
The Simple Version
When you send data over the internet, it gets chopped into small labeled chunks called packets, each one finding its own way to the destination, where they’re reassembled in order. That’s the whole trick.
Why the Pipe Mental Model Is Wrong
Most people imagine internet data like a phone call: a dedicated wire connects two points, and your information flows through it continuously until you hang up. This made sense for telephone networks, which literally worked that way. The internet was designed to work nothing like that.
The architects behind TCP/IP (transmission control protocol and internet protocol, formalized in a 1974 paper by Vint Cerf and Bob Kahn) were partly trying to solve a resilience problem. A dedicated-connection network is fragile: cut one wire, and conversations on that wire die. The packet-switching approach they borrowed and refined meant that no single physical path was sacred. Destroy half the network, and data reroutes around the damage.
This is not a metaphor. It is literally how traffic behaves.
What Actually Happens When You Load a Webpage
Say you type a URL and press Enter. Your browser wants the HTML file sitting on a server somewhere. Here’s what that actually looks like at the network layer.
First, IP handles addressing. Every device on the internet has an IP address, a numerical label that works like a postal address. Your request needs to find the right server, and the server’s response needs to find its way back to you.
Second, TCP handles reliability. Before any real data moves, your computer and the server perform a handshake: your machine sends a SYN packet (“I want to connect”), the server replies with SYN-ACK (“acknowledged, go ahead”), your machine replies with ACK (“starting now”). This three-way handshake establishes a session. It takes time, which is part of why the first request to a new server feels slightly slower than subsequent ones.
Now your browser sends its HTTP request, which TCP breaks into packets. Each packet gets a sequence number, a source address, a destination address, and a checksum to verify it wasn’t corrupted in transit. The maximum size of a packet on most networks is around 1,500 bytes, which is why a large file becomes thousands of separate packets.
Here’s the part that surprises most people: those packets don’t travel together. They fan out across the network and may take completely different physical routes. Packet 47 might go through a router in Chicago. Packet 48 might bounce through Dallas. This is normal. Routers along the way make independent decisions about where to forward each packet based on their current view of network conditions.
When packets arrive at the destination, they arrive out of order, and TCP’s job is to put them back in sequence using those sequence numbers. Missing packets get requested again. The receiver sends acknowledgments (ACKs) as packets arrive, and if the sender doesn’t get an ACK within a timeout window, it retransmits.
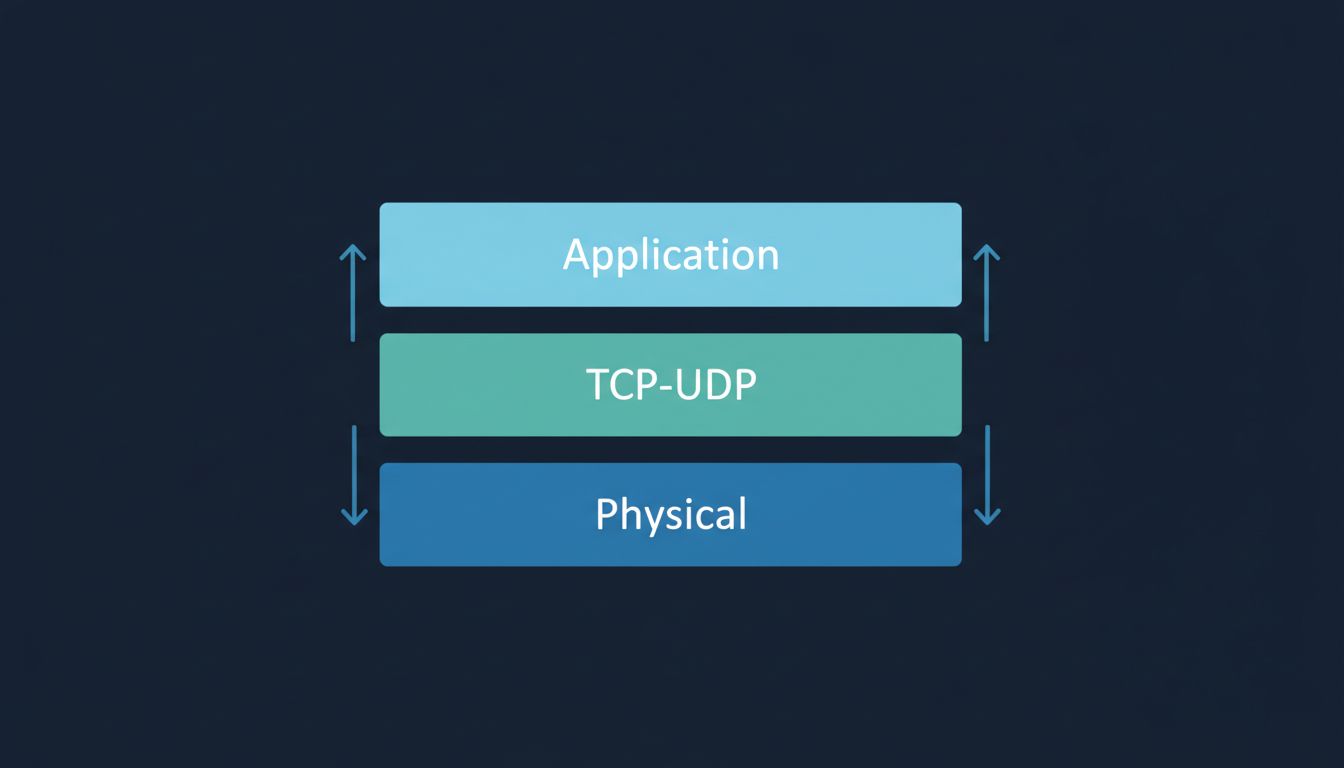
The Layered Model and Why It Matters
TCP/IP is built in layers, and this layering is what makes the internet composable. The physical layer moves bits over wires or radio. The IP layer handles addressing and routing. TCP (or UDP, more on that shortly) handles the session and reliability. Above that sit application protocols like HTTP, SMTP, or DNS.
Each layer only talks to the layers immediately above and below it. This is why you can load a website over fiber, 5G, or a satellite link without the website caring which one you’re using. The physical transport changes; everything above it stays the same. It’s a clean abstraction, and it’s the reason the internet has been able to absorb decades of hardware change without being redesigned from scratch. If you’re curious about how similar layered thinking applies at the CPU level, what actually happens inside a CPU when you run a for loop is worth reading.
The TCP/IP stack also illustrates why networking bugs are hard to diagnose. A problem at the physical layer looks, from the application’s perspective, like data that never arrived. The application has no visibility into why.
TCP vs UDP: When “Good Enough” Is Better
TCP’s reliability comes at a cost. All those acknowledgments, retransmissions, and sequencing checks add latency. For a webpage, you want every byte correct, so this tradeoff is fine. For a live video call, it is not.
If a packet carrying video frame 47 is lost and has to be retransmitted, by the time it arrives the conversation has moved on. Showing a stale frame is worse than just skipping it. This is why video calls, live streams, and multiplayer games typically use UDP (user datagram protocol) instead of TCP.
UDP is deliberately minimal. It sends packets and doesn’t track whether they arrive. No handshake, no acknowledgment, no retransmission. The application layer handles whatever error correction it needs, usually none. You get lower latency in exchange for accepting some data loss, and for real-time audio and video, that’s the right trade.
Quic, the protocol underlying HTTP/3 (now supported by most major browsers and a large share of web traffic), takes a different approach: it reimplements many of TCP’s reliability features on top of UDP, with better handling of packet loss and faster connection setup. It’s TCP’s goals with a cleaner implementation, running on UDP’s transport.
The Part That Should Actually Impress You
What makes TCP/IP genuinely remarkable isn’t any single mechanism. It’s that a protocol designed in the early 1970s for a network with a few hundred nodes now moves data between billions of devices with no central coordination. No single router knows the whole network topology. Each one only knows its neighbors and makes local decisions. The routing protocols (BGP at the internet backbone level, others internally) gossip network state between routers, so the whole system converges on good paths without anyone being in charge.
The failure tolerance that Cerf and Kahn designed for turns out to be exactly what you need when the network grows by orders of magnitude and spans the entire planet. That’s not luck. It’s a consequence of the design decision to make each node autonomous and to put reliability in the endpoints rather than in the network itself.
When your video call glitches for a second and then snaps back, you’re seeing the system do what it was built to do. The packets rerouted. The buffer compensated. The connection recovered without you touching anything. That’s the protocol working.





