

Null is not zero. It is not an empty string. It is not false. It means unknown, and the failure to take that distinction seriously corrupts databases, distorts analysis, and produces business decisions built on phantom numbers.
This is not a theoretical concern. It is one of the oldest and most persistently misunderstood features of relational databases, and it keeps causing real harm because most developers encounter it during a tutorial, nod along, and then promptly handle it the same way they would handle zero.
The math breaks immediately
SQL uses three-valued logic: true, false, and null. Any comparison with null returns null, not true or false. SELECT 1 WHERE NULL = NULL returns no rows. SELECT 1 WHERE NULL != NULL also returns no rows. The intuition most people bring to databases, that unknown equals unknown, is wrong by design.
This creates immediate arithmetic problems. Sum a column with null values and the nulls are silently ignored. Average that column and the denominator shrinks without warning. A sales report that sums revenue across ten regions will produce a smaller number if three regions haven’t reported yet, with no flag, no error, and no asterisk. The analyst reads the output and reports it as fact.
The trap is that SQL’s SUM() and AVG() do not crash on null. They continue. Silence is the whole problem. If a function threw an error on null input, teams would be forced to handle it. Instead, the calculation completes and looks correct.
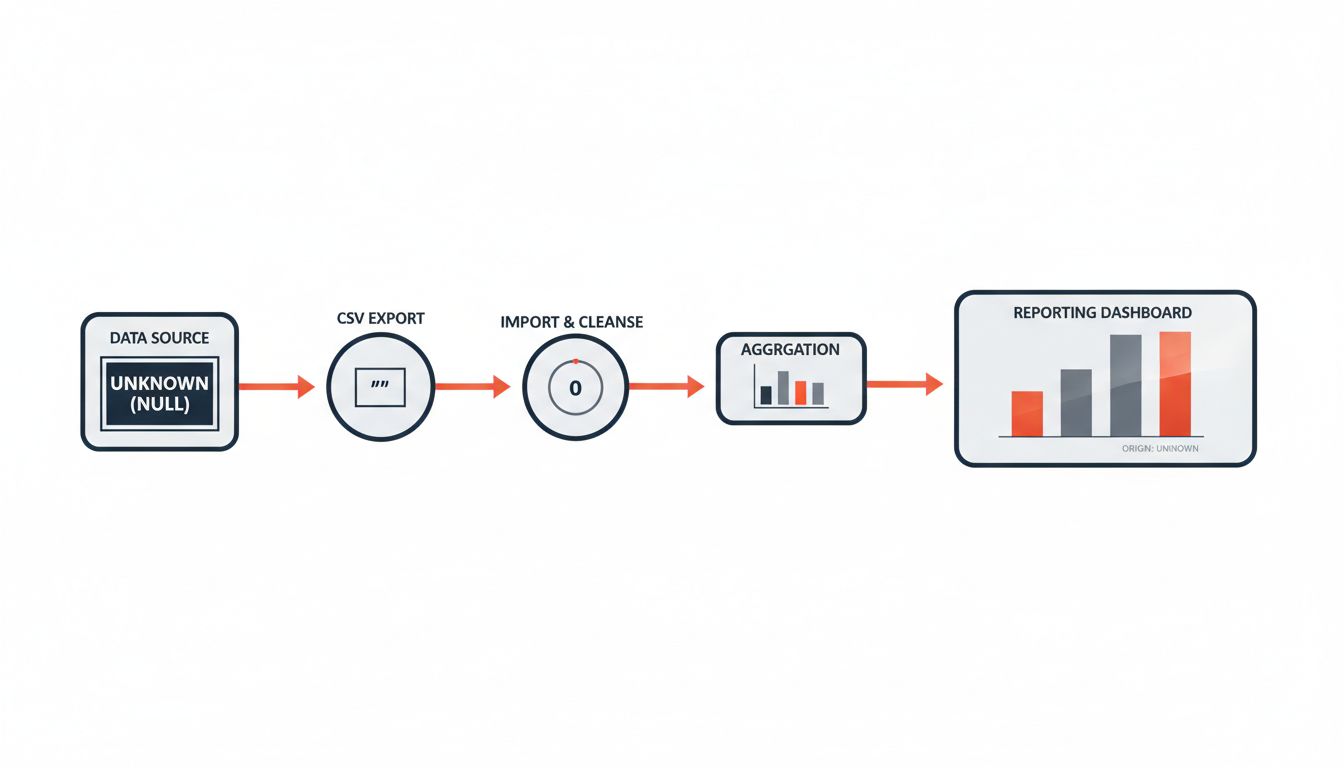
Application code compounds the problem
Most languages map SQL null to a language-level null, nil, or None, and most developers then write conditional logic that checks for null the same way they check for zero or empty. The result is code paths that treat a missing salary as a zero salary, a missing date as epoch, or a missing user preference as a default preference.
The danger compounds when data moves between systems. A null value exported to a CSV often becomes an empty string. Imported into a second database, that empty string becomes a zero in a numeric column or a literal string “null” in a text column. The original meaning, that the value was unknown, is gone. The data now claims certainty it never had.
This is why the problem in preprocessing and the problem in raw storage are related. As we’ve covered before, the choices made about ambiguous values early in a pipeline tend to propagate invisibly into every downstream model and report.
The business cost is real and measurable
Consider customer lifetime value calculations. If a customer’s last purchase date is null because the record was migrated from a legacy system that didn’t capture dates, and your code treats null as today, that customer looks like a recent buyer. They stay in your retention campaigns. Marketing spends money on them. Churn predictions undercount actual churn.
Credit risk models have the same exposure. A null income field means income is unknown. Treated as zero, the borrower looks poor. Treated as the column average (a common imputation shortcut), the borrower looks median. Neither is the truth. Both produce risk scores that differ from what the data actually supports.
Financial reporting carries the highest stakes. Accounting systems that aggregate across subsidiaries, currencies, or time periods frequently encounter nulls where records are incomplete. A null entry that gets treated as zero in a P&L roll-up understates the actual uncertainty in that line item. Auditors and regulators are not interested in explanations about how null propagation works.
The counterargument
The standard pushback is that this is a developer education problem, not a design problem. Teach your engineers about three-valued logic, add NOT NULL constraints where values are required, enforce data contracts at the schema level, and the issue goes away.
This is partly correct. Schema discipline genuinely helps. Marking a column NOT NULL forces the application to provide a value, which eliminates a large class of accidental nulls.
But it does not eliminate intentional nulls, which are often the legitimate ones. A patient’s discharge date is null because they haven’t been discharged. A job application’s decision date is null because no decision has been made. These nulls carry real meaning: the event has not yet occurred. Treating them as zero, or coercing them out of existence with a default, destroys that information.
The deeper problem is that “unknown” is a valid state in almost every real-world domain, and relational databases surfaced that truth decades ago when they introduced null. The response from practitioners has largely been to work around it rather than reason through it.
Stop treating null as inconvenient
Null is not a bug in your data. It is data. It represents the honest acknowledgment that a value either was not collected, does not yet exist, or cannot be known. That acknowledgment has consequences for every aggregation, every join, and every report built on top of it.
The fix is not complicated. Audit your schema for columns that contain nulls and decide, column by column, what null means in that context. Document it. Write tests that explicitly verify null behavior in aggregations. When nulls cross a system boundary, make the conversion explicit, not implicit.
The engineers who understand this are not doing anything exotic. They are just taking seriously what the database has been trying to tell them since 1970.





