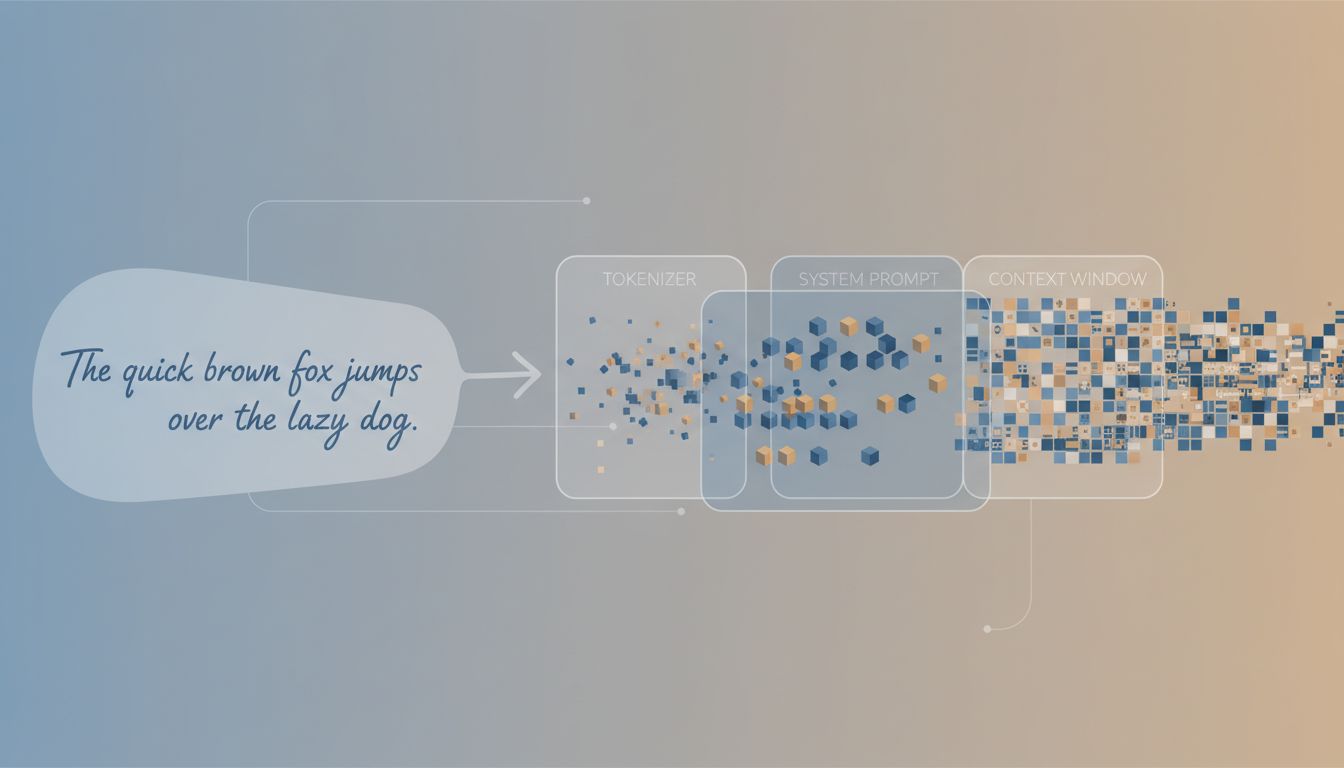
Models don’t read text. They read tokens, which are chunks of your input that have been mapped to integers through a process called tokenization. A token is roughly 4 characters in English, but that average hides a lot of variance. The word “unbelievable” might be one token or three, depending on the tokenizer. Code, URLs, and non-English text tend to tokenize poorly, meaning they consume more tokens per unit of information.
This matters practically. When you write a prompt in all-caps for emphasis, you’re often splitting words into more tokens and potentially confusing the model rather than emphasizing anything. When you write “don’t” instead of “do not,” you’re sending a different token sequence that some models weight differently. The model has no concept of your intention to stress a word. It only sees the token stream.
2. Your Prompt Is Almost Never the First Thing in the Context Window
If you’re using a product built on a model (a coding assistant, a customer service bot, a writing tool), there is almost certainly a system prompt sitting before your input. This system prompt was written by someone at that company to shape the model’s behavior, set its persona, restrict certain topics, or tune its output format. Your prompt gets appended after it.
The model reads both together. That means the system prompt’s instructions can override yours, conflict with yours, or subtly bias the model’s interpretation of what you’re asking. When a tool seems to stubbornly ignore part of your request, a conflicting system prompt is often the reason. You’re not arguing with the model. You’re arguing with whoever wrote that prompt before yours.

3. Retrieval-Augmented Pipelines Add Text You Never Wrote
Many production AI features use retrieval-augmented generation (RAG), where the system pulls relevant documents from a database and stuffs them into your prompt automatically. From the model’s perspective, your short question arrives padded with potentially thousands of tokens of retrieved context.
The practical consequence: the model is balancing your explicit instruction against a large block of retrieved text, and it doesn’t always prioritize your instruction. If the retrieved documents are noisy or only partially relevant, the model can drift toward answering what the documents suggest rather than what you asked. RAG doesn’t fix hallucinations so much as redirect them, and understanding that the retrieved text is part of your effective prompt helps you diagnose why you’re getting unexpected answers.
4. Position in the Prompt Changes What Gets Attended To
Research on transformer attention patterns has consistently shown that models pay more attention to the beginning and end of a context window than to the middle. This is sometimes called the “lost in the middle” problem, and it was documented specifically in long-context settings by researchers at Stanford and other institutions.
In practice: if you’re writing a long prompt with critical instructions, don’t bury them in the middle. Put your most important constraint either at the start or immediately before the part where you want the model to generate. If you’re sending a long document for analysis, your specific question about it should follow the document, not precede it, or you risk the model treating the question as preamble rather than instruction.
5. Temperature and Sampling Happen After Your Prompt, Not Because of It
You write a careful, precise prompt. The model generates a response. But between the model’s probability distribution and the words you see, there’s a sampling step controlled by parameters like temperature, top-p, and frequency penalties. These are set by whoever deployed the model, not by you, and they significantly affect output quality.
High temperature makes the model more creative and more likely to contradict itself. Low temperature makes it more conservative and repetitive. If you’re getting outputs that seem almost right but keep drifting in random directions, the problem may not be your prompt at all. It may be that the sampling parameters are miscalibrated for your use case. If you have access to the API directly, testing your prompt at different temperature values is worth doing before spending more time rewriting the prompt itself.
6. Chat History Is Injected Into Every Turn
In a multi-turn conversation, your latest message is not what the model reads. It reads the entire conversation history, formatted and concatenated, as a single long prompt. Every previous message, including the model’s own responses, is part of the context influencing the next output.
This is why conversations degrade over time. Early responses, even bad ones, shape what comes later. If the model gave you a slightly wrong framing in turn three of a ten-turn conversation, turns four through ten are all downstream of that mistake. The fix is not to keep prompting harder. The fix is to start a new conversation, or to explicitly correct the framing in a way that overrides the earlier context. “Ignore what you said earlier and approach this fresh” is not just a rhetorical move. It’s a genuine instruction that the model can act on.
7. Prompt Injection Is Real and You’re Probably Exposed to It
If you’re building something where the model processes user-supplied content (documents, emails, web pages), that content can contain instructions that the model will follow. This is called prompt injection, and it’s not an edge case. Attackers can embed invisible instructions in documents that redirect the model’s behavior, leak system prompts, or generate harmful outputs.
The deeper point here is that this attack is possible precisely because the model cannot distinguish between “instructions from the developer” and “instructions from the document.” It all becomes tokens. The model has no inherent trust hierarchy. Building applications that assume otherwise is a real security problem, and the prompt engineering work you do today may behave differently as models change anyway. Treating prompt security as a first-class concern from the start saves a lot of pain later.
The gap between what you type and what the model processes is not trivial. Tokenization, system prompts, retrieved context, positional attention biases, sampling parameters, conversation history, and injection attacks all sit between your intention and the model’s output. Once you understand these layers, prompt writing stops being guesswork and starts being engineering.





