

The Number Is Real, But the Mental Model Isn’t
When Anthropic announced Claude’s 100,000-token context window, the demos were striking. Feed in an entire codebase. Dump in a novel. Ask questions across the whole thing. The implication was that the model could hold all of it in mind simultaneously, like a reader who never forgets a page.
That mental model is wrong in ways that matter practically.
A transformer-based LLM doesn’t “read” a context window the way you read a document. It processes every token in relation to every other token, computing attention weights across the entire sequence. This is powerful, but it’s also the source of real limitations that a big context number doesn’t fix. Understanding those limitations changes how you should use these systems.
What Attention Actually Computes
The attention mechanism at the core of transformers was formalized in the 2017 paper “Attention Is All You Need” by Vaswani et al. The core operation, self-attention, computes a relationship between every token in the sequence and every other token. For a sequence of length N, that’s N² operations.
At 1,000 tokens, this is manageable. At 100,000 tokens, you’re computing 10 billion pairwise relationships per attention layer, and modern transformers have dozens of layers. The memory requirements scale quadratically as well, which is why long-context inference is expensive enough that providers typically charge more for it.
This quadratic scaling is the reason context windows didn’t just steadily increase from the beginning. Getting from GPT-3’s 4,096 tokens to 100,000-plus required genuine engineering work: techniques like sparse attention, sliding window attention, and positional encoding improvements (Google’s ALiBi and RoPE, for instance) that let models generalize to longer sequences than they saw during training.
The point isn’t that 100,000-token contexts are a trick. They’re real. But the underlying cost structure means the model isn’t treating all those tokens equally.
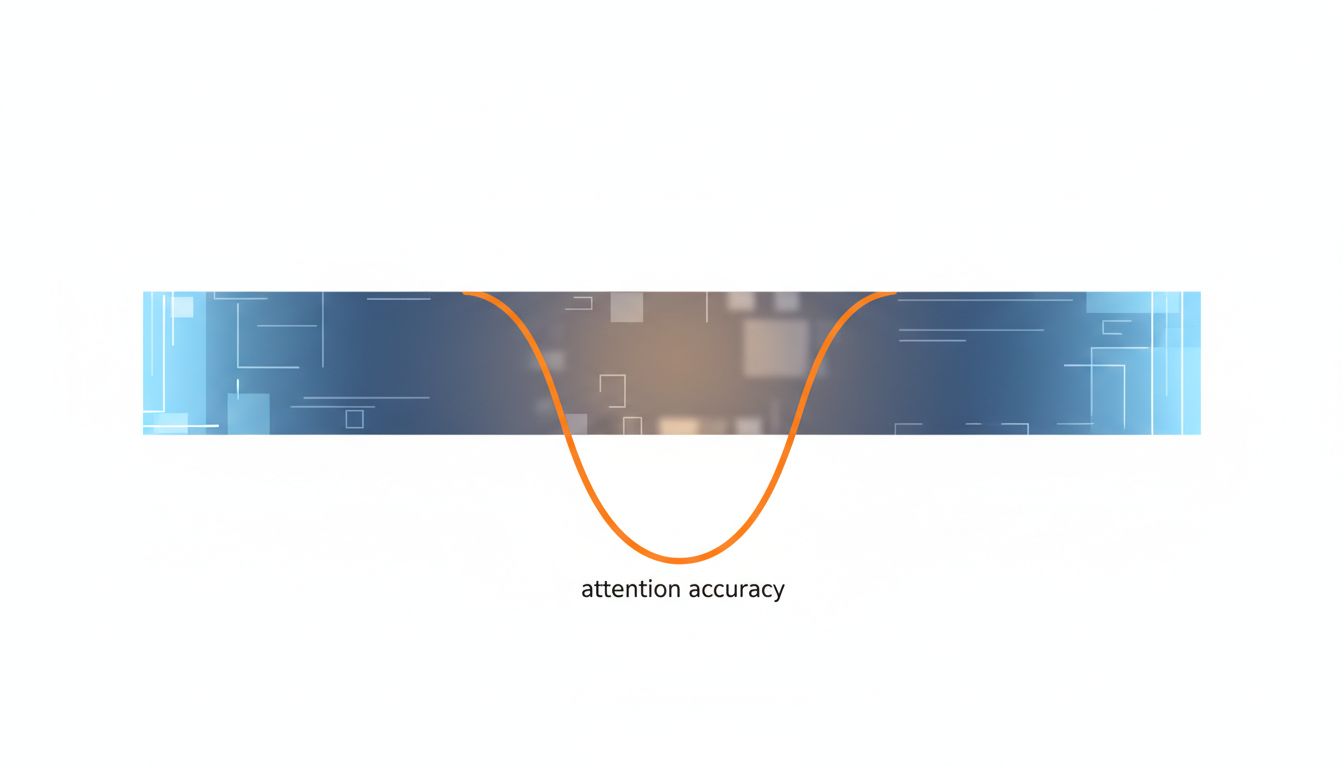
The Lost-in-the-Middle Problem
In 2023, researchers at Stanford and UC Berkeley published a paper called “Lost in the Middle: How Language Models Use Long Contexts.” The finding was uncomfortable: models using long contexts performed substantially better when the relevant information appeared at the beginning or end of the context, and significantly worse when it was buried in the middle.
The researchers tested this specifically by placing key facts at different positions within long documents and measuring retrieval accuracy. The performance curve was U-shaped: strong at both ends, weak in the middle. For a 20-document retrieval task, accuracy at the beginning or end position was roughly twice what it was in the middle positions.
This isn’t a quirk of one model. It reflects something about how attention training works. Models see the beginning of sequences more often during training (because short sequences are more common), and they learn to weight recency because it’s often predictive. The middle of a very long context is, in a real sense, harder to attend to.
Practically, this means if you’re stuffing 80,000 tokens of documentation into a context and asking a question, the answer to that question had better not live on page 40. If it does, you’re relying on the model to do something it demonstrably struggles with.
Tokens Are Not a Uniform Currency
A token is roughly 0.75 words in English, but that ratio shifts significantly with code, structured data, and non-English text. Python code, for example, tends to tokenize somewhat efficiently because reserved words and common patterns appear frequently in the training corpus and get compressed into single tokens. JSON with long key names tokenizes poorly. Whitespace-heavy formats can burn tokens fast.
This matters when you’re thinking about what fits in a 100,000-token window. A typical English novel runs around 90,000-100,000 words, which is roughly 120,000-135,000 tokens. You can fit most novels in Claude’s context window, but not quite all. A large codebase is a different story: a modest React application with 50 files might total 15,000 lines of code, which could easily exceed 100,000 tokens depending on formatting.
More importantly, the quality of the model’s output degrades before you hit the token limit. You don’t get sharp, accurate reasoning up to token 99,999 and then a cliff at token 100,000. Performance on complex reasoning tasks tends to get noisier as context length grows, even within the supported range.
What the Model “Remembers” vs. What It Can Retrieve
There’s a distinction worth drawing between retention and retrieval. A long context window doesn’t give the model persistent memory in any meaningful sense. It gives the model a very long working memory for a single inference call. Once that call ends, nothing persists. The next conversation starts fresh.
Within a single call, the model can retrieve information from anywhere in the context, but its ability to reason across multiple pieces of information from different parts of a long context is limited. Ask it to summarize a document and it’ll do well. Ask it to find a specific fact and it’ll generally succeed, especially if the fact is near the beginning or end. Ask it to synthesize an argument that requires connecting a point from token 5,000 with a point from token 60,000, and you’re asking it to do something that genuinely strains the architecture.
This is why retrieval-augmented generation, where you use embeddings to pull the most relevant chunks into the context rather than dumping everything in, often outperforms naive long-context approaches for knowledge-intensive tasks. (The tradeoffs there are worth their own treatment, but embeddings are doing more work in your stack than you might realize.) A focused 4,000-token context with exactly the right information frequently beats a 50,000-token context where the right information is scattered.
The Cost Side Is Not Trivial
API pricing for frontier models is structured around tokens, but long-context inference isn’t just 10x the cost of 1/10th the context. The quadratic attention cost means providers absorb disproportionately higher compute costs at long contexts, and pricing reflects this. Anthropic, OpenAI, and Google all charge more per token (or offer worse effective rates) for long-context tiers.
For production applications, this creates real architectural decisions. If you’re building a legal document analysis tool and you’re tempted to just shove entire contracts into context for every query, the per-query cost will compound fast. The smarter approach is usually to preprocess documents, extract structure, and only bring in full text when the query actually requires it. That’s more engineering work, but it’s the kind of work that separates systems that are cost-viable at scale from ones that aren’t. The cheapest cloud option rarely ends up cheapest, and the same logic applies to naively maxing out context windows.
Where Long Context Actually Wins
None of this means large context windows aren’t useful. They’re genuinely valuable in specific scenarios, and it’s worth being precise about which ones.
Code review and refactoring across a full file or module benefit significantly from long context. The model can track variable names, function signatures, and architectural patterns across thousands of lines without you having to carefully manage what it knows. For codebases that fit in context, this is a meaningful improvement over older approaches.
Multi-document synthesis, where you want a model to read several related documents and produce a coherent summary or comparison, works well when the documents fit comfortably within context and the synthesis task doesn’t require the model to reason about dozens of cross-document connections simultaneously.
Conversational memory within a session is perhaps the clearest win. Long-context models can maintain coherent conversations across hours of back-and-forth without losing track of what was established early in the conversation. This is something users notice and appreciate directly.
The common thread in these use cases: the task calls for breadth of access more than depth of reasoning across distant parts of the context. When you need the model to hold a lot, long context helps. When you need it to reason hard about connections across a lot, you’re often better off being selective.
What This Means
A 100,000-token context window is not a search index and it’s not persistent memory. It’s a very large working buffer that a model processes via quadratic attention, with measurable performance degradation for information in the middle, at a cost that scales faster than linearly.
That’s still useful, but it’s useful in particular ways. If you’re building on top of these models, the key design question isn’t “how much can I fit in context” but “what actually needs to be in context for this specific task.” Often the answer is much less than the maximum. A well-curated 8,000-token context, built from retrieved chunks relevant to the query, will outperform a lazy 80,000-token dump on most reasoning-intensive tasks, and it’ll do it cheaper.
The architectural ceiling keeps rising. Models will handle longer contexts more reliably as training and infrastructure improve. But the fundamental tradeoffs, attention cost, positional bias, the distinction between holding information and reasoning across it, aren’t going away. Understanding them is how you build systems that actually work rather than systems that merely fit.





