
AI & Software
Why Longer System Prompts Usually Make LLMs Worse
More instructions feel like more control. They're often the opposite. Here's what actually happens when you pile rules into a system prompt.
Inside the algorithms, tools, and systems powering the AI revolution and modern software.
More instructions feel like more control. They're often the opposite. Here's what actually happens when you pile rules into a system prompt.

You write prompts like instructions. The model reads them like a probability problem. That gap explains a lot of bad outputs.

AI writing tools are getting genuinely impressive. That's exactly why they're quietly degrading the cognitive skill they're supposed to support.

Softmax converts raw model scores into probabilities. But what it actually does to those scores in the process is stranger and more consequential than most explanations let on.

A race condition that vanished under a debugger taught one team something most engineers learn too late: observation changes what you're measuring.

Your LLM can technically read a novel. Whether it actually processes that novel is a different question entirely.
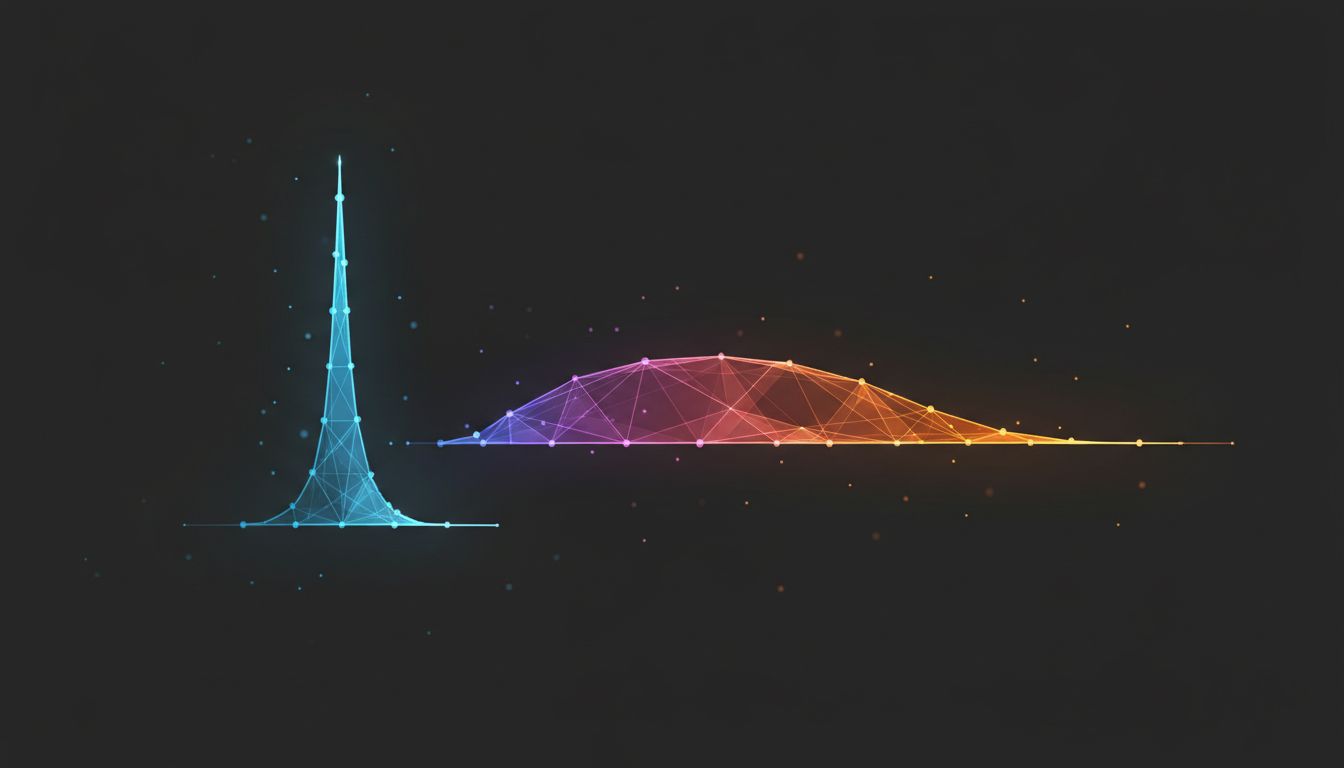
Most developers treat temperature as a creativity dial. It's actually reshaping token probabilities in ways that compound across every word the model generates.

Code-generating AI models predict text that looks like working code. That's not the same as knowing whether the code works.

A medical AI startup learned the hard way that high confidence scores don't predict accuracy. They predict familiarity. That distinction costs lives.
Writing code is a creative act with a blank canvas. Debugging production is forensic work with half the evidence missing and a clock running.
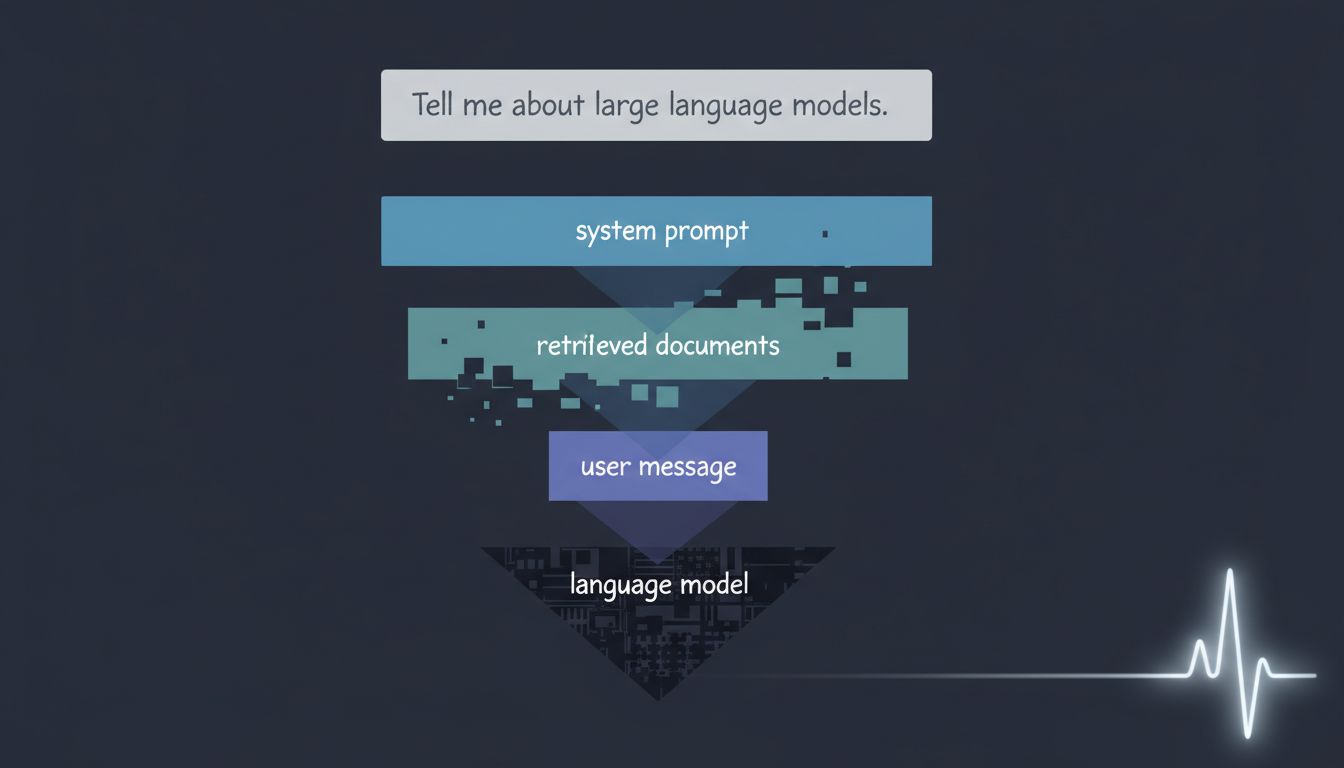
Between your words and the model's attention sits a layer most users never see. Understanding it changes how you work with AI.
A team ships an AI-assisted feature, the tests pass, and a silent data corruption bug lives in production for weeks. Here's the structural reason this keeps happening.
Asking an LLM to 'think step by step' doesn't make it reason. It makes it generate text that looks like reasoning. The difference matters more than most developers realize.

The attention mechanism that makes LLMs powerful also makes them scale quadratically with context length. Here's what that means for your infrastructure bill.

Longer prompts should mean better answers. Often they produce worse ones. Here's the actual mechanism behind context window degradation.

Bigger AI models get the headlines, but the real performance gains often come from making models smaller. Here's why constraints produce better reasoning.

Meta's decision to release Llama models at multiple sizes taught the industry something counterintuitive: smaller, focused models frequently outperform their giant siblings in real deployments.

A fintech team shipped faster than ever with AI assistance. Eighteen months later, nobody could explain what their own system did. Here's what happened.
Join thousands of readers who get our weekly breakdown of the most important stories in technology.
Free forever. Unsubscribe anytime.