
The Surprising Staying Power of a 1970 Invention
The B-tree was invented by Rudolf Bayer and Edward McCreight at Boeing Research Labs in 1970. It was designed to solve a specific problem: how do you keep data sorted on a disk, where reading even a small amount of data requires physically moving a mechanical arm, so you want to minimize how many times you touch the storage medium at all?
Fifty years later, that mechanical constraint barely exists. Modern NVMe drives have no moving parts. RAM is fast enough that many production databases keep their entire working set in memory. Computer science researchers have spent decades designing data structures that outperform B-trees on nearly every benchmark that matters: fractal tree indexes, log-structured merge trees, skip lists, hash array mapped tries. The academic literature on this topic fills libraries.
And yet PostgreSQL uses B-trees. MySQL uses B-trees. SQLite uses B-trees. Oracle, SQL Server, and DB2 use B-trees. The dominance is so complete that when a database chooses something else, it becomes a selling point worth advertising.
The question worth asking is not why nobody invented something better. They did. The question is why the better ideas keep losing.
What B-Trees Are Actually Good At
The honest answer starts with the structure’s genuine strengths, which are easy to understate.
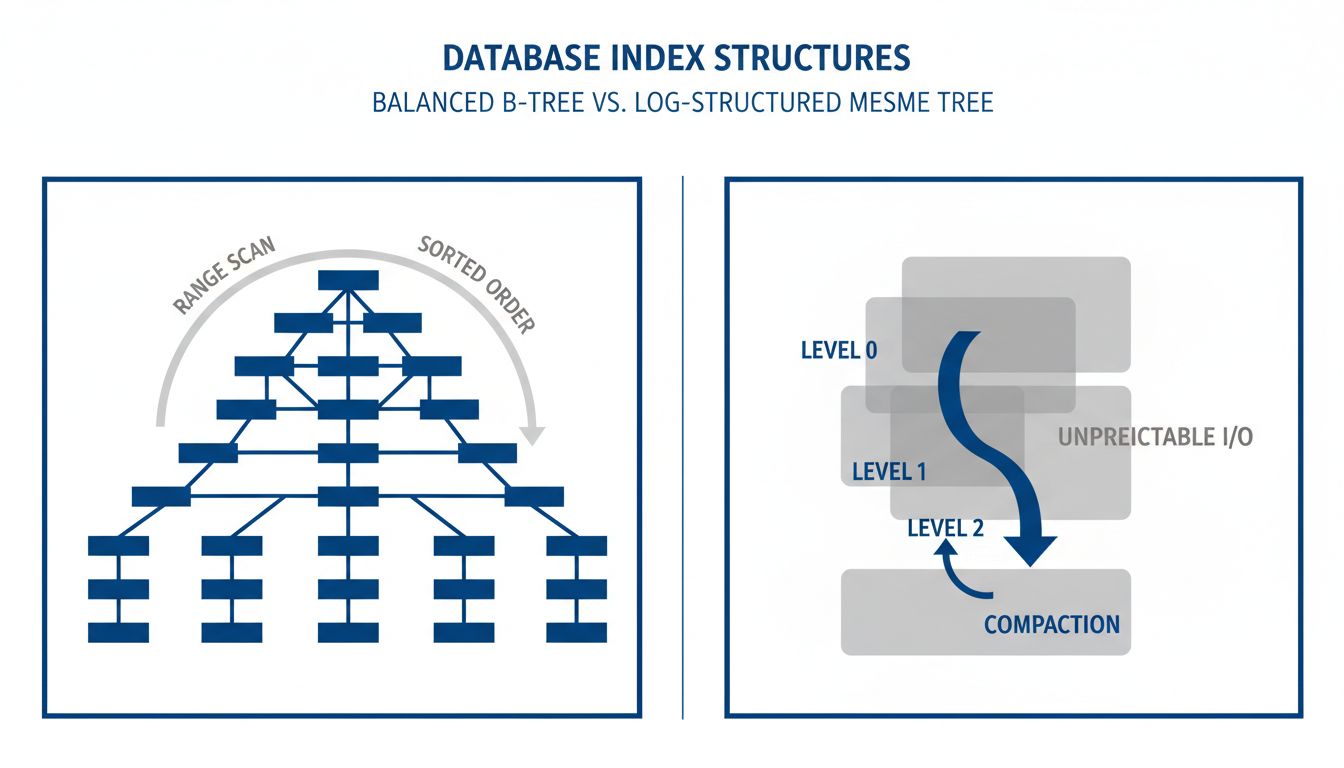
A B-tree keeps data sorted. That sounds simple, but the implications run deep. Sorted order means that a query asking for all customers whose names fall alphabetically between “K” and “M” can be answered with a single traversal of a narrow section of the tree. It means that ORDER BY queries are cheap, that range scans are predictable, and that the database can answer questions nobody anticipated when the index was built.
B-trees also have predictable worst-case performance. A lookup in a B-tree with a billion rows will touch roughly log base 100 of a billion nodes, which works out to about five. The “about” there matters less than it might seem, because the variance is low. Engineers building systems on top of B-trees can reason about what queries will cost. That predictability is worth a great deal in production systems where an unexpected slow query at 2 a.m. creates real problems.
Finally, B-trees support concurrent reads and writes with relatively straightforward locking schemes that have been refined over five decades. The implementation details are well understood. The failure modes are documented. The recovery behavior under a crash is predictable.
Why the Alternatives Keep Struggling
Log-structured merge trees, or LSM trees, offer genuinely better write performance in many workloads. RocksDB, which powers many of Meta’s storage systems, uses them. LevelDB, Cassandra, and InfluxDB use them. The tradeoff is that reads become more expensive and the background compaction process that keeps things organized can consume significant I/O at unpredictable times.
That unpredictability is a recurring theme in why alternative structures struggle in general-purpose databases. A data structure can be faster on average while being worse in the tail cases that production systems care about most. When a B-tree lookup takes 10 milliseconds instead of 5, it is annoying. When an LSM compaction job saturates your I/O bandwidth at peak traffic, it is a production incident. This connects to a broader point about the gap between benchmark performance and real-world application behavior: the number that looks best on paper is rarely the number that matters most in practice.
Hash indexes offer O(1) lookups, which sounds obviously superior to B-tree’s O(log n). But hash indexes cannot answer range queries at all. They cannot help with LIKE queries or ORDER BY clauses. They require the query planner to know in advance that the query will be an exact match. PostgreSQL supports hash indexes but has historically discouraged them, and for most workloads the recommendation remains: use a B-tree.
The deeper problem for alternative structures is the network effect of correctness guarantees. A B-tree implementation that has been running in a production database for thirty years has been exposed to enough edge cases that most of the bugs are gone. A novel data structure, no matter how theoretically elegant, arrives with an unknown set of failure modes. For a component that sits beneath every read and write in a database, unknown failure modes are not acceptable.
The Ecosystem of Code That Surrounds the Index
A data structure does not exist in isolation. It sits inside a database engine that has a query planner, a transaction manager, a crash recovery system, and a buffer pool. All of those components have been built with assumptions about how the index behaves.
Changing the index structure means auditing every one of those assumptions. The query planner’s cost estimates are calibrated for B-tree traversal patterns. The buffer pool eviction policy is tuned for B-tree access patterns. The write-ahead log recovery process makes assumptions about which index operations are atomic.
This is why companies like MySQL and PostgreSQL cannot simply swap in a superior data structure even if one were invented tomorrow. The B-tree is not just stored in one file. Its behavioral contract is distributed across hundreds of thousands of lines of code that have accumulated over decades.
The cost of switching is not the cost of implementing the new structure. It is the cost of re-testing every assumption made about the old one. That cost is genuinely enormous, and for most workloads, the performance difference would not justify it.
The Real Lesson Here
The persistence of B-trees is sometimes presented as an indictment of the database industry, evidence that engineers are too conservative or that legacy systems resist good ideas. That reading is wrong.
What B-trees actually demonstrate is that the qualities that make a data structure successful in a textbook, theoretical performance, elegant design, optimal asymptotic behavior, are a subset of the qualities that make it successful in production. Predictability, correctness under adversarial conditions, deep integration with surrounding systems, and a track record of surviving edge cases all matter more than a better benchmark score.
That is not a counsel of conservatism. Plenty of better ideas have displaced old ones in computing when they offered improvements large enough to justify replacement costs. LSM trees really did displace B-trees in write-heavy workloads where the tradeoffs favor them. Columnar storage replaced row storage for analytics. The question is always whether the improvement is large enough and predictable enough to justify the risk of the transition.
For general-purpose transactional databases, nothing has yet crossed that bar. The B-tree’s real advantage is not that it is fast. It is that it is understood. After fifty years, we have learned where it breaks, how to recover it, and what to expect from it. That knowledge is worth more than most database engineers would initially guess, and it accumulates slowly enough that no competing structure can inherit it overnight.





