

TCP doesn’t know when your internet connection dies. It infers. And the difference between those two things explains why your video call freezes for 30 seconds before giving up, why your SSH session hangs on a flaky hotel Wi-Fi, and why a dropped connection often feels so much worse than it should.
This is not a bug. It’s a deliberate design choice from the 1980s that we’ve inherited, patched around, and mostly stopped questioning. We should start questioning it again.
The Inference Machine
TCP is a reliability layer built on top of IP, which is fundamentally unreliable. As covered in TCP/IP Delivers Your Message by Throwing Most of It Away, the base protocol makes no delivery guarantees. TCP’s job is to paper over that chaos with acknowledgments, sequence numbers, and retransmission logic.
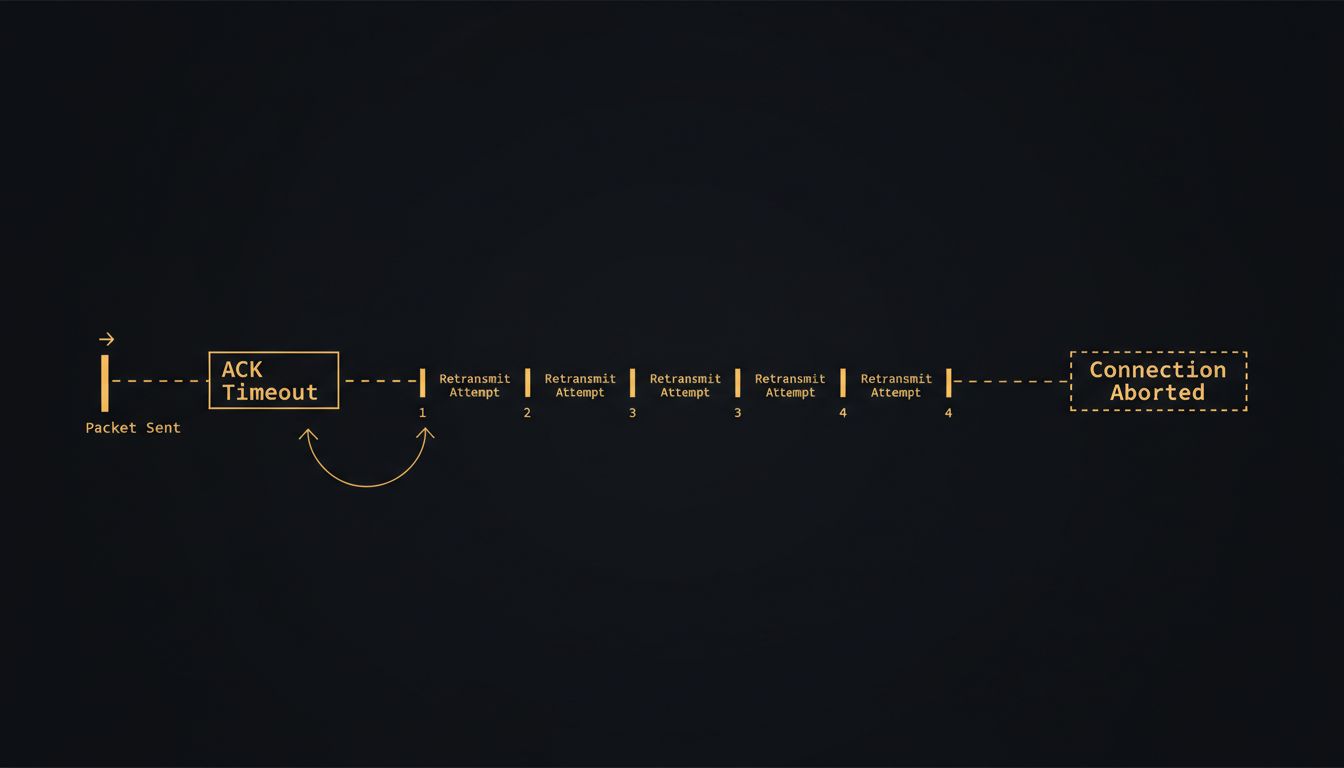
The mechanism for detecting failure is a timer. When TCP sends a segment, it starts a retransmission timeout clock. If an acknowledgment doesn’t arrive before the clock expires, TCP assumes the packet was lost and resends it. The initial timeout is calculated using an algorithm called RTT estimation, which tracks recent round-trip times and adds a variance buffer. On a stable connection, this works elegantly. The timeout calibrates itself to network conditions.
But “lost packet” and “dead connection” look identical from TCP’s perspective. Both produce the same symptom: silence. TCP’s response to silence is to wait, retransmit, double the timeout interval (exponential backoff), wait again, retransmit again, and keep doing this until it hits a ceiling defined by a parameter called tcp_retries2. On Linux, that parameter defaults to 15. Run through the math with exponential backoff and you’re looking at roughly 15 to 20 minutes before TCP officially gives up on a completely dead connection.
That’s not a typo. Your operating system will spend up to 20 minutes politely retrying a connection that terminated instantly when you closed your laptop.
Why the Timer Was Reasonable in 1981
The original TCP specification (RFC 793, published in 1981) was designed for a world where “lost packet” almost always meant transient congestion, not a severed link. The early ARPANET was a small, expensive, carefully managed network. Connections were rare and valuable. Waiting and retrying made sense because the alternative, assuming failure and tearing down a connection, was costly to recover from.
The exponential backoff wasn’t naive. It was the right call for a network where packet loss was a signal about congestion, not about topology failures. Aggressive retransmission into a congested network makes congestion worse. Backing off gives the network room to recover.
The problem is that consumer networks in 2024 fail in ways ARPANET never did. You walk from your living room to your backyard and your phone changes access points. You board a train. You drive through a tunnel. These are hard, instantaneous link failures, not congestion events. TCP’s timer, calibrated for the former, handles the latter badly.
The Patches We’ve Applied
The networking community knows this. The response has been a series of workarounds that sit above and beside TCP rather than modifying its core behavior.
TCP Keepalives are the most common fix. They send periodic probe packets on idle connections to check whether the other end is still alive. But keepalives are disabled by default in most operating systems, and when enabled, the defaults are comically slow: Linux sends the first probe after two hours of inactivity. Application-layer keepalives (like the ping frames in WebSockets, or the heartbeat in QUIC) are often faster and more reliable, which is why they’ve become standard practice for any application that cares about responsiveness.
QUIC, the protocol underlying HTTP/3, takes a more aggressive position. It handles connection migration natively, meaning a QUIC connection can survive an IP address change. Your connection migrates with you as you move between networks rather than dying and requiring a full TCP handshake to restart. Google has been running QUIC in production for years, and their internal data showed meaningful latency improvements, particularly in degraded network conditions.
But QUIC doesn’t eliminate the timeout problem for the vast installed base of TCP connections. It sidesteps it.
The Counterargument
The standard defense of TCP’s conservative timeout behavior is that it’s right more often than it’s wrong. Most packet loss, even on modern networks, is transient. A router buffer overflows. A wireless access point momentarily saturates. The packet is lost, but the connection is fine. Waiting and retrying is correct in those cases, and triggering the wrong behavior (killing a live connection because you mistook congestion for failure) has real costs.
This argument has merit. The danger of being more aggressive about failure detection is false positives: declaring a connection dead during a temporary outage that would have self-resolved. In real-time systems that’s often worse than the hang.
But accepting this defense means accepting that the design is optimized for a network topology that increasingly doesn’t exist for most users. The tradeoff made sense when the hard problem was congestion on expensive long-haul links. Today the hard problem is often the last hundred feet: the flaky Wi-Fi, the cellular handoff, the home router that needs rebooting. TCP’s patience, in those conditions, isn’t a feature. It’s a mismatch.
What Good Failure Detection Looks Like
The honest answer is that failure detection should be a signal, not a timeout. Link-layer information (knowing that the Wi-Fi connection dropped) should propagate up the stack and let TCP tear down connections immediately rather than waiting for timers to expire. Modern operating systems support this to varying degrees. Linux has had socket options like TCP_USER_TIMEOUT for over a decade that let applications set more aggressive failure thresholds.
The fact that these options exist is not enough. They require applications to opt in, developers to know they exist, and sane defaults that most people never change. The networking stack is one of those places where finishing a task and closing it are not the same thing: the protocol delivers your data, but the connection state lingers far past its usefulness.
TCP’s timeout logic is a reasonable answer to a question the modern internet rarely asks. Until the default behavior catches up with how networks actually fail, users will keep staring at spinners while their operating system waits, patiently and pointlessly, for a packet that isn’t coming.





