

Most developers interact with compilers the way most people interact with electrical grids: they flip the switch and trust the lights come on. That’s fine until something goes wrong, or until you need to squeeze real performance out of a system. Understanding what actually happens between gcc main.c and a running process changes how you write code, how you read error messages, and how you reason about bugs that appear only in production.
1. Lexing Turns Characters Into Tokens
The compiler’s first job is almost mechanical: read the raw text of your source file and break it into meaningful chunks. This stage is called lexical analysis, and the output is a stream of tokens. The identifier count, the operator ++, the semicolon after it. Each is a discrete unit with a type and a value.
This is why compiler errors often mention line and column numbers. The lexer is tracking position as it scans. It’s also where keywords get distinguished from identifiers. In C, int is a keyword; integer is not. The lexer knows the difference because it carries a lookup table. Nothing clever is happening yet, just categorization.
2. Parsing Builds a Tree From the Token Stream
A list of tokens is still ambiguous. Parsing imposes grammatical structure by building an Abstract Syntax Tree (AST). The expression a + b * c produces a tree where * sits deeper than +, encoding operator precedence without any special-case logic. The grammar rules of the language define the tree shape; the parser enforces them.
This is also where most syntax errors surface. If the token stream can’t be arranged into a valid tree according to the language grammar, parsing fails. The error message “unexpected token” almost always means the parser expected a different token at a particular position in the grammar. Experienced developers read these messages against the grammar, not against their intuition about what looks right.
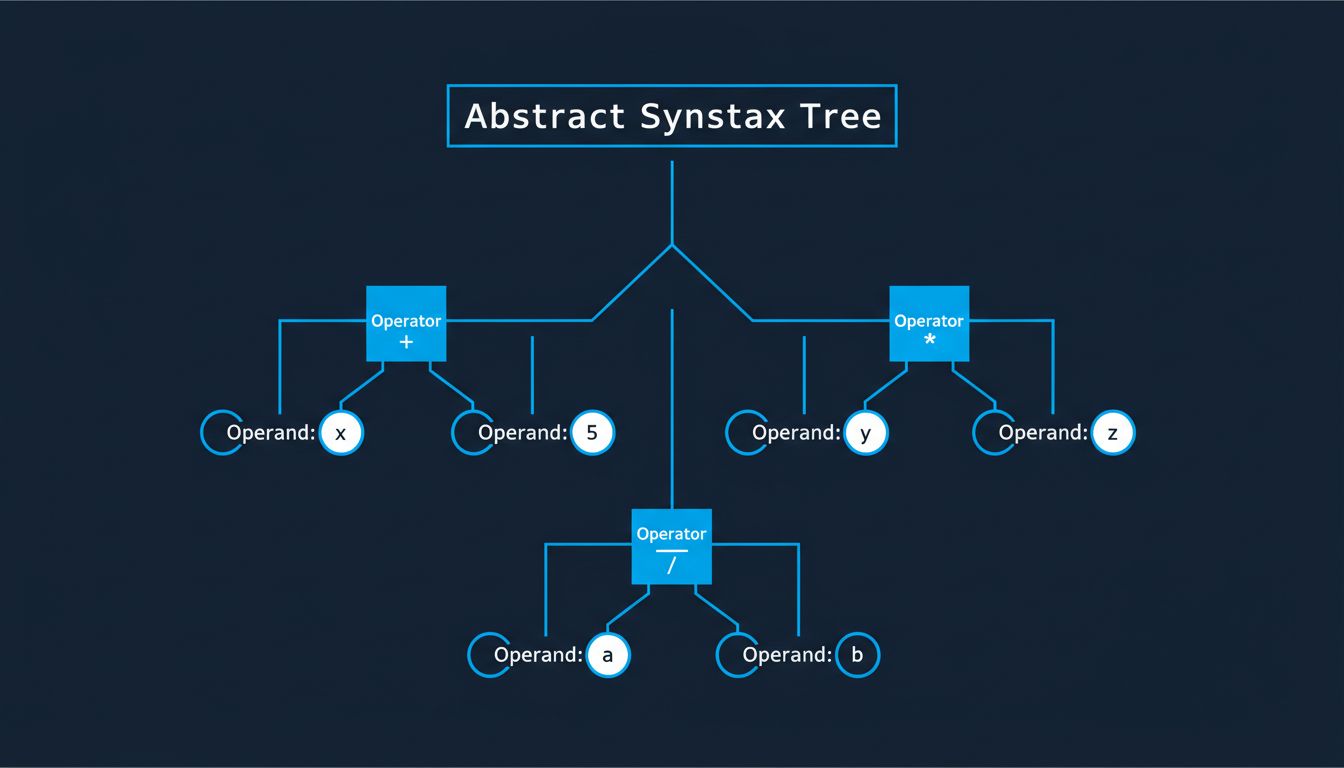
3. Semantic Analysis Catches What Syntax Can’t
A program can be grammatically valid and still nonsensical. Semantic analysis is where the compiler checks meaning. Type checking lives here: assigning a string to an integer variable produces a valid AST but fails semantic validation. So does calling a function with the wrong number of arguments, or referencing a variable before it’s declared in languages that prohibit it.
Strongly-typed languages front-load enormous amounts of error detection into this phase. The Rust compiler’s famous borrow checker is a semantic analysis pass. It doesn’t examine syntax; it examines the relationships between values and the lifetimes of references, enforcing memory-safety rules that would otherwise only surface as crashes at runtime. What feels like pedantry when you’re fighting the borrow checker is the compiler doing work that would otherwise fall to you, or to your users.
4. Intermediate Representation Decouples Language From Machine
After semantic analysis, most modern compilers translate the AST into an Intermediate Representation (IR), a lower-level, abstract instruction format that isn’t tied to any specific hardware. LLVM’s IR is the canonical example. Clang, Rust’s rustc, and Swift’s compiler all emit LLVM IR, which means they all share the same backend optimization machinery.
This decoupling is the architectural insight that made LLVM so influential. Language designers no longer need to build their own optimizer and code generator for every target architecture. They write a frontend that produces LLVM IR, and the backend handles the rest. The IR is also where many optimizations are easiest to apply, because it’s low-level enough to reason about operations but still architecture-neutral.
5. Optimization Rewrites Your Code in Ways That Would Disturb You
This is the phase most developers underestimate. A modern optimizing compiler doesn’t just translate your code, it aggressively transforms it. Dead code elimination removes branches that can never execute. Inlining replaces function calls with the function body, eliminating call overhead. Loop unrolling rewrites a loop that iterates four times into four sequential operations, eliminating branch prediction costs. Constant folding replaces 2 * 3 with 6 at compile time.
The cumulative effect is that the machine code the CPU actually executes can be structurally unrecognizable compared to the source you wrote. This is why debugging optimized builds is hard. The variable you want to inspect may no longer exist as a discrete value in memory. The function call you’re trying to trace may have been inlined away. When you compile with -O0 to disable optimization, you’re asking the compiler to produce slower code specifically so that the correspondence between source and binary stays intact. This connects to a broader truth about how CPUs execute code: what actually happens inside the CPU when that optimized loop runs depends heavily on what the compiler handed off.
6. Code Generation Produces Architecture-Specific Instructions
The final phase takes the optimized IR and emits actual machine instructions for a target architecture. This is where x86-64 and ARM64 diverge. The code generator knows the register count, the instruction set, the calling conventions, and the memory alignment requirements of the target platform. It makes decisions about register allocation (which values live in CPU registers versus memory) and instruction selection (which specific opcodes accomplish each operation most efficiently).
The output is an object file, not yet an executable. Object files contain machine code and a symbol table, a list of functions and variables the code defines or needs from elsewhere. The linker takes multiple object files, resolves the cross-references between them, and produces the final binary. When a build fails at link time with “undefined reference,” it means the linker couldn’t find a symbol that some object file expected to exist. The compiler accepted the code; the linker found the gap.
Understanding the full pipeline reframes how you think about performance, error messages, and the gap between code as written and code as executed. The compiler is not a faithful translator. It’s an aggressive editor that happens to share your goal of correct output.





