

Embeddings started showing up in production stacks as the muscle behind semantic search and chatbot retrieval. That’s the story most engineers heard. But if you look at where they’re actually being used now, the picture is a lot more interesting and a little unsettling, because many teams are depending on them in ways they haven’t fully thought through.
A quick definition for anyone who needs it: an embedding is a vector (a list of floating-point numbers) that represents some input, whether text, an image, a product, a user, or almost anything else, in a high-dimensional space where similar things end up numerically close together. The model that produces embeddings is trained to encode meaning, or more precisely, to encode patterns of co-occurrence and context. Worth noting that what those patterns actually capture is more subtle than most people assume.
1. Semantic Search Is Just the Beginning
Most developers encounter embeddings through retrieval-augmented generation (RAG), where you embed your documents, store those vectors in something like Pinecone or pgvector, and then at query time you embed the user’s question and find the nearest neighbors. That works well, and it’s genuinely useful. But it’s the least surprising use case, which is why it tends to be the only one teams think about.
The more interesting version is when you layer semantic search on top of an existing keyword index. Elasticsearch and OpenSearch both support vector fields now. A query that fails to match on exact keywords can still surface the right document because the embedding space captures that “cardiovascular exercise” and “cardio workout” belong together. Teams that have done this hybrid approach generally report that the keyword layer handles precision (the user knows exactly what they want) while the vector layer handles recall (the user is fuzzy on terminology).
2. Recommendations Without a Ratings Matrix
Classic collaborative filtering, the kind that powers Netflix-style recommendations, requires a dense matrix of user-item interactions. You need many users, many items, and enough overlap to find meaningful neighbors. Cold-start problems (new users, new items) are notoriously hard.
Embeddings sidestep part of this problem. If you embed your items using their content, a new product that was just added has a position in vector space immediately, because its description and attributes place it near similar products. You can recommend it to users whose historical behavior clusters near that region, without a single interaction. Spotify has published extensively on how they embed tracks using audio features and metadata. The approach generalizes broadly: e-commerce, media, job boards, any domain where you have rich item descriptions and sparse interaction data.
3. Duplicate Detection at Scale
This one surprises people. Finding duplicate or near-duplicate content is an old problem, and the traditional solutions involve hashing (exact matches only) or expensive pairwise comparisons. Embeddings give you a middle path.
Embed every piece of content. Group by approximate nearest neighbors using an index like FAISS or HNSW (Hierarchical Navigable Small World, a graph-based structure that makes approximate nearest-neighbor search fast at scale). Items that end up close in the embedding space are candidates for deduplication review. You won’t catch every duplicate and you’ll get some false positives, but you can review tens of thousands of potential pairs instead of millions. Platforms dealing with user-generated content, particularly those fighting spam or scraped articles, have quietly adopted this pattern.
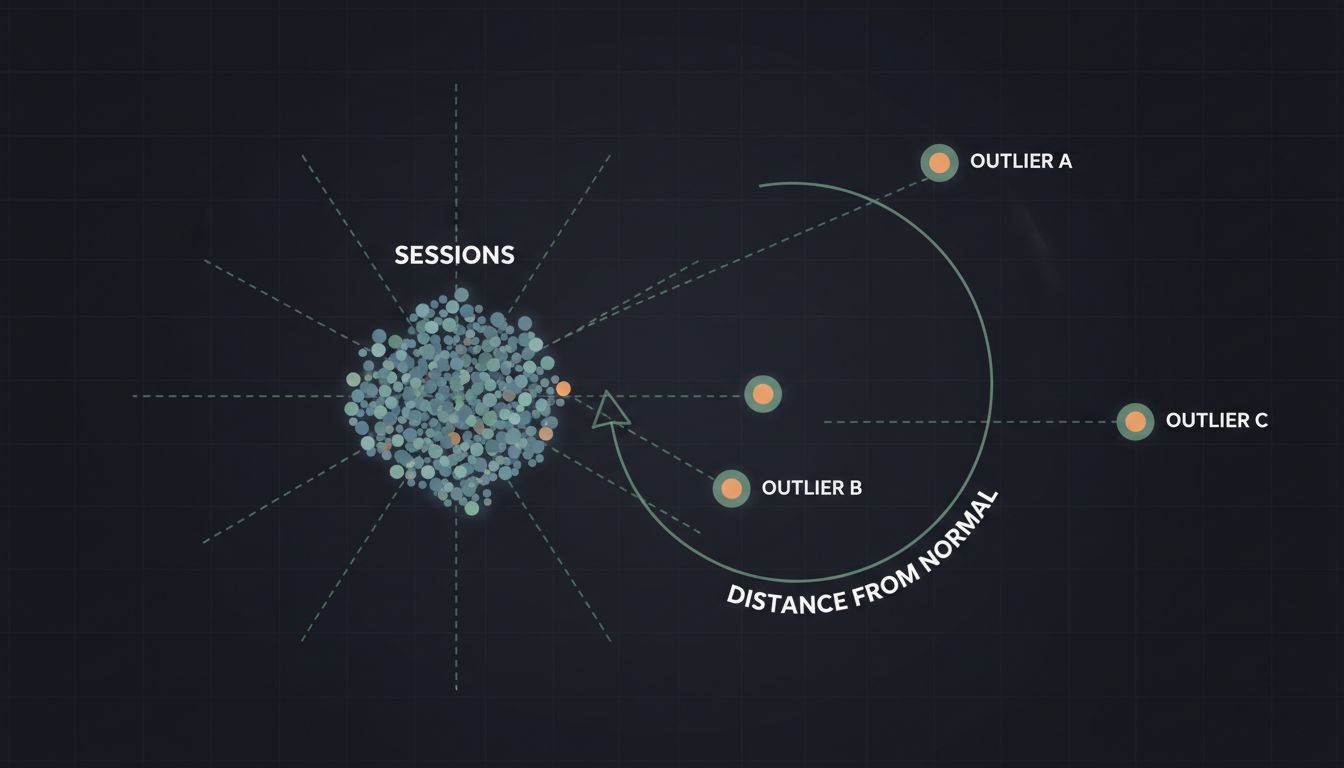
4. Anomaly Detection in Behavioral Data
If you embed sequences of user actions, say a session log of page views, clicks, and transactions, you get a vector that represents “how this user behaved during this session.” Normal sessions cluster together. Anomalous ones, bots, fraud attempts, account takeovers, end up in sparse or isolated regions of the space.
This is not a replacement for dedicated fraud systems with rules and models trained specifically on fraud signals. But as an early-warning layer or as a feature input to a downstream classifier, session embeddings have real utility. The key engineering insight is that you’re not trying to classify behavior in real time from scratch. You’re asking a simpler question: does this session look like any of the sessions I’ve seen before? That’s a distance computation, not a classification, and it can run fast.
5. Caching and Request Deduplication
This one is underused and underappreciated. LLM calls are expensive. If a user asks “what’s your refund policy” and another user asks “how do I return something I bought,” those are semantically the same question and probably deserve the same answer. Exact-match caching misses this entirely.
Semantic caching works by embedding each incoming query, checking whether any stored query vector is within some threshold distance, and returning the cached response if so. GPTCache is an open-source library built specifically for this. The threshold tuning matters a lot: too tight and you get no cache benefit, too loose and you return wrong answers confidently. But for high-traffic applications with repetitive query patterns, a well-tuned semantic cache can reduce LLM costs meaningfully without degrading quality.
6. Cross-Modal Retrieval
Embed text with one model and images with another, but train them in a shared space (the approach behind CLIP from OpenAI, released in 2021), and you can do something genuinely strange and useful: search images with text, or find text that matches an image, without any explicit labels.
This powers reverse image search, visual product discovery, and multimodal RAG where your documents include figures and diagrams. The practical implication for engineering teams is that your vector store doesn’t care what modality your embeddings came from, only that they live in the same dimensional space. If you’re already running a vector index for text, adding image or audio embeddings is an indexing problem, not an architecture overhaul.
7. Your Embedding Model Is Now a Dependency You Need to Version
Here’s the operational problem nobody talks about enough. When you upgrade your embedding model, the new model produces vectors in a different space. Vectors stored under the old model are not directly comparable to vectors produced by the new one. If you swap models without re-embedding your entire corpus, your similarity scores become meaningless, and they’ll fail silently, returning results that look plausible but aren’t.
This is a deployment problem that teams hit the first time they try to improve their embeddings. The fix is to version your embeddings explicitly, keep track of which model produced which vectors, and plan for a re-indexing job whenever you upgrade. For large corpora, that job can be expensive and slow. Treat your embedding model the way you treat a database schema: migration is possible, but it requires discipline and it can’t be done carelessly in production. This is the kind of thing that rarely surfaces until it breaks in a live system.





