

The Illusion of a Smarter Model
Something strange happens after you’ve used an AI model for a few months. The outputs get better. The answers feel more relevant. The code it writes actually runs. You start to wonder whether OpenAI or Anthropic quietly pushed an update.
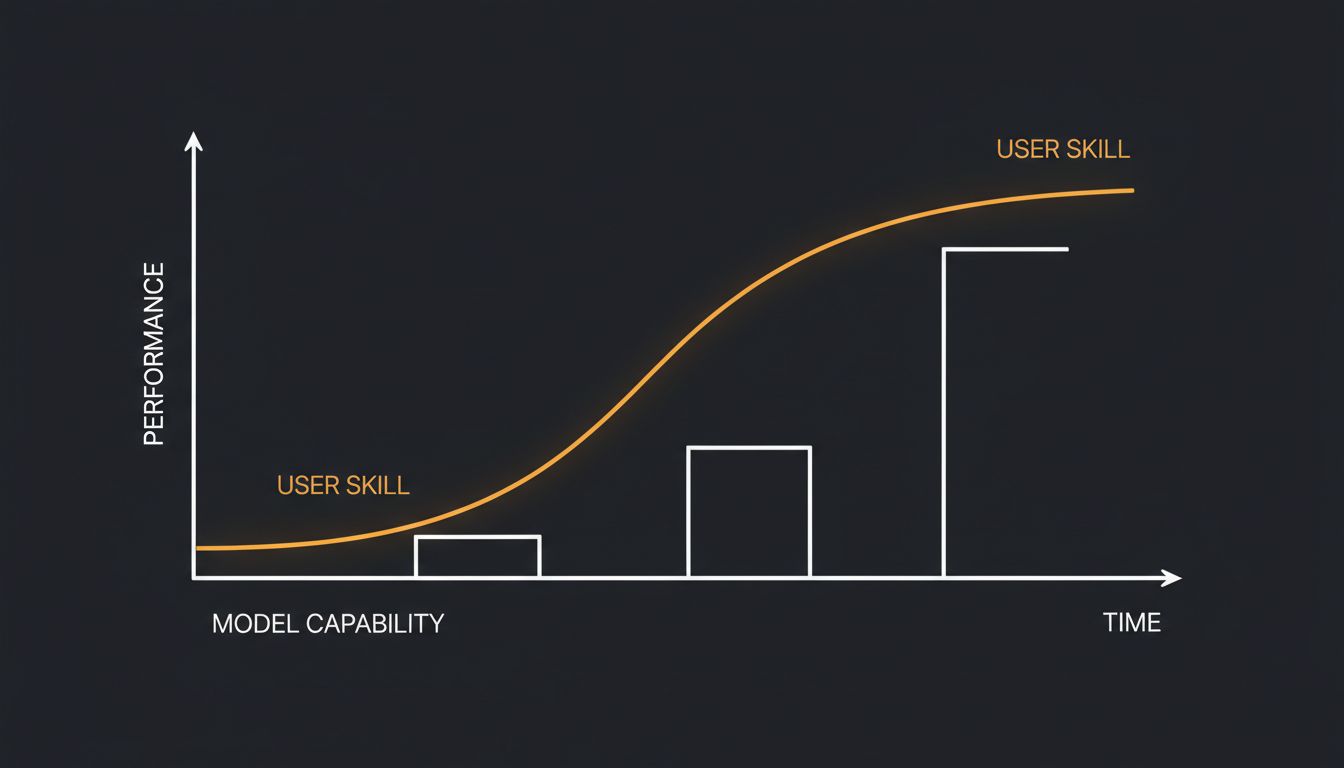
They might have. But usually, they didn’t. What changed is you.
This is one of the more disorienting aspects of working with large language models: the system feels dynamic when the underlying model is largely static. Between major version releases, GPT-4 is GPT-4. Claude 3 Opus is Claude 3 Opus. The weights don’t change based on your satisfaction. The model has no memory of your previous sessions unless you build one explicitly. And yet, your experience of the model improves over time in ways that feel organic and personal.
Understanding why this happens, and what it actually implies for how you work, is more useful than the vague advice to “write better prompts.”
What the Model Actually Responds To
Large language models are, at their core, next-token predictors trained on a distribution of human-generated text. When you send a prompt, you’re not querying a database. You’re providing a context window that shapes what the model considers a probable and appropriate continuation.
This has a concrete implication: the model doesn’t have preferences or goals in any meaningful sense. It responds to the statistical shape of your input. A vague question produces a vague answer not because the model is lazy, but because the training distribution contains many plausible continuations for vague questions, most of them generic.
When you write a more specific prompt, you’re narrowing the probability space. You’re pushing the model toward a region of its training distribution where the likely outputs look more like what you need. The model hasn’t gotten smarter. You’ve gotten better at steering.
This is why role-framing works. Telling the model to respond as a senior software engineer or a skeptical editor doesn’t change its capabilities, but it changes which part of its distribution gets activated. The same factual knowledge is present either way. The framing determines how it’s shaped and expressed.
The Expertise Transfer Problem
Here’s the uncomfortable corollary: to get expert-level output from a language model, you need enough domain expertise to recognize expert-level output and to ask questions that expert outputs are likely to answer.
This is not a bug in the technology. It’s a structural feature of how the models work. The model can’t spontaneously know that you need a latency-optimized SQL query rather than a correct-but-slow one, unless you tell it. It can’t know your codebase’s conventions, your organization’s constraints, or that you’ve already tried the obvious solution. You have to carry that context into the prompt.
Practitioners who get exceptional results from AI tools tend to share a pattern: they already knew a lot about the domain. A senior developer using an AI coding assistant gets compounding returns because they can precisely specify what they want and immediately evaluate what they get. Someone newer to the field gets a more generic output and has less ability to identify where it falls short.
This doesn’t mean AI tools have no value for beginners. It means the value distribution is not what the marketing suggests. The productivity gains aren’t democratizing expertise uniformly. They’re amplifying existing expertise significantly, and providing more modest gains to everyone else. As prompt engineers optimize for the wrong metrics, a lot of organizations are measuring AI adoption rates instead of measuring whether the people using it are getting genuinely better outputs.
The Skill You’re Actually Building
When you get better at prompting, you’re developing several distinct skills that are worth naming separately.
The first is problem decomposition. Experienced model users have learned to break complex requests into smaller, more tractable pieces. Instead of asking for a complete marketing strategy, they ask for an analysis of three specific competitive positioning options, then build from there. This works better not because the model can’t handle complex requests, but because human review at each step catches errors before they compound.
The second is context curation. You’re learning what background information actually changes the output and what’s noise. This is harder than it sounds. Most people initially either over-specify (pasting in enormous amounts of context that dilutes the signal) or under-specify (assuming the model can infer what you’re working toward). Finding the right density of context is a learnable skill, and it transfers across models.
The third is output evaluation. This is the most underrated skill. Knowing when to trust a response, when to push back, and when to discard entirely is where most of the real value comes from. The model will generate plausible-sounding text whether or not it’s accurate. The check is on you. As the prompt you write isn’t the prompt the model reads, there’s a layer of interpretation happening between your input and the model’s processing that makes this evaluation step even more critical.
What Actually Changes Between Model Versions
It’s worth being precise about what does change when a model is genuinely updated, because conflating model improvement with prompting improvement leads to poor decisions.
Instruction following improves significantly across generations. GPT-3.5 would frequently ignore specific constraints or format requirements. GPT-4 follows them much more reliably. Claude’s Constitutional AI training produces models that are more consistent in certain behaviors. These are real capability improvements that exist independent of how you prompt.
Knowledge cutoffs update. A model trained with a later cutoff knows about more recent events. This is a concrete factual change, not a prompting effect.
Context window size increases materially change what’s possible. Moving from 8K to 128K tokens isn’t a prompting trick. You can fit entire codebases or document repositories into a single context. This unlocks workflows that were previously impossible regardless of prompt quality.
But benchmark improvements, while real, are often smaller than announcements suggest. Models get fine-tuned on specific task types, which improves measured performance on those tasks without necessarily improving general capability. A model that scores better on coding benchmarks may not be meaningfully better at the specific coding task your team does every day.
The Organizational Failure Mode
Companies are making expensive strategic errors by not distinguishing between these two sources of improvement.
The pattern looks like this: a team starts using an AI tool and sees mediocre results. Someone on the team, usually through trial and error, figures out how to prompt effectively for their specific domain. Results improve sharply. Leadership attributes this to the tool and expands the rollout without transferring the prompting knowledge. The new users get mediocre results. The company concludes it needs to upgrade to a better model. It pays for the upgrade. Results remain mediocre for most users.
The actual problem was never the model. It was that the domain-specific prompting knowledge sat in one person’s head and never became an organizational asset.
The fix is treating effective prompts as documentation. Capturing what works, why it works, and where it breaks down. Building internal libraries of prompt patterns for recurring workflows. Treating the skill transfer as seriously as any other training investment. This is unglamorous work that doesn’t make for good press releases, which is why most companies skip it.
What This Means
The practical takeaway here isn’t that AI models are overhyped or that prompting is a hidden superpower. It’s more specific than either of those.
First, track the source of improvement. When your outputs get better, ask honestly whether the model changed or you changed. If you changed, identify what you learned and document it.
Second, be skeptical of model upgrade cycles. The jump from one version to the next rarely explains as much of your improvement as the jump from novice to competent prompter. Before paying for a tier upgrade, ask whether you’ve actually saturated what the current model can do in your specific use case.
Third, the expertise prerequisite is real. AI tools work best as a multiplier on existing competence. If you’re trying to use them as a substitute for domain knowledge you don’t have, you won’t be able to evaluate the output reliably, and unreliable output is often worse than no output.
Fourth, the prompting skills you’re building are mostly model-agnostic. Problem decomposition, context curation, and output evaluation transfer across GPT, Claude, Gemini, and whatever comes next. The specific syntax quirks don’t matter nearly as much as the underlying approach.
The model is a tool with a fixed capability profile at any given point in time. You are the variable. Treat that as useful information, not a criticism of the technology.





