
AI & Software
What an LLM Actually Does With Your Prompt First
Before a model writes a single word back to you, your prompt goes through a transformation you never see. Understanding it changes how you write prompts.
Inside the algorithms, tools, and systems powering the AI revolution and modern software.
Before a model writes a single word back to you, your prompt goes through a transformation you never see. Understanding it changes how you write prompts.

Adversarial inputs look dangerous. The prompts that actually break LLM applications look completely ordinary — and that's the whole problem.

When Air Street Capital's research team caught GPT-4 fabricating citations with perfect formatting, it exposed a problem that gets worse as models improve.

Over-engineered prompts often produce worse results than simple ones. Here's why, and what to do instead.

A legal tech company spent months optimizing prompts that the model never fully received. What they discovered changed how their entire engineering team thinks about context.
That bug that only appears in production isn't bad luck. It's a diagnostic. Here's what it's trying to tell you.
The skills behind good prompting aren't new. They're the same ones that make you a better writer, manager, and problem-solver.

The more capable the model, the more convincing its mistakes. This isn't a bug that will get patched. It's a structural feature of how these systems work.

Most people treat AI models like colleagues who remember context. They don't. Understanding why changes how you work with them.

The model hasn't changed. Your results have. Here's what's actually happening when your prompts start working.

Developers routinely conflate two distinct performance metrics, then wonder why their optimizations make things worse. The confusion is fundamental, not cosmetic.

Retrieval-Augmented Generation is genuinely useful, but most teams deploy it expecting it to solve something it was never designed to fix.

A correct bug fix can introduce new failures. Here's how that happens, why large codebases are especially vulnerable, and what the Knight Capital collapse teaches us about it.
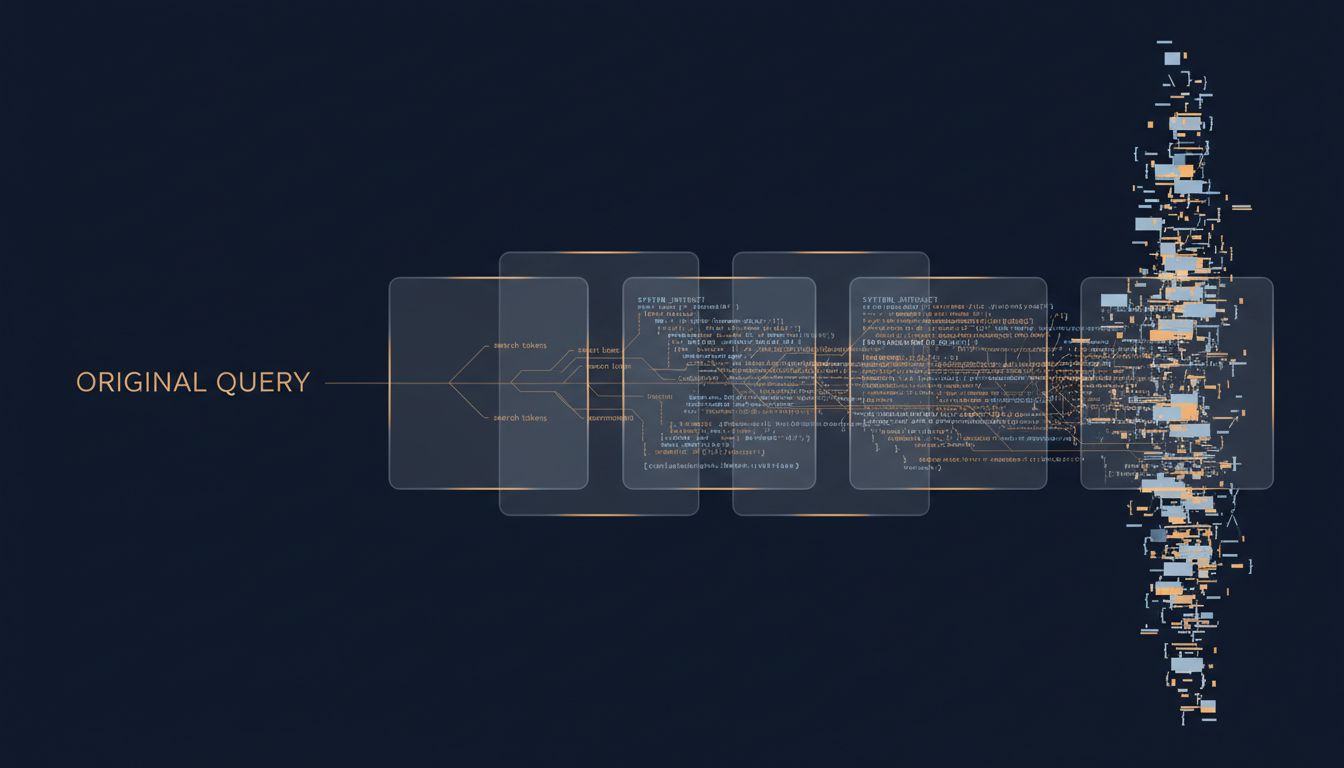
Between your text and the model's attention, a lot happens. Understanding that gap changes how you think about AI behavior entirely.
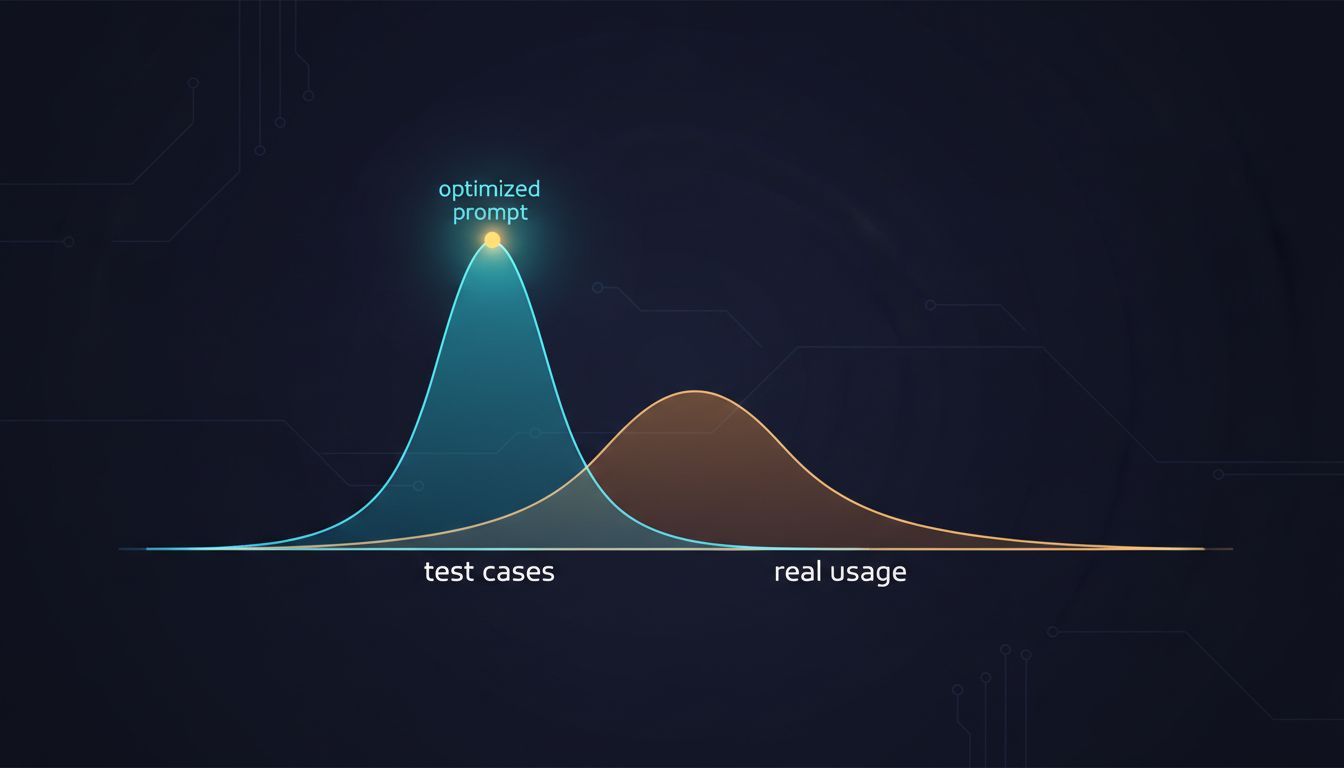
Most prompt engineering advice focuses on getting better outputs. That's the wrong goal. Here's what to optimize for instead.

Some bugs vanish the moment you try to find them. That's not bad luck — it's a structural property of complex systems. Here's what heisenbugs actually teach us.

Chain-of-thought prompting genuinely improves LLM reasoning, but not for the reasons most people assume. Here's the real mechanism.

Bigger AI models aren't always better. Smaller, specialized models are faster, cheaper, and often more accurate for the tasks that actually matter in production.
Join thousands of readers who get our weekly breakdown of the most important stories in technology.
Free forever. Unsubscribe anytime.