The Simple Version
Servers cost the same whether they’re handling ten thousand requests or zero. Most apps only need their full capacity for a small slice of every day, but they pay for all twenty-four hours regardless.
Why Servers Can’t Sleep
Imagine a restaurant that has to staff forty cooks from midnight to noon, just because the lunch rush from noon to two is brutal. The cooks still get paid for twelve hours. The food still costs the same. The only thing that changes is how much of that capacity actually gets used.
This is the core problem of server infrastructure, and it’s been the dominant cost structure of the internet since servers moved into data centers. You provision for your worst case. You pay for your worst case. You run at a fraction of that capacity almost all the time.
The specifics vary by application, but the pattern is nearly universal. Consumer apps peak in evenings. Business software peaks mid-morning on weekdays. News sites spike whenever something happens, then go quiet. The gap between average load and peak load is typically enormous, often five-to-one or ten-to-one for apps with any kind of usage pattern tied to human behavior.
The Three Ways Companies Have Tried to Solve This
The traditional response was to simply over-provision and accept the waste. Buy servers for the peak. Watch them sit idle otherwise. This is still what many companies do, particularly those running their own data centers, because the alternative requires accepting complexity.
The second approach is manual scaling: a human (or a scheduled script) turns on more servers before an expected peak and turns them off afterward. This works reasonably well for predictable patterns. A company that knows it spikes every weekday at 10am can schedule its scaling accordingly. It breaks down for unpredictable traffic, which is exactly when you most need it to work.
The third approach, which cloud providers have been selling aggressively for over a decade, is auto-scaling: let the infrastructure respond automatically to load. AWS, Google Cloud, and Azure all offer versions of this. Spin up new instances when CPU climbs above a threshold, spin them down when load drops.
Auto-scaling sounds like the obvious answer. It is not a complete answer. Servers take time to boot. Applications take time to initialize. If you get a sudden spike, the new capacity often comes online after the spike has already passed or, worse, after users have already bounced. You end up provisioning a baseline high enough to handle the ramp-up time, which brings you back to paying for idle capacity.
What Serverless Actually Promised
The serverless model, which AWS Lambda popularized when it launched in 2014, was designed to attack this problem directly. Instead of running a server that waits for requests, you write a function that only exists for the duration of a single request. No request, no cost. Pure pay-per-use.
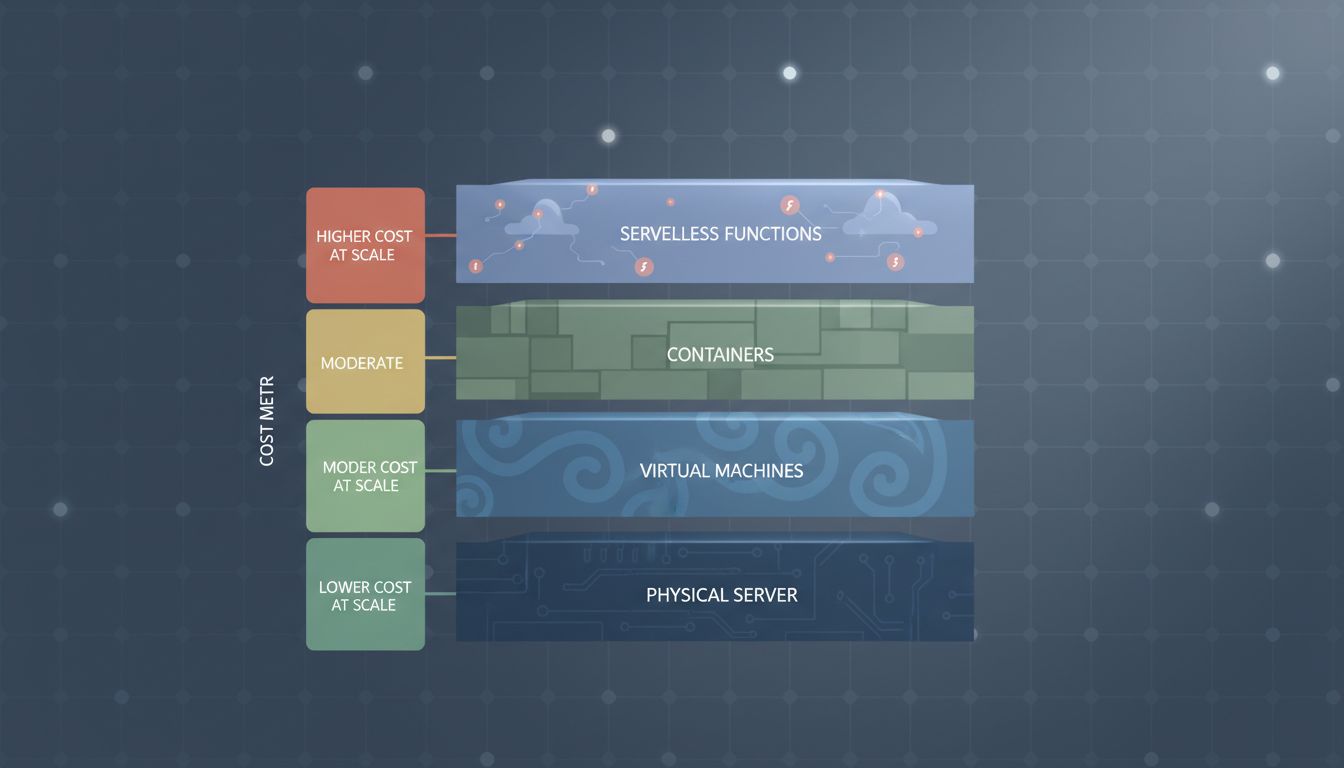
This was a genuine architectural shift for certain workloads. For sporadic, event-driven tasks, background jobs, and APIs with highly variable traffic, serverless can cut infrastructure costs dramatically. If your app gets five requests a day, you pay for five requests worth of compute.
But serverless has its own economics that bite you at scale. The pricing models that make it cheap at low volume become surprisingly expensive as you grow. Cold starts, which are the latency penalties when a function spins up from scratch, can be severe enough that high-traffic applications have to keep functions artificially warm, which means paying to run them even when there’s nothing to process. You’ve reinvented idle capacity by another name.
There’s also the matter of what serverless can’t easily handle: long-running connections, stateful workloads, WebSockets, streaming. The model fits a specific shape of application. Most production systems don’t fit that shape entirely.
The Honest Accounting
The real cost of the idle-server problem isn’t just wasted compute. It’s the decisions that get made to avoid wasted compute.
Engineering teams spend significant time on capacity planning, load testing, and scaling configuration, work that produces no features and no user value. Startups often under-provision to save money, then scramble when they get unexpected traffic, which is precisely when they can least afford an outage. Premature optimization of the infrastructure layer kills more promising products than bad product decisions do.
The cloud providers have a direct financial interest in the complexity of this problem. A customer who fully understands their utilization rates and optimizes accordingly is a less profitable customer. The opacity of cloud billing, with its dozens of pricing dimensions, reserved instances, spot instances, and savings plans, isn’t accidental. It’s a feature of the business model.
The most pragmatic framework for thinking about this: idle capacity is only waste if you’re paying marginal cost for it. Reserved instances and committed use discounts reduce the per-hour cost of a server significantly, often thirty to forty percent compared to on-demand pricing. If you know you’ll run a server for a year, committing to it makes the idle hours cheaper. The waste doesn’t disappear, but the unit economics change enough to matter.
What This Means If You’re Building Something
A few things are true regardless of your scale.
Understanding your traffic shape is worth the hour it takes. Most teams have a vague sense that traffic is higher during the day, but have never actually graphed average load versus peak load over a month. The ratio is almost always surprising, and it’s the single most important number for infrastructure decisions.
The right architecture depends on that ratio. A highly spiky application with long idle periods is a better candidate for serverless or aggressive auto-scaling. A relatively flat traffic pattern is a better candidate for reserved instances and right-sized fixed capacity.
And the eleven minutes figure in the headline, while illustrative rather than universal, reflects something real: the gap between what most applications need most of the time and what they provision for is much larger than engineers intuitively believe. Closing that gap is less about finding the right cloud product and more about measuring honestly before buying anything.