The simple version
AI language models can get confused when you give them too much context, not because they ignore the extra information, but because they pay attention to the wrong parts of it. More input doesn’t always mean better output.
Why this feels backwards
Your intuition here is reasonable. When you explain a problem to a colleague, more background usually helps them give you better advice. If you tell your accountant only half the story, you get half an answer. So when AI assistants arrived and we learned that “prompt engineering” was a real skill, most people drew the same conclusion: be thorough, be specific, give it everything it needs.
The problem is that a language model is not processing your context the way a colleague does. A colleague reads your long explanation and distills it. They ask clarifying questions, ignore irrelevant details, and weight the important parts based on experience. A language model reads your long explanation and does something more like pattern-matching across the whole thing, and longer inputs create more surface area for the wrong patterns to match.
The “lost in the middle” problem
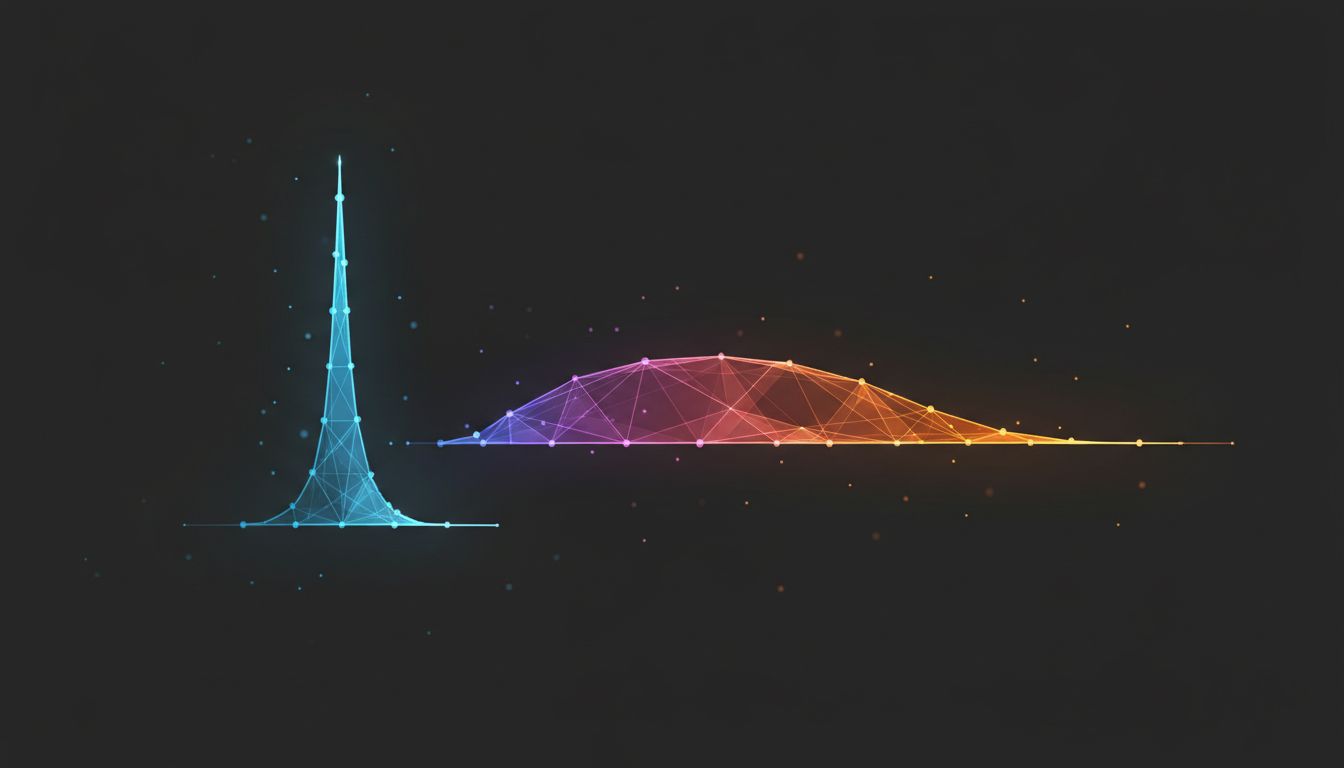
Researchers have documented a specific failure mode called the “lost in the middle” problem. In a 2023 paper from Stanford and other institutions, researchers found that large language models perform significantly worse at retrieving relevant information when that information appears in the middle of a long context window, compared to when it appears at the beginning or end. The models weren’t ignoring the context. They were reading all of it and still getting tripped up by where things appeared in the sequence.
This matters practically. If you paste a 3,000-word document into a prompt and your most important instruction is buried in paragraph four, the model may effectively underweight it, even though it technically “read” the whole thing.
There’s also a related issue with contradiction. Real-world context is messy. If you describe your situation in detail, you’ll often include facts that pull in different directions: your company wants to cut costs but also wants to scale, your users want simplicity but also more features. A human reader understands that these tensions are normal and part of what you’re asking them to help you navigate. A language model may instead anchor on whichever side of a tension is more prominent in your text, or produce an answer that tries to satisfy both and therefore satisfies neither.
When extra context actively misleads the model
Here’s a concrete example. Ask a model: “Write me a short, friendly email declining a meeting.” You’ll probably get something usable. Now add context: “I work at a startup, we’re in a growth phase, the person sending this meeting invite is a vendor we’ve worked with before and generally like, they’ve been persistent about this for three weeks, I don’t want to burn the relationship, we might need them again in Q3, but right now our team is overwhelmed and my manager has asked us to cut external calls by 50%.”
Instead of a better email, you often get a longer, more hedged email that tries to honor every piece of context you provided. The warmth toward the vendor, the door-left-open for Q3, the acknowledgment of their persistence, it all bleeds through. What you wanted was a short, friendly decline. What you got was a diplomatic document.
You loaded the model with your anxiety about the situation, and it reflected that anxiety back at you in the output.
This is worth sitting with if you use AI for writing tasks regularly. What your codebase actually looks like to an LLM explores a similar dynamic in coding contexts, where pasting in large amounts of surrounding code can muddy the model’s focus on the specific problem you’re trying to solve.
What you can actually do about it
The fix isn’t “give less context always.” It’s “give the right context, structured clearly.”
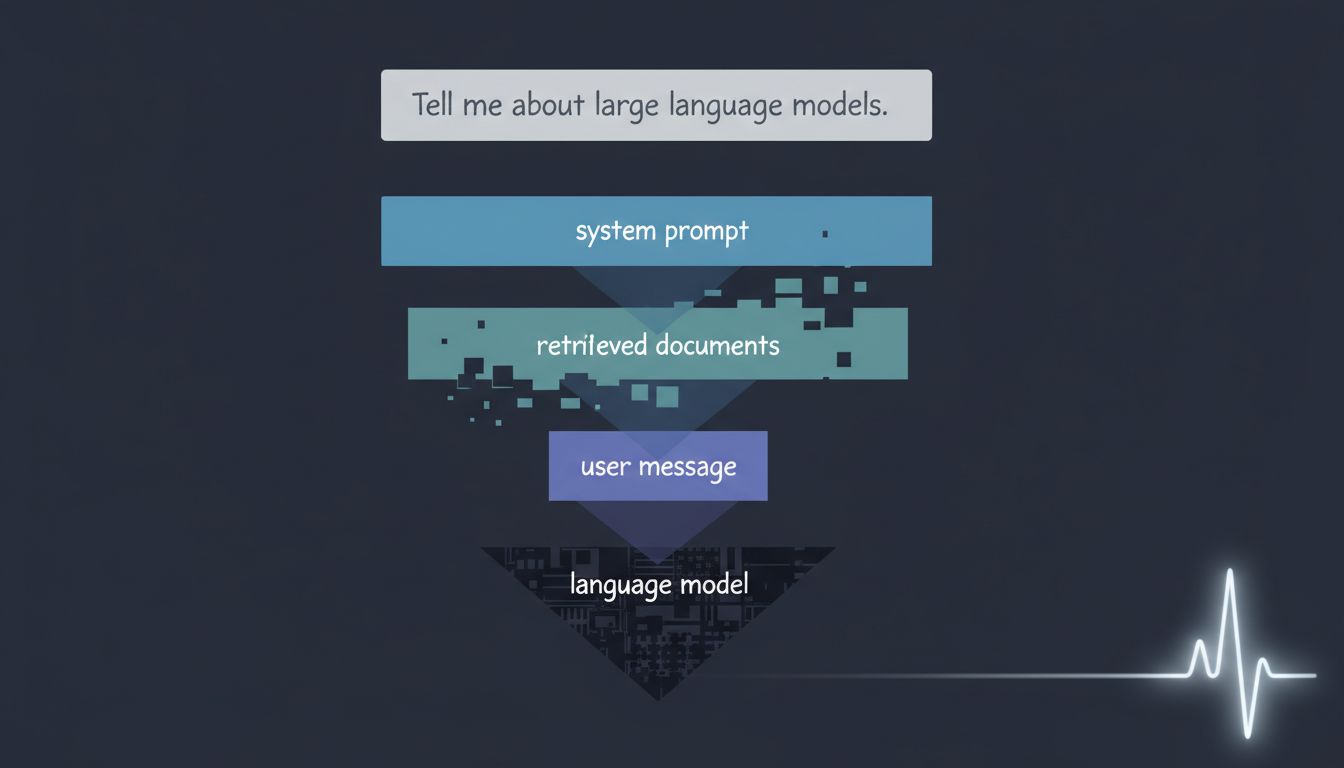
Lead with the output you want. Put your most important instruction first, not last. “Write a two-sentence meeting decline, friendly but firm” should appear before any background, not after it.
Separate context from instructions. Many people blend these together: “Given that I work at a startup and my manager said X and we’re busy and I like this vendor, write me a decline email.” Try splitting them: first state the task clearly, then provide context as a clearly labeled section below. Some prompt structures use explicit labels like “Context:” and “Task:” for exactly this reason.
Cut context that doesn’t change the output. Before adding a detail, ask yourself: would a different answer be correct if I left this out? If no, leave it out. The fact that you like the vendor only matters if you want that warmth reflected in the email. If you want a short, neutral decline, it’s noise.
Use shorter, chained prompts for complex tasks. Instead of one massive prompt, break your task into steps. Get a draft, then ask for revisions with specific feedback. This lets the model focus on one thing at a time, which often produces better results than loading all your requirements upfront. It’s a principle that applies broadly in software too: the fastest programs win by doing less work, and the most useful prompts often do the same.
Test with less. If you’re unhappy with an AI output, try stripping your prompt down before adding more to it. You may find the simpler version works better, which tells you that something in the extra context was the problem, and you can add details back selectively.
The underlying principle
Language models are very good at finding patterns in text and very bad at knowing which patterns you actually care about. Your job when prompting is to make that obvious, not to provide a complete record of your situation and hope the model figures it out.
Think of it less like briefing a consultant and more like writing a good bug report. A good bug report is not everything you know about the system. It’s the minimum information someone needs to reproduce the problem. Trim to that, and you’ll get better answers more consistently.