
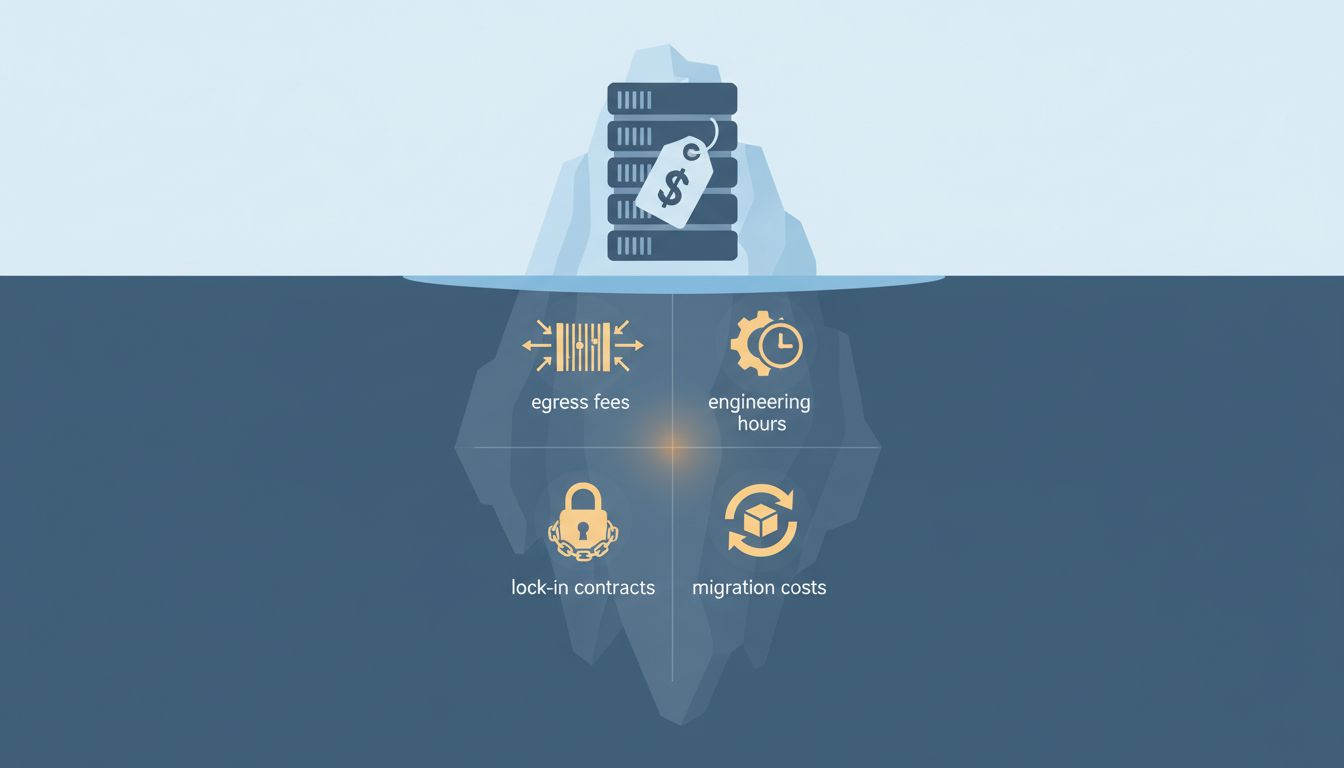
The Simple Version
Cloud providers compete on headline prices, but the real cost of running infrastructure includes a dozen line items that don’t appear until after you’ve built around their platform. Switching later costs more than overpaying now would have.
What You’re Actually Buying
When a cloud provider quotes you a price per compute hour, that number describes one thing: the raw CPU or GPU time. It says nothing about what it costs to move your data out of their network, store it redundantly, query it, transfer it between regions, send it to a third-party monitoring tool, or back it up. Each of those actions has its own pricing tier, and collectively they often exceed the compute cost itself.
This isn’t an accident. As we’ve covered, cloud pricing is designed to be impossible to compare. The deliberate complexity makes it genuinely hard to estimate total cost before you’ve committed to an architecture.
The clearest example is egress fees, the charge for moving data out of a cloud provider’s network. AWS, Google Cloud, and Azure all charge for outbound data transfer, and rates vary by destination, volume tier, and region. A company streaming video, running large model inference, or syncing databases across environments can find that egress alone represents a third of its total bill. The compute price they compared at the start of the decision process is a poor proxy for what they’ll actually pay.
The Lock-In Math
Here’s where the cheapest option becomes most expensive: once you’ve built around a provider’s managed services, migration cost tends to scale with success. A small startup on a cheap object storage tier can switch providers in a weekend. The same company two years later, with proprietary database services, custom networking configurations, and internal tooling built on provider-specific APIs, is looking at months of engineering time and real downtime risk to move.
This is a straightforward economic trap. The low-cost entry point lowers the barrier to commitment. The proprietary services that accumulate on top of cheap compute create switching costs that compound over time. By the time the price difference matters enough to act on, the cost to act has risen to match or exceed it.
Enterprise software buyers have known this dynamic for decades. The database license that seemed affordable in year one becomes non-negotiable by year five because the ERP, the analytics layer, and the reporting infrastructure have all been built on top of it. Cloud infrastructure follows the same pattern at faster velocity.
The Hidden Labor Cost
The most underweighted cost in cloud decisions is engineering time. Cheaper infrastructure options frequently require more configuration, more active management, and more incident response. A managed Kubernetes service costs more per hour than running your own cluster on raw virtual machines. But raw virtual machines require someone to maintain the cluster, handle upgrades, debug networking issues, and respond at 2 a.m. when something breaks.
The math changes entirely when you account for that labor. If a managed service costs an extra $2,000 per month and eliminates 20 hours of engineering work, and your engineers cost more than $100 per hour fully loaded (most do), the managed service is cheaper. This is the same logic behind why the engineer who costs $400K is often the cheapest hire: the visible number and the actual cost point in different directions.
Small teams feel this most acutely. A three-person engineering team that spends 15% of its time on infrastructure management isn’t just paying a cloud bill. It’s paying for half a person’s attention that could have gone toward building product.
Where the Savings Actually Go
Companies that optimize aggressively for cloud cost at the start of a project often end up spending that savings, and more, on three things.
First, re-architecture. Building on the cheapest option sometimes means building on something that doesn’t scale cleanly. Refactoring later, under load, with customers depending on uptime, is expensive in engineering time and risk.
Second, negotiating from weakness. Enterprise cloud contracts are negotiated, not listed. AWS, Google, and Azure all offer committed-use discounts and private pricing. But a company that has already built deep into a provider’s ecosystem has little leverage. The best discounts go to buyers who can credibly threaten to go elsewhere, which requires not having built the switching cost in first.
Third, reliability incidents. Cheaper infrastructure tiers often come with weaker SLAs, less redundancy, and fewer support options. Downtime has a real cost: direct revenue loss in transactional businesses, support overhead, and reputational damage that’s hard to price but real. The cloud option that avoids one significant outage per year may pay for its premium many times over.
How to Think About This Decision
The useful question isn’t “what’s the cheapest cloud option?” It’s “what’s the total cost of this infrastructure choice over a two-to-three year horizon?” That calculation should include compute and storage at expected scale (not current scale), egress costs based on your data flow architecture, engineering hours for setup and ongoing management, the cost of the managed services you’ll inevitably adopt, and a realistic estimate of switching friction.
None of this means the premium option is always right. For genuinely simple workloads with predictable data transfer patterns and teams that have infrastructure expertise, the cheapest compute price can reflect the cheapest real cost. The mistake is assuming that relationship holds by default.
Cloud pricing is structured so that assumption costs you. The providers know that egress fees and proprietary service adoption generate margin that the headline compute price doesn’t. You benefit from knowing it too.





