Most programmers think of a for loop as a direct instruction to a computer. Write for i in range(1000), and the machine counts to a thousand. That mental model is wrong, and the wrongness is consequential. The distance between the code you write and the operations your CPU performs is not a detail. It is the entire story of modern computing performance.
The Code You Write Is a Polite Suggestion
When you write a for loop in Python, C, or Java, you are not writing machine instructions. You are writing in a language that must be translated, sometimes multiple times, before any hardware acts on it. A C compiler like GCC or Clang will take your loop and convert it to assembly, then to machine code. But before that output reaches silicon, the compiler has already made dozens of decisions you did not make: whether to unroll the loop (executing multiple iterations at once without re-checking the counter), whether to vectorize it (using SIMD instructions to process several data elements in parallel), and whether your loop is doing something so simple that the entire computation can be collapsed into a single pre-computed constant.
GCC’s -O2 optimization flag, which is commonly used in production builds, enables loop unrolling, dead-code elimination, and branch prediction hinting. A loop you think runs 1,000 times may, after optimization, effectively run 250 times with four iterations batched per cycle. The loop counter you agonized over barely makes it to the hardware in the form you imagined.
The CPU Is Running a Different Program Entirely
Assume your loop survives compilation with some structural resemblance to what you wrote. It still hits a processor that has its own agenda. Modern CPUs practice out-of-order execution: rather than processing instructions in the sequence you specified, they analyze a window of upcoming instructions, identify which ones do not depend on each other, and run them simultaneously. Intel has been shipping out-of-order execution cores since the Pentium Pro in 1995. Current architectures can track hundreds of in-flight instructions at once.
There is also branch prediction. Every time your loop checks whether i < 1000, the CPU is making a bet about the answer before it has evaluated it. Modern branch predictors are remarkably accurate, often above 95% on regular loops, but a misprediction costs roughly 15-20 clock cycles as the pipeline flushes and restarts. For a tight loop doing simple arithmetic, that penalty is enormous relative to the actual work. The CPU is not passively executing your code. It is actively gambling on what your code will do next.
Memory Is the Real Bottleneck, Not Computation
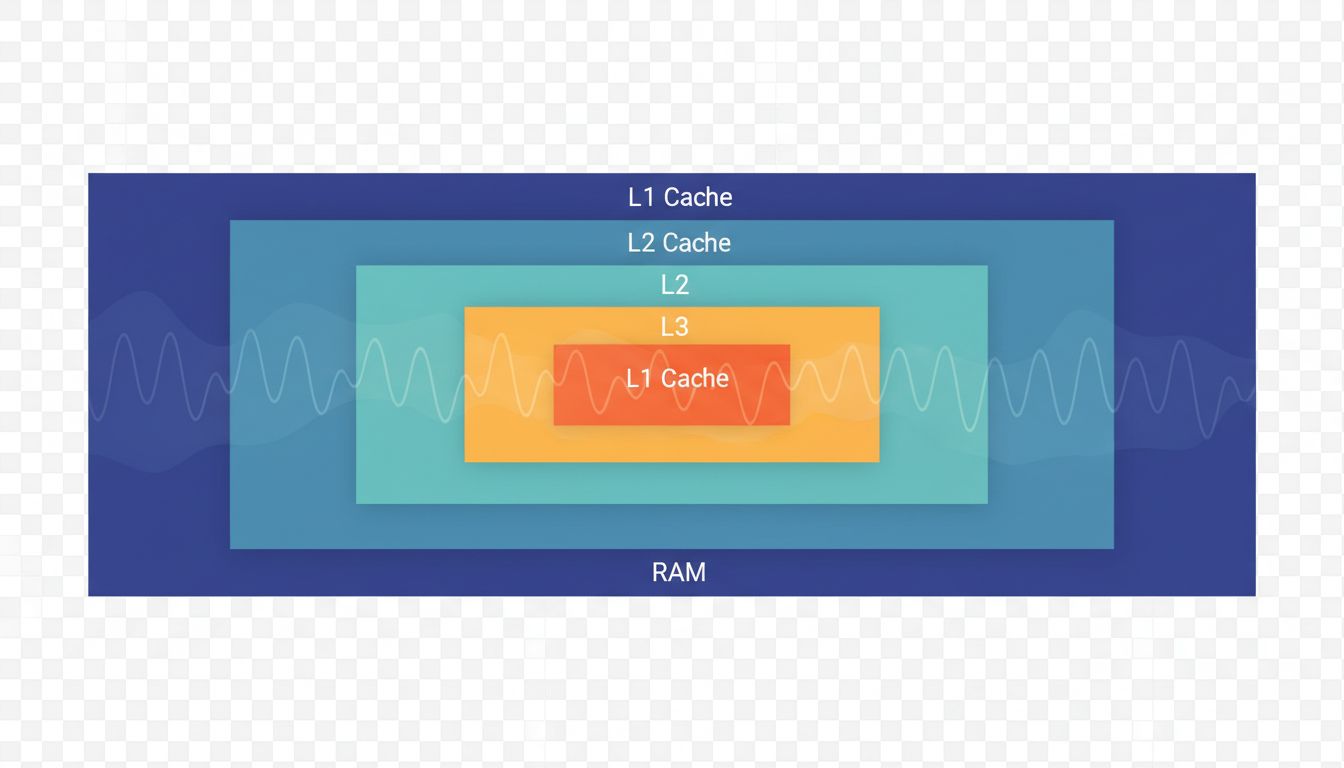
Here is the finding that most programmers do not internalize until they have fought a real performance problem: for most loops, the CPU is not the limiting factor. Memory is. A modern CPU core can perform arithmetic at a rate that far outpaces how fast data can arrive from RAM. The gap is dramatic. An L1 cache hit takes roughly 4 cycles. A main memory access takes 200-300 cycles. If your loop iterates over an array that fits in cache, it runs fast. If it touches memory scattered across RAM, most of those cycles are spent waiting, not computing.
This is why loop order matters in matrix multiplication, why data structure choice affects benchmark results more than algorithmic cleverness sometimes, and why profiling almost never points where programmers expect. The code is not the program. The memory access pattern is the program.
The Counterargument
A reasonable objection goes like this: for application developers, none of this matters. Web servers, business logic, data pipelines, most software is not CPU-bound. You are waiting on databases and network calls, not arithmetic. Understanding CPU internals is trivia for compiler writers.
This objection is partially correct and mostly misleading. It is true that most software bottlenecks are not in for loops. But the argument proves too much. The same reasoning would suggest that understanding memory allocation, garbage collection, or concurrency is irrelevant because most applications are I/O-bound. What actually happens is that developers who understand the machine make systematically better decisions even in cases where the details do not seem to apply. They write better cache-friendly data structures by instinct. They recognize when an O(n) loop with poor locality beats an O(log n) operation with poor locality. They do not reach for premature micro-optimizations, but they also do not write obviously wasteful code because they think the runtime will fix it. The compiler is doing a great deal of work on your behalf, but it cannot fix a fundamentally cache-hostile design.
The Loop Is a Fiction the Whole Stack Agrees On
The honest way to describe a for loop is as a coordination point: a convention that the programmer, the compiler, and the hardware have agreed to interpret in compatible but distinct ways. You write sequential iteration. The compiler produces branching, possibly vectorized machine code. The CPU executes those instructions speculatively, out-of-order, guided by predictors and caches you cannot directly observe.
This is not a flaw. It is an extraordinary feat of abstraction, one that lets programmers reason in simple terms while machines execute with tremendous efficiency. But abstraction has a cost when you mistake it for reality. Believing your for loop is what the CPU runs leads to incorrect performance intuitions, misplaced optimization efforts, and a persistent inability to explain why two nearly identical programs perform completely differently.
The code you write is the beginning of a negotiation. Knowing that negotiation exists is the first step toward writing code that wins it.